 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeMask: Synthetic Images with Dense Annotations Make Stronger Segmentation Models
Paper and Code

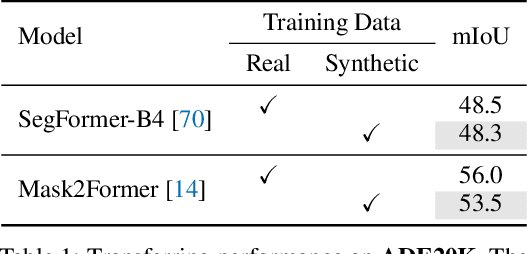
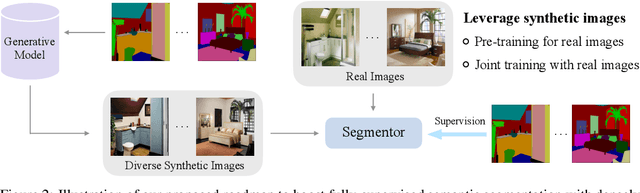

Semantic segmentation has witnessed tremendous progress due to the proposal of various advanced network architectures. However, they are extremely hungry for delicate annotations to train, and the acquisition is laborious and unaffordable. Therefore, we present FreeMask in this work, which resorts to synthetic images from generative models to ease the burden of both data collection and annotation procedures. Concretely, we first synthesize abundant training images conditioned on the semantic masks provided by realistic datasets. This yields extra well-aligned image-mask training pairs for semantic segmentation models. We surprisingly observe that, solely trained with synthetic images, we already achieve comparable performance with real ones (e.g., 48.3 vs. 48.5 mIoU on ADE20K, and 49.3 vs. 50.5 on COCO-Stuff). Then, we investigate the role of synthetic images by joint training with real images, or pre-training for real images. Meantime, we design a robust filtering principle to suppress incorrectly synthesized regions. In addition, we propose to inequally treat different semantic masks to prioritize those harder ones and sample more corresponding synthetic images for them. As a result, either jointly trained or pre-trained with our filtered and re-sampled synthesized images, segmentation models can be greatly enhanced, e.g., from 48.7 to 52.0 on ADE20K. Code is available at https://github.com/LiheYoung/FreeMask.