 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinkSound: Chain-of-Thought Reasoning in Multimodal Large Language Models for Audio Generation and Editing
Jun 26, 2025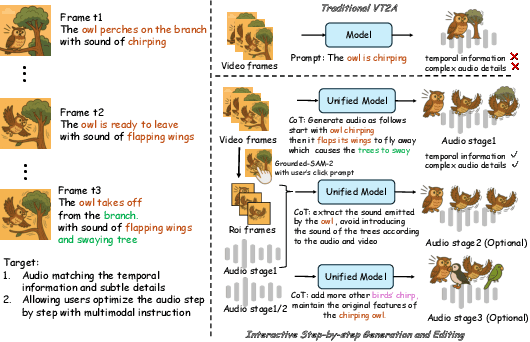
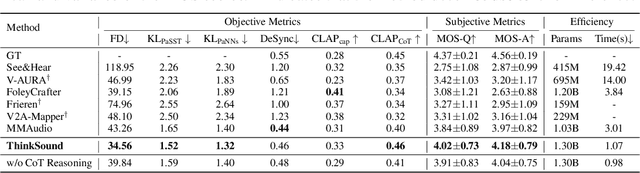
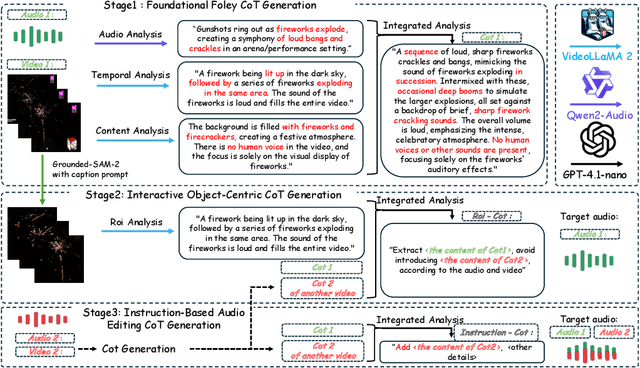
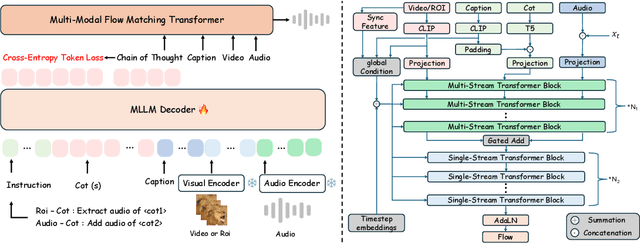
While end-to-end video-to-audio generation has greatly improved, producing high-fidelity audio that authentically captures the nuances of visual content remains challenging. Like professionals in the creative industries, such generation requires sophisticated reasoning about items such as visual dynamics, acoustic environments, and temporal relationships. We present \textbf{ThinkSound}, a novel framework that leverages Chain-of-Thought (CoT) reasoning to enable stepwise, interactive audio generation and editing for videos. Our approach decomposes the process into three complementary stages: foundational foley generation that creates semantically coherent soundscapes, interactive object-centric refinement through precise user interactions, and targeted editing guided by natural language instructions. At each stage, a multimodal large language model generates contextually aligned CoT reasoning that guides a unified audio foundation model. Furthermore, we introduce \textbf{AudioCoT}, a comprehensive dataset with structured reasoning annotations that establishes connections between visual content, textual descriptions, and sound synthesis. Experiments demonstrate that ThinkSound achieves state-of-the-art performance in video-to-audio generation across both audio metrics and CoT metrics and excels in out-of-distribution Movie Gen Audio benchmark. The demo page is available at https://ThinkSound-Demo.github.io.
