 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA topology-preserving three-stage framework for fully-connected coronary artery extraction
Apr 02, 2025Coronary artery extraction is a crucial prerequisite for computer-aided diagnosis of coronary artery disease. Accurately extracting the complete coronary tree remains challenging due to several factors, including presence of thin distal vessels, tortuous topological structures, and insufficient contrast. These issues often result in over-segmentation and under-segmentation in current segmentation methods. To address these challenges, we propose a topology-preserving three-stage framework for fully-connected coronary artery extraction. This framework includes vessel segmentation, centerline reconnection, and missing vessel reconstruction. First, we introduce a new centerline enhanced loss in the segmentation process. Second, for the broken vessel segments, we further propose a regularized walk algorithm to integrate distance, probabilities predicted by a centerline classifier, and directional cosine similarity, for reconnecting the centerlines. Third, we apply implicit neural representation and implicit modeling, to reconstruct the geometric model of the missing vessels. Experimental results show that our proposed framework outperforms existing methods, achieving Dice scores of 88.53\% and 85.07\%, with Hausdorff Distances (HD) of 1.07mm and 1.63mm on ASOCA and PDSCA datasets, respectively. Code will be available at https://github.com/YH-Qiu/CorSegRec.
Reconstruct Spine CT from Biplanar X-Rays via Diffusion Learning
Aug 21, 2024

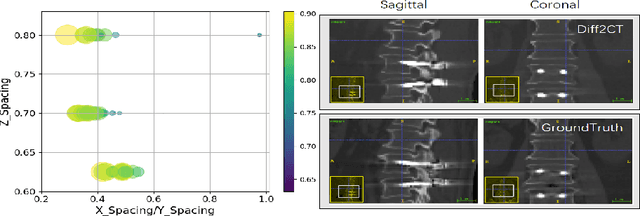
Intraoperative CT imaging serves as a crucial resource for surgical guidance; however, it may not always be readily accessible or practical to implement. In scenarios where CT imaging is not an option, reconstructing CT scans from X-rays can offer a viable alternative. In this paper, we introduce an innovative method for 3D CT reconstruction utilizing biplanar X-rays. Distinct from previous research that relies on conventional image generation techniques, our approach leverages a conditional diffusion process to tackle the task of reconstruction. More precisely, we employ a diffusion-based probabilistic model trained to produce 3D CT images based on orthogonal biplanar X-rays. To improve the structural integrity of the reconstructed images, we incorporate a novel projection loss function. Experimental results validate that our proposed method surpasses existing state-of-the-art benchmarks in both visual image quality and multiple evaluative metrics. Specifically, our technique achieves a higher Structural Similarity Index (SSIM) of 0.83, a relative increase of 10\%, and a lower Fr\'echet Inception Distance (FID) of 83.43, which represents a relative decrease of 25\%.
Coarse-Fine View Attention Alignment-Based GAN for CT Reconstruction from Biplanar X-Rays
Aug 19, 2024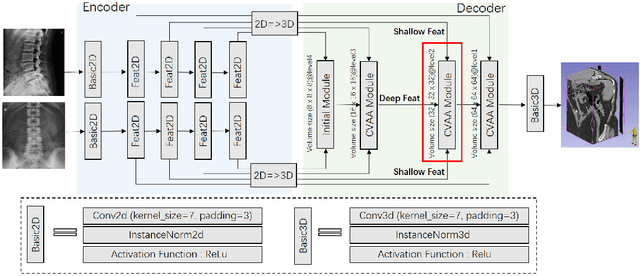
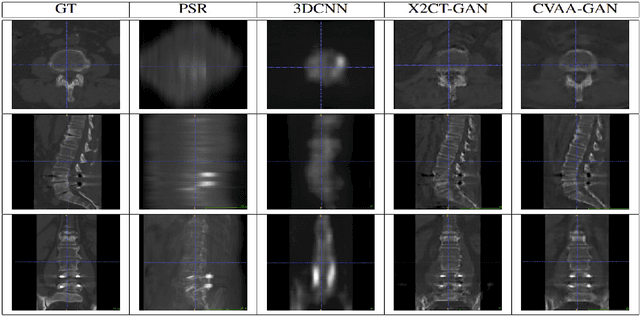

