 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeamCKMDiff: Beam-Aware Channel Knowledge Map Construction via Diffusion Transformer
Jan 15, 2026Channel knowledge map (CKM) is emerging as a critical enabler for environment-aware 6G networks, offering a site-specific database to significantly reduce pilot overhead. However, existing CKM construction methods typically rely on sparse sampling measurements and are restricted to either omnidirectional maps or discrete codebooks, hindering the exploitation of beamforming gain. To address these limitations, we propose BeamCKMDiff, a generative framework for constructing high-fidelity CKMs conditioned on arbitrary continuous beamforming vectors without site-specific sampling. Specifically, we incorporate a novel adaptive layer normalization (adaLN) mechanism into the noise prediction network of the Diffusion Transformer (DiT). This mechanism injects continuous beam embeddings as {global control parameters}, effectively steering the generative process to capture the complex coupling between beam patterns and environmental geometries. Simulation results demonstrate that BeamCKMDiff significantly outperforms state-of-the-art baselines, achieving superior reconstruction accuracy in capturing main lobes and side lobes.
BayesRAG: Probabilistic Mutual Evidence Corroboration for Multimodal Retrieval-Augmented Generation
Jan 12, 2026Retrieval-Augmented Generation (RAG) has become a pivotal paradigm for Large Language Models (LLMs), yet current approaches struggle with visually rich documents by treating text and images as isolated retrieval targets. Existing methods relying solely on cosine similarity often fail to capture the semantic reinforcement provided by cross-modal alignment and layout-induced coherence. To address these limitations, we propose BayesRAG, a novel multimodal retrieval framework grounded in Bayesian inference and Dempster-Shafer evidence theory. Unlike traditional approaches that rank candidates strictly by similarity, BayesRAG models the intrinsic consistency of retrieved candidates across modalities as probabilistic evidence to refine retrieval confidence. Specifically, our method computes the posterior association probability for combinations of multimodal retrieval results, prioritizing text-image pairs that mutually corroborate each other in terms of both semantics and layout. Extensive experiments demonstrate that BayesRAG significantly outperforms state-of-the-art (SOTA) methods on challenging multimodal benchmarks. This study establishes a new paradigm for multimodal retrieval fusion that effectively resolves the isolation of heterogeneous modalities through an evidence fusion mechanism and enhances the robustness of retrieval outcomes. Our code is available at https://github.com/TioeAre/BayesRAG.
FocalOrder: Focal Preference Optimization for Reading Order Detection
Jan 12, 2026Reading order detection is the foundation of document understanding. Most existing methods rely on uniform supervision, implicitly assuming a constant difficulty distribution across layout regions. In this work, we challenge this assumption by revealing a critical flaw: \textbf{Positional Disparity}, a phenomenon where models demonstrate mastery over the deterministic start and end regions but suffer a performance collapse in the complex intermediate sections. This degradation arises because standard training allows the massive volume of easy patterns to drown out the learning signals from difficult layouts. To address this, we propose \textbf{FocalOrder}, a framework driven by \textbf{Focal Preference Optimization (FPO)}. Specifically, FocalOrder employs adaptive difficulty discovery with exponential moving average mechanism to dynamically pinpoint hard-to-learn transitions, while introducing a difficulty-calibrated pairwise ranking objective to enforce global logical consistency. Extensive experiments demonstrate that FocalOrder establishes new state-of-the-art results on OmniDocBench v1.0 and Comp-HRDoc. Our compact model not only outperforms competitive specialized baselines but also significantly surpasses large-scale general VLMs. These results demonstrate that aligning the optimization with intrinsic structural ambiguity of documents is critical for mastering complex document structures.