Depth Anything with Any Prior
May 15, 2025This work presents Prior Depth Anything, a framework that combines incomplete but precise metric information in depth measurement with relative but complete geometric structures in depth prediction, generating accurate, dense, and detailed metric depth maps for any scene. To this end, we design a coarse-to-fine pipeline to progressively integrate the two complementary depth sources. First, we introduce pixel-level metric alignment and distance-aware weighting to pre-fill diverse metric priors by explicitly using depth prediction. It effectively narrows the domain gap between prior patterns, enhancing generalization across varying scenarios. Second, we develop a conditioned monocular depth estimation (MDE) model to refine the inherent noise of depth priors. By conditioning on the normalized pre-filled prior and prediction, the model further implicitly merges the two complementary depth sources. Our model showcases impressive zero-shot generalization across depth completion, super-resolution, and inpainting over 7 real-world datasets, matching or even surpassing previous task-specific methods. More importantly, it performs well on challenging, unseen mixed priors and enables test-time improvements by switching prediction models, providing a flexible accuracy-efficiency trade-off while evolving with advancements in MDE models.
FlashAudio: Rectified Flows for Fast and High-Fidelity Text-to-Audio Generation
Oct 16, 2024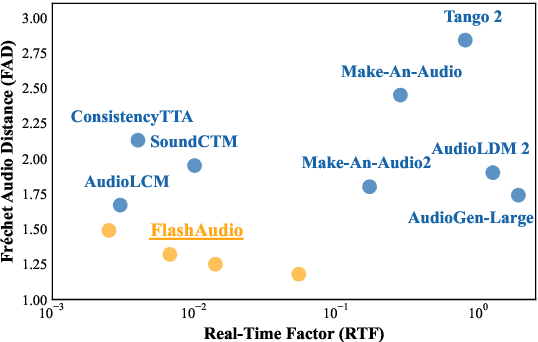


Recent advancements in latent diffusion models (LDMs) have markedly enhanced text-to-audio generation, yet their iterative sampling processes impose substantial computational demands, limiting practical deployment. While recent methods utilizing consistency-based distillation aim to achieve few-step or single-step inference, their one-step performance is constrained by curved trajectories, preventing them from surpassing traditional diffusion models. In this work, we introduce FlashAudio with rectified flows to learn straight flow for fast simulation. To alleviate the inefficient timesteps allocation and suboptimal distribution of noise, FlashAudio optimizes the time distribution of rectified flow with Bifocal Samplers and proposes immiscible flow to minimize the total distance of data-noise pairs in a batch vias assignment. Furthermore, to address the amplified accumulation error caused by the classifier-free guidance (CFG), we propose Anchored Optimization, which refines the guidance scale by anchoring it to a reference trajectory. Experimental results on text-to-audio generation demonstrate that FlashAudio's one-step generation performance surpasses the diffusion-based models with hundreds of sampling steps on audio quality and enables a sampling speed of 400x faster than real-time on a single NVIDIA 4090Ti GPU.
GTSinger: A Global Multi-Technique Singing Corpus with Realistic Music Scores for All Singing Tasks
Sep 26, 2024



The scarcity of high-quality and multi-task singing datasets significantly hinders the development of diverse controllable and personalized singing tasks, as existing singing datasets suffer from low quality, limited diversity of languages and singers, absence of multi-technique information and realistic music scores, and poor task suitability. To tackle these problems, we present GTSinger, a large global, multi-technique, free-to-use, high-quality singing corpus with realistic music scores, designed for all singing tasks, along with its benchmarks. Particularly, (1) we collect 80.59 hours of high-quality singing voices, forming the largest recorded singing dataset; (2) 20 professional singers across nine widely spoken languages offer diverse timbres and styles; (3) we provide controlled comparison and phoneme-level annotations of six commonly used singing techniques, helping technique modeling and control; (4) GTSinger offers realistic music scores, assisting real-world musical composition; (5) singing voices are accompanied by manual phoneme-to-audio alignments, global style labels, and 16.16 hours of paired speech for various singing tasks. Moreover, to facilitate the use of GTSinger, we conduct four benchmark experiments: technique-controllable singing voice synthesis, technique recognition, style transfer, and speech-to-singing conversion. The corpus and demos can be found at http://gtsinger.github.io. We provide the dataset and the code for processing data and conducting benchmarks at https://huggingface.co/datasets/GTSinger/GTSinger and https://github.com/GTSinger/GTSinger.
