 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Lightweight Clustering Framework for Unsupervised Semantic Segmentation
Paper and Code
Nov 30, 2023
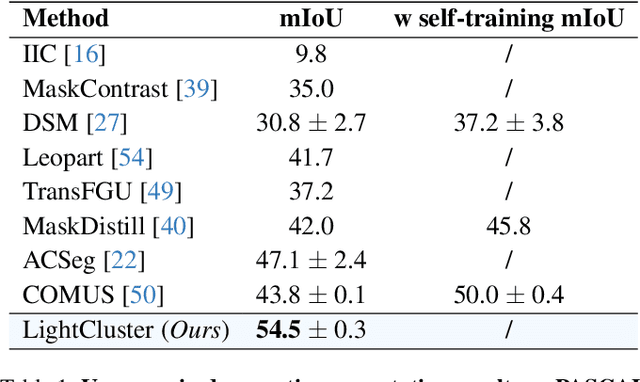
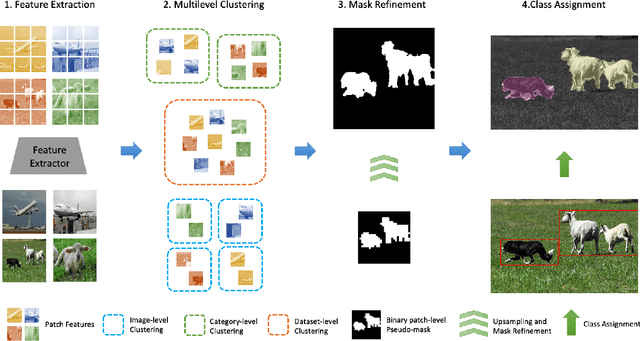
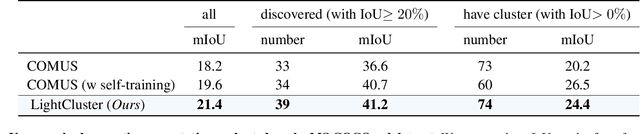
Unsupervised semantic segmentation aims to label each pixel of an image to a corresponding class without the use of annotated data. It is a widely researched area as obtaining labeled datasets are expensive. While previous works in the field demonstrated a gradual improvement in segmentation performance, most of them required neural network training. This made segmentation equally expensive, especially when dealing with large-scale datasets. We thereby propose a lightweight clustering framework for unsupervised semantic segmentation. Attention features of the self-supervised vision transformer exhibit strong foreground-background differentiability. By clustering these features into a small number of clusters, we could separate foreground and background image patches into distinct groupings. In our clustering framework, we first obtain attention features from the self-supervised vision transformer. Then we extract Dataset-level, Category-level and Image-level masks by clustering features within the same dataset, category and image. We further ensure multilevel clustering consistency across the three levels and this allows us to extract patch-level binary pseudo-masks. Finally, the pseudo-mask is upsampled, refined and class assignment is performed according to the CLS token of object regions. Our framework demonstrates great promise in unsupervised semantic segmentation and achieves state-of-the-art results on PASCAL VOC and MS COCO datasets.