PARL: Position-Aware Relation Learning Network for Document Layout Analysis
Jan 12, 2026Document layout analysis aims to detect and categorize structural elements (e.g., titles, tables, figures) in scanned or digital documents. Popular methods often rely on high-quality Optical Character Recognition (OCR) to merge visual features with extracted text. This dependency introduces two major drawbacks: propagation of text recognition errors and substantial computational overhead, limiting the robustness and practical applicability of multimodal approaches. In contrast to the prevailing multimodal trend, we argue that effective layout analysis depends not on text-visual fusion, but on a deep understanding of documents' intrinsic visual structure. To this end, we propose PARL (Position-Aware Relation Learning Network), a novel OCR-free, vision-only framework that models layout through positional sensitivity and relational structure. Specifically, we first introduce a Bidirectional Spatial Position-Guided Deformable Attention module to embed explicit positional dependencies among layout elements directly into visual features. Second, we design a Graph Refinement Classifier (GRC) to refine predictions by modeling contextual relationships through a dynamically constructed layout graph. Extensive experiments show PARL achieves state-of-the-art results. It establishes a new benchmark for vision-only methods on DocLayNet and, notably, surpasses even strong multimodal models on M6Doc. Crucially, PARL (65M) is highly efficient, using roughly four times fewer parameters than large multimodal models (256M), demonstrating that sophisticated visual structure modeling can be both more efficient and robust than multimodal fusion.
$λ$-GRPO: Unifying the GRPO Frameworks with Learnable Token Preferences
Oct 08, 2025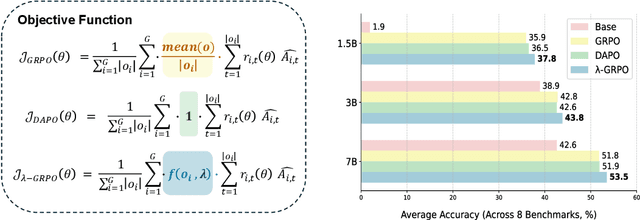
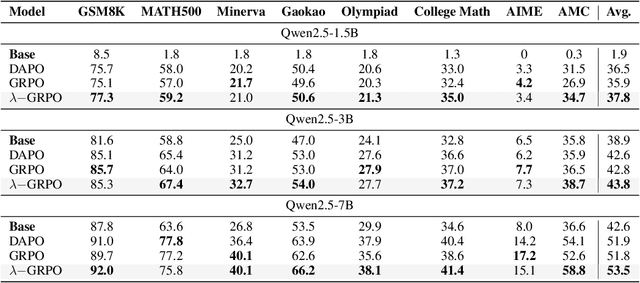
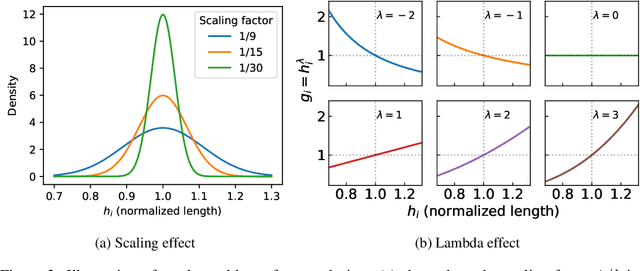

Reinforcement Learning with Human Feedback (RLHF) has been the dominant approach for improving the reasoning capabilities of Large Language Models (LLMs). Recently, Reinforcement Learning with Verifiable Rewards (RLVR) has simplified this paradigm by replacing the reward and value models with rule-based verifiers. A prominent example is Group Relative Policy Optimization (GRPO). However, GRPO inherently suffers from a length bias, since the same advantage is uniformly assigned to all tokens of a response. As a result, longer responses distribute the reward over more tokens and thus contribute disproportionately to gradient updates. Several variants, such as DAPO and Dr. GRPO, modify the token-level aggregation of the loss, yet these methods remain heuristic and offer limited interpretability regarding their implicit token preferences. In this work, we explore the possibility of allowing the model to learn its own token preference during optimization. We unify existing frameworks under a single formulation and introduce a learnable parameter $\lambda$ that adaptively controls token-level weighting. We use $\lambda$-GRPO to denote our method, and we find that $\lambda$-GRPO achieves consistent improvements over vanilla GRPO and DAPO on multiple mathematical reasoning benchmarks. On Qwen2.5 models with 1.5B, 3B, and 7B parameters, $\lambda$-GRPO improves average accuracy by $+1.9\%$, $+1.0\%$, and $+1.7\%$ compared to GRPO, respectively. Importantly, these gains come without any modifications to the training data or additional computational cost, highlighting the effectiveness and practicality of learning token preferences.