MEDIC: Zero-shot Music Editing with Disentangled Inversion Control
Jul 18, 2024Text-guided diffusion models catalyze a paradigm shift in audio generation, facilitating the adaptability of source audio to conform to specific textual prompts. Recent advancements introduce inversion techniques, like DDIM inversion, to zero-shot editing, exploiting pre-trained diffusion models for audio modification. Nonetheless, our investigation exposes that DDIM inversion suffers from an accumulation of errors across each diffusion step, undermining its efficacy. And the lack of attention control hinders the fine-grained manipulations of music. To counteract these limitations, we introduce the \textit{Disentangled Inversion} technique, which is designed to disentangle the diffusion process into triple branches, thereby magnifying their individual capabilities for both precise editing and preservation. Furthermore, we propose the \textit{Harmonized Attention Control} framework, which unifies the mutual self-attention and cross-attention with an additional Harmonic Branch to achieve the desired composition and structural information in the target music. Collectively, these innovations comprise the \textit{Disentangled Inversion Control (DIC)} framework, enabling accurate music editing whilst safeguarding structural integrity. To benchmark audio editing efficacy, we introduce \textit{ZoME-Bench}, a comprehensive music editing benchmark hosting 1,100 samples spread across 10 distinct editing categories, which facilitates both zero-shot and instruction-based music editing tasks. Our method demonstrates unparalleled performance in edit fidelity and essential content preservation, outperforming contemporary state-of-the-art inversion techniques.
AudioLCM: Text-to-Audio Generation with Latent Consistency Models
Jun 01, 2024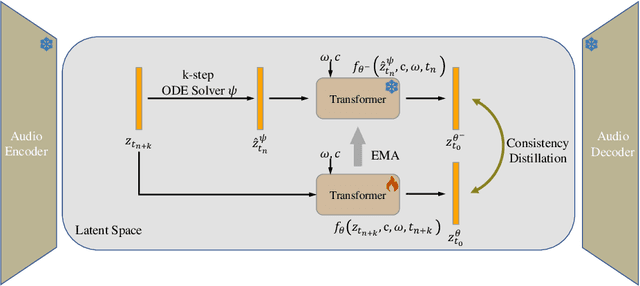
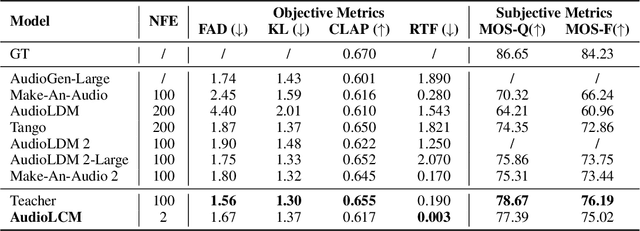
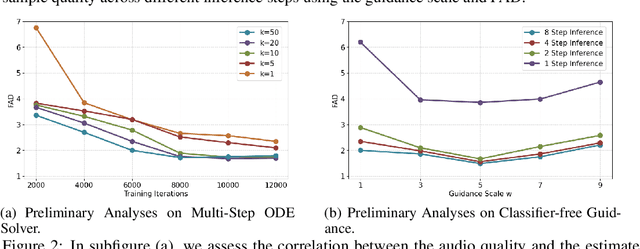
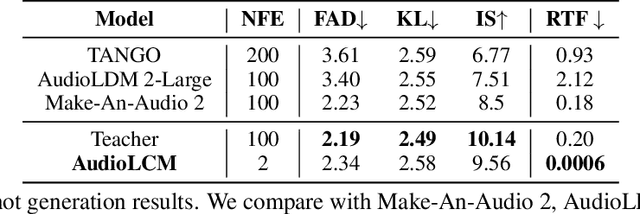
Recent advancements in Latent Diffusion Models (LDMs) have propelled them to the forefront of various generative tasks. However, their iterative sampling process poses a significant computational burden, resulting in slow generation speeds and limiting their application in text-to-audio generation deployment. In this work, we introduce AudioLCM, a novel consistency-based model tailored for efficient and high-quality text-to-audio generation. AudioLCM integrates Consistency Models into the generation process, facilitating rapid inference