ReasoningGuard: Safeguarding Large Reasoning Models with Inference-time Safety Aha Moments
Aug 06, 2025Large Reasoning Models (LRMs) have demonstrated impressive performance in reasoning-intensive tasks, but they remain vulnerable to harmful content generation, particularly in the mid-to-late steps of their reasoning processes. Existing defense mechanisms, however, rely on costly fine-tuning and additional expert knowledge, which restricts their scalability. In this work, we propose ReasoningGuard, an inference-time safeguard for LRMs, which injects timely safety aha moments to steer harmless while helpful reasoning processes. Leveraging the model's internal attention behavior, our approach accurately identifies critical points in the reasoning path, and triggers spontaneous, safety-oriented reflection. To safeguard both the subsequent reasoning steps and the final answers, we further implement a scaling sampling strategy during the decoding phase, selecting the optimal reasoning path. Inducing minimal extra inference cost, ReasoningGuard effectively mitigates three types of jailbreak attacks, including the latest ones targeting the reasoning process of LRMs. Our approach outperforms seven existing safeguards, achieving state-of-the-art safety defenses while effectively avoiding the common exaggerated safety issues.
Cardiac-CLIP: A Vision-Language Foundation Model for 3D Cardiac CT Images
Jul 29, 2025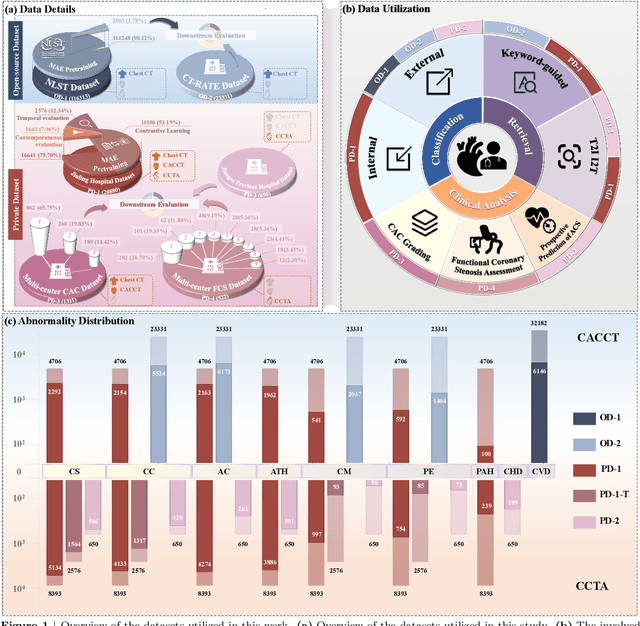
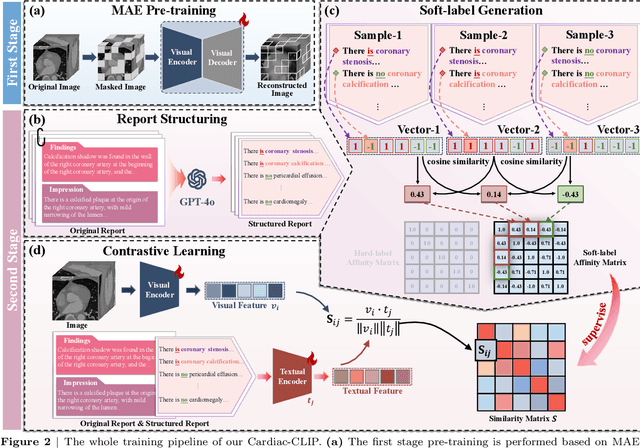
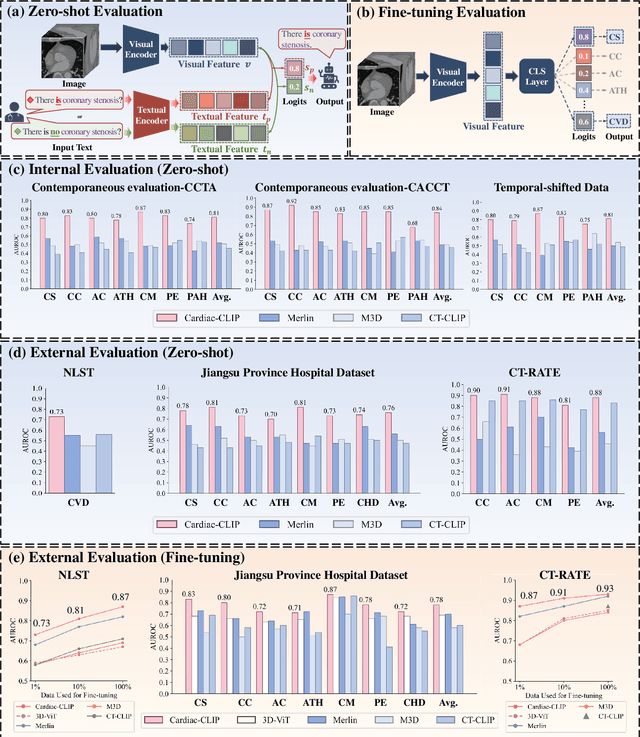
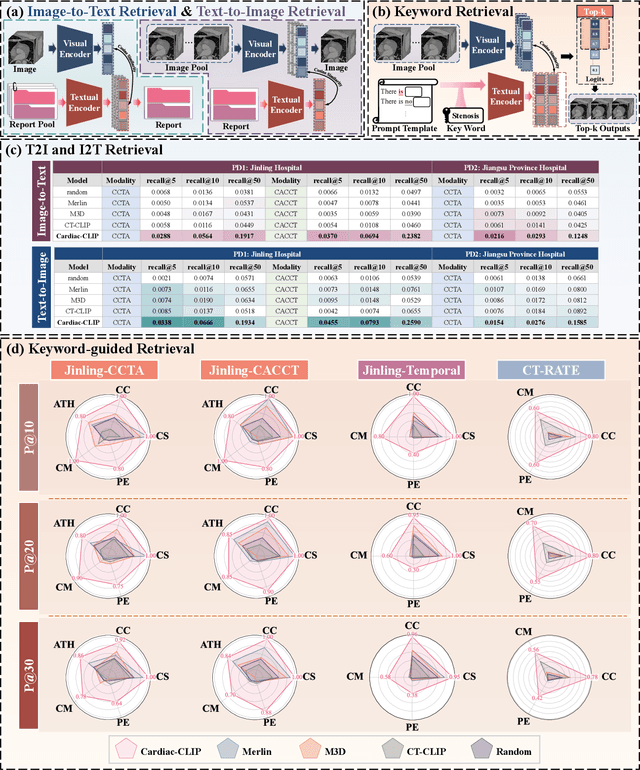
Foundation models have demonstrated remarkable potential in medical domain. However, their application to complex cardiovascular diagnostics remains underexplored. In this paper, we present Cardiac-CLIP, a multi-modal foundation model designed for 3D cardiac CT images. Cardiac-CLIP is developed through a two-stage pre-training strategy. The first stage employs a 3D masked autoencoder (MAE) to perform self-supervised representation learning from large-scale unlabeled volumetric data, enabling the visual encoder to capture rich anatomical and contextual features. In the second stage, contrastive learning is introduced to align visual and textual representations, facilitating cross-modal understanding. To support the pre-training, we collect 16641 real clinical CT scans, supplemented by 114k publicly available data. Meanwhile, we standardize free-text radiology reports into unified templates and construct the pathology vectors according to diagnostic attributes, based on which the soft-label matrix is generated to supervise the contrastive learning process. On the other hand, to comprehensively evaluate the effectiveness of Cardiac-CLIP, we collect 6,722 real-clinical data from 12 independent institutions, along with the open-source data to construct the evaluation dataset. Specifically, Cardiac-CLIP is comprehensively evaluated across multiple tasks, including cardiovascular abnormality classification, information retrieval and clinical analysis. Experimental results demonstrate that Cardiac-CLIP achieves state-of-the-art performance across various downstream tasks in both internal and external data. Particularly, Cardiac-CLIP exhibits great effectiveness in supporting complex clinical tasks such as the prospective prediction of acute coronary syndrome, which is notoriously difficult in real-world scenarios.