through a mapping from any point at any time step to the trajectory's initial point. To overcome the convergence issue inherent in LDMs with reduced sample iterations, we propose the Guided Latent Consistency Distillation with a multi-step Ordinary Differential Equation (ODE) solver. This innovation shortens the time schedule from thousands to dozens of steps while maintaining sample quality, thereby achieving fast convergence and high-quality generation. Furthermore, to optimize the performance of transformer-based neural network architectures, we integrate the advanced techniques pioneered by LLaMA into the foundational framework of transformers. This architecture supports stable and efficient training, ensuring robust performance in text-to-audio synthesis. Experimental results on text-to-sound generation and text-to-music synthesis tasks demonstrate that AudioLCM needs only 2 iterations to synthesize high-fidelity audios, while it maintains sample quality competitive with state-of-the-art models using hundreds of steps. AudioLCM enables a sampling speed of 333x faster than real-time on a single NVIDIA 4090Ti GPU, making generative models practically applicable to text-to-audio generation deployment. Our extensive preliminary analysis shows that each design in AudioLCM is effective.
Graph Oracle Models, Lower Bounds, and Gaps for Parallel Stochastic Optimization
Jul 31, 2018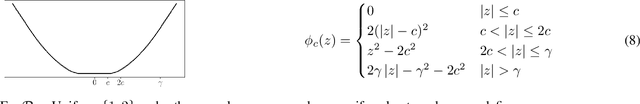
We suggest a general oracle-based framework that captures different parallel stochastic optimization settings described by a dependency graph, and derive generic lower bounds in terms of this graph. We then use the framework and derive lower bounds for several specific parallel optimization settings, including delayed updates and parallel processing with intermittent communication. We highlight gaps between lower and upper bounds on the oracle complexity, and cases where the "natural" algorithms are not known to be optimal.
Distributed Stochastic Multi-Task Learning with Graph Regularization
Feb 11, 2018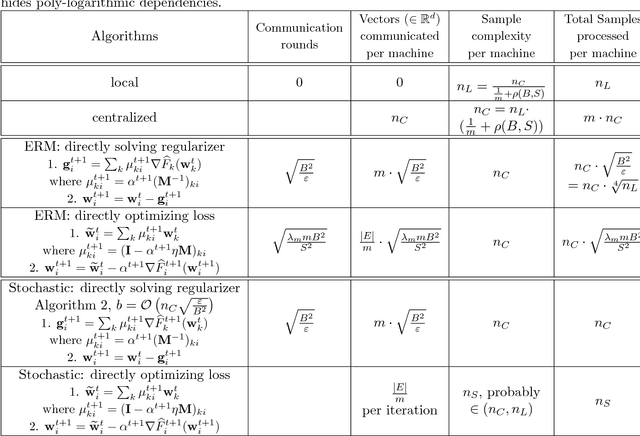

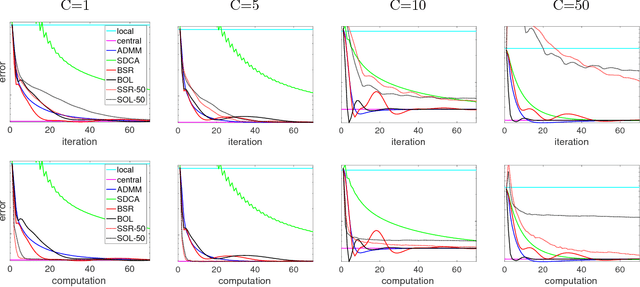

We propose methods for distributed graph-based multi-task learning that are based on weighted averaging of messages from other machines. Uniform averaging or diminishing stepsize in these methods would yield consensus (single task) learning. We show how simply skewing the averaging weights or controlling the stepsize allows learning different, but related, tasks on the different machines.
Rate Optimal Estimation and Confidence Intervals for High-dimensional Regression with Missing Covariates
Nov 03, 2017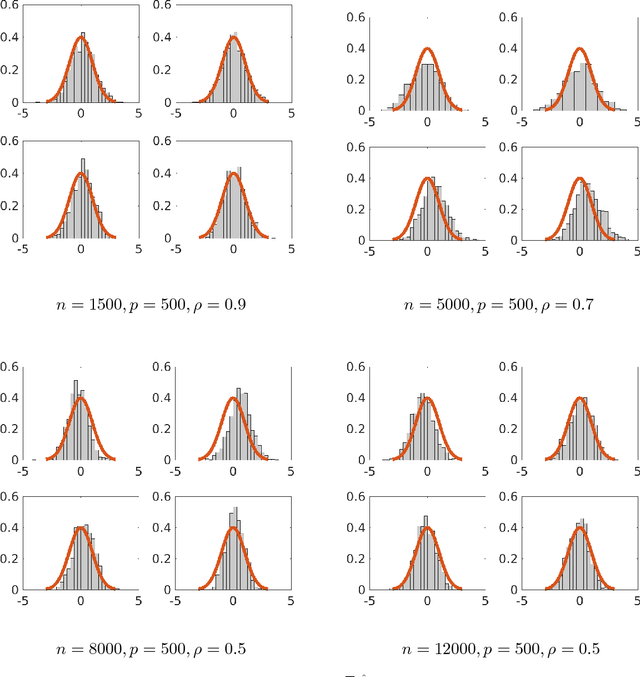
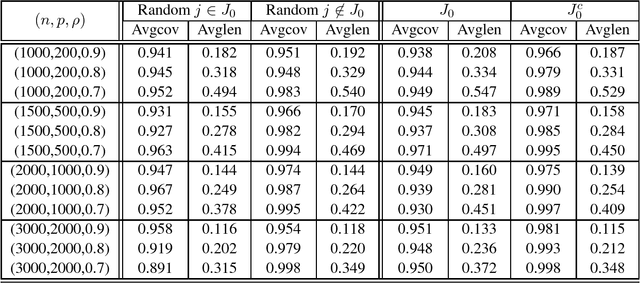

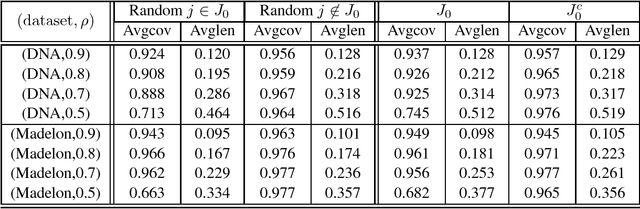
Although a majority of the theoretical literature in high-dimensional statistics has focused on settings which involve fully-observed data, settings with missing values and corruptions are common in practice. We consider the problems of estimation and of constructing component-wise confidence intervals in a sparse high-dimensional linear regression model when some covariates of the design matrix are missing completely at random. We analyze a variant of the Dantzig selector [9] for estimating the regression model and we use a de-biasing argument to construct component-wise confidence intervals. Our first main result is to establish upper bounds on the estimation error as a function of the model parameters (the sparsity level s, the expected fraction of observed covariates $\rho_*$, and a measure of the signal strength $\|\beta^*\|_2$). We find that even in an idealized setting where the covariates are assumed to be missing completely at random, somewhat surprisingly and in contrast to the fully-observed setting, there is a dichotomy in the dependence on model parameters and much faster rates are obtained if the covariance matrix of the random design is known. To study this issue further, our second main contribution is to provide lower bounds on the estimation error showing that this discrepancy in rates is unavoidable in a minimax sense. We then consider the problem of high-dimensional inference in the presence of missing data. We construct and analyze confidence intervals using a de-biased estimator. In the presence of missing data, inference is complicated by the fact that the de-biasing matrix is correlated with the pilot estimator and this necessitates the design of a new estimator and a novel analysis. We also complement our mathematical study with extensive simulations on synthetic and semi-synthetic data that show the accuracy of our asymptotic predictions for finite sample sizes.