Continuum-armed Bandit Optimization with Batch Pairwise Comparison Oracles
May 28, 2025This paper studies a bandit optimization problem where the goal is to maximize a function $f(x)$ over $T$ periods for some unknown strongly concave function $f$. We consider a new pairwise comparison oracle, where the decision-maker chooses a pair of actions $(x, x')$ for a consecutive number of periods and then obtains an estimate of $f(x)-f(x')$. We show that such a pairwise comparison oracle finds important applications to joint pricing and inventory replenishment problems and network revenue management. The challenge in this bandit optimization is twofold. First, the decision-maker not only needs to determine a pair of actions $(x, x')$ but also a stopping time $n$ (i.e., the number of queries based on $(x, x')$). Second, motivated by our inventory application, the estimate of the difference $f(x)-f(x')$ is biased, which is different from existing oracles in stochastic optimization literature. To address these challenges, we first introduce a discretization technique and local polynomial approximation to relate this problem to linear bandits. Then we developed a tournament successive elimination technique to localize the discretized cell and run an interactive batched version of LinUCB algorithm on cells. We establish regret bounds that are optimal up to poly-logarithmic factors. Furthermore, we apply our proposed algorithm and analytical framework to the two operations management problems and obtain results that improve state-of-the-art results in the existing literature.
UORA: Uniform Orthogonal Reinitialization Adaptation in Parameter-Efficient Fine-Tuning of Large Models
May 26, 2025This paper introduces Uniform Orthogonal Reinitialization Adaptation (UORA), a novel parameter-efficient fine-tuning (PEFT) approach for Large Language Models (LLMs). UORA achieves state-of-the-art performance and parameter efficiency by leveraging a low-rank approximation method to reduce the number of trainable parameters. Unlike existing methods such as LoRA and VeRA, UORA employs an interpolation-based reparametrization mechanism that selectively reinitializes rows and columns in frozen projection matrices, guided by the vector magnitude heuristic. This results in substantially fewer trainable parameters compared to LoRA and outperforms VeRA in computation and storage efficiency. Comprehensive experiments across various benchmarks demonstrate UORA's superiority in achieving competitive fine-tuning performance with negligible computational overhead. We demonstrate its performance on GLUE and E2E benchmarks and its effectiveness in instruction-tuning large language models and image classification models. Our contributions establish a new paradigm for scalable and resource-efficient fine-tuning of LLMs.
* 20 pages, 2 figures, 15 tables
A topology-preserving three-stage framework for fully-connected coronary artery extraction
Apr 02, 2025Coronary artery extraction is a crucial prerequisite for computer-aided diagnosis of coronary artery disease. Accurately extracting the complete coronary tree remains challenging due to several factors, including presence of thin distal vessels, tortuous topological structures, and insufficient contrast. These issues often result in over-segmentation and under-segmentation in current segmentation methods. To address these challenges, we propose a topology-preserving three-stage framework for fully-connected coronary artery extraction. This framework includes vessel segmentation, centerline reconnection, and missing vessel reconstruction. First, we introduce a new centerline enhanced loss in the segmentation process. Second, for the broken vessel segments, we further propose a regularized walk algorithm to integrate distance, probabilities predicted by a centerline classifier, and directional cosine similarity, for reconnecting the centerlines. Third, we apply implicit neural representation and implicit modeling, to reconstruct the geometric model of the missing vessels. Experimental results show that our proposed framework outperforms existing methods, achieving Dice scores of 88.53\% and 85.07\%, with Hausdorff Distances (HD) of 1.07mm and 1.63mm on ASOCA and PDSCA datasets, respectively. Code will be available at https://github.com/YH-Qiu/CorSegRec.