Parallel Bayesian Global Optimization of Expensive Functions
Nov 01, 2017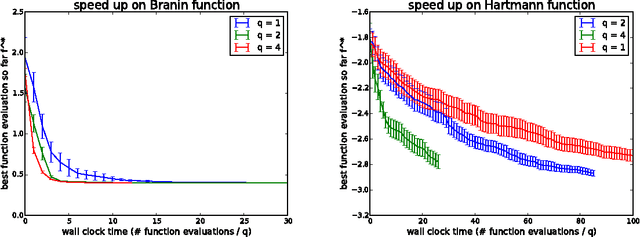
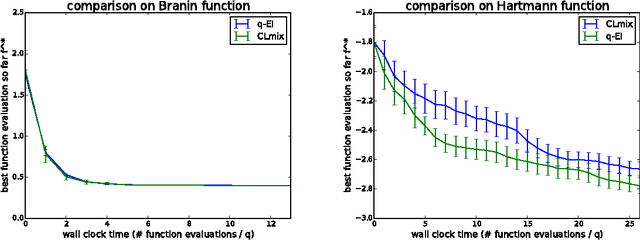
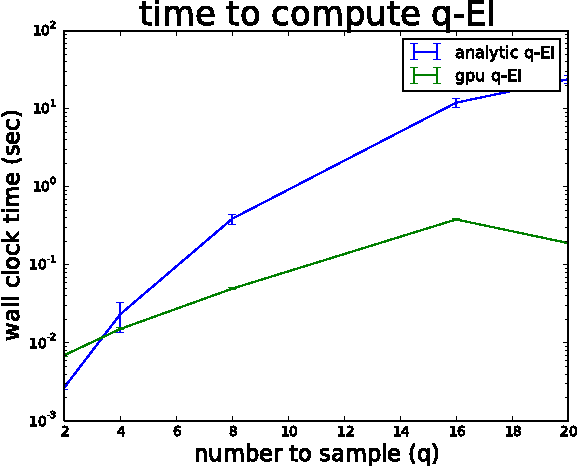
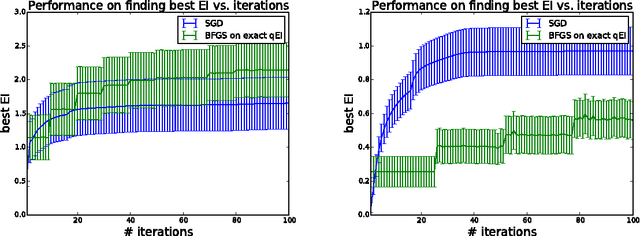
We consider parallel global optimization of derivative-free expensive-to-evaluate functions, and propose an efficient method based on stochastic approximation for implementing a conceptual Bayesian optimization algorithm proposed by Ginsbourger et al. (2007). To accomplish this, we use infinitessimal perturbation analysis (IPA) to construct a stochastic gradient estimator and show that this estimator is unbiased. We also show that the stochastic gradient ascent algorithm using the constructed gradient estimator converges to a stationary point of the q-EI surface, and therefore, as the number of multiple starts of the gradient ascent algorithm and the number of steps for each start grow large, the one-step Bayes optimal set of points is recovered. We show in numerical experiments that our method for maximizing the q-EI is faster than methods based on closed-form evaluation using high-dimensional integration, when considering many parallel function evaluations, and is comparable in speed when considering few. We also show that the resulting one-step Bayes optimal algorithm for parallel global optimization finds high quality solutions with fewer evaluations that a heuristic based on approximately maximizing the q-EI. A high quality open source implementation of this algorithm is available in the open source Metrics Optimization Engine (MOE).