For surgical planning and intra-operation imaging, CT reconstruction using X-ray images can potentially be an important alternative when CT imaging is not available or not feasible. In this paper, we aim to use biplanar X-rays to reconstruct a 3D CT image, because biplanar X-rays convey richer information than single-view X-rays and are more commonly used by surgeons. Different from previous studies in which the two X-ray views were treated indifferently when fusing the cross-view data, we propose a novel attention-informed coarse-to-fine cross-view fusion method to combine the features extracted from the orthogonal biplanar views. This method consists of a view attention alignment sub-module and a fine-distillation sub-module that are designed to work together to highlight the unique or complementary information from each of the views. Experiments have demonstrated the superiority of our proposed method over the SOTA methods.
Blind deblurring for microscopic pathology images using deep learning networks
Nov 24, 2020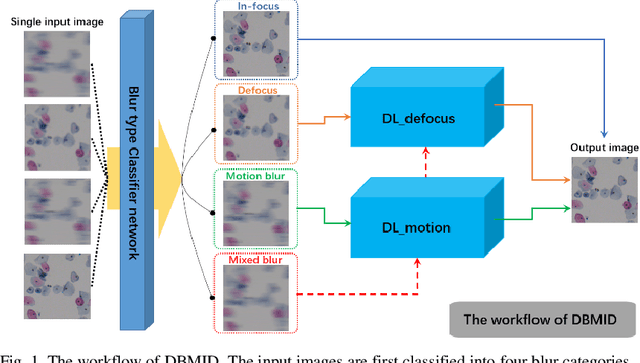
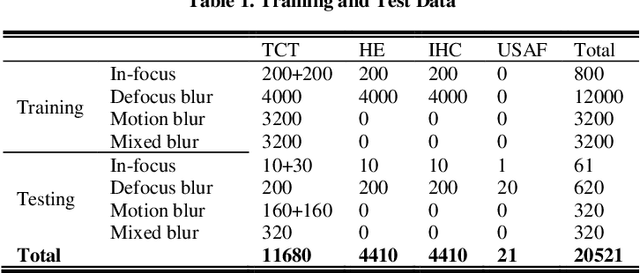
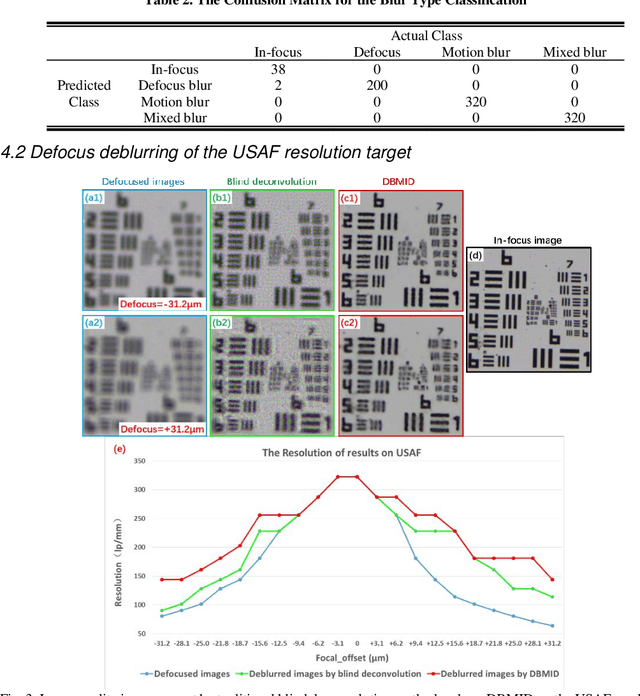
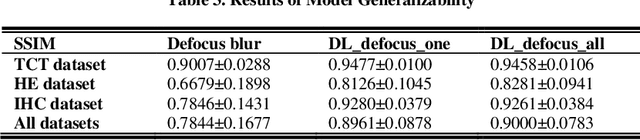
Artificial Intelligence (AI)-powered pathology is a revolutionary step in the world of digital pathology and shows great promise to increase both diagnosis accuracy and efficiency. However, defocus and motion blur can obscure tissue or cell characteristics hence compromising AI algorithms'accuracy and robustness in analyzing the images. In this paper, we demonstrate a deep-learning-based approach that can alleviate the defocus and motion blur of a microscopic image and output a sharper and cleaner image with retrieved fine details without prior knowledge of the blur type, blur extent and pathological stain. In this approach, a deep learning classifier is first trained to identify the image blur type. Then, two encoder-decoder networks are trained and used alone or in combination to deblur the input image. It is an end-to-end approach and introduces no corrugated artifacts as traditional blind deconvolution methods do. We test our approach on different types of pathology specimens and demonstrate great performance on image blur correction and the subsequent improvement on the diagnosis outcome of AI algorithms.
Microscope Based HER2 Scoring System
Sep 15, 2020

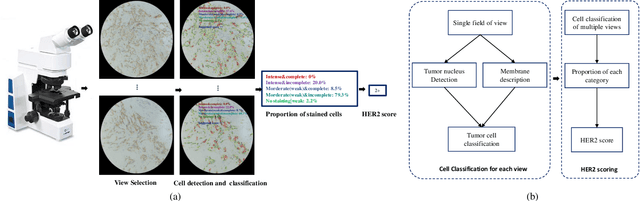
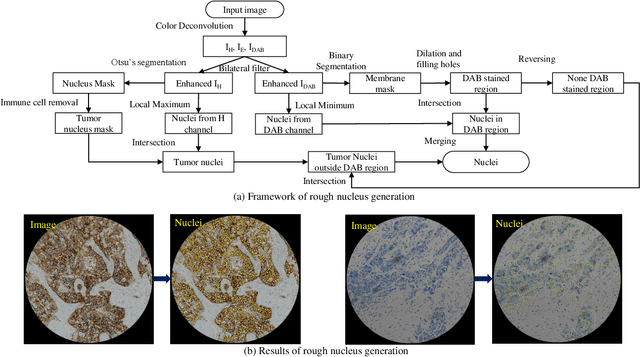
The overexpression of human epidermal growth factor receptor 2 (HER2) has been established as a therapeutic target in multiple types of cancers, such as breast and gastric cancers. Immunohistochemistry (IHC) is employed as a basic HER2 test to identify the HER2-positive, borderline, and HER2-negative patients. However, the reliability and accuracy of HER2 scoring are affected by many factors, such as pathologists' experience. Recently, artificial intelligence (AI) has been used in various disease diagnosis to improve diagnostic accuracy and reliability, but the interpretation of diagnosis results is still an open problem. In this paper, we propose a real-time HER2 scoring system, which follows the HER2 scoring guidelines to complete the diagnosis, and thus each step is explainable. Unlike the previous scoring systems based on whole-slide imaging, our HER2 scoring system is integrated into an augmented reality (AR) microscope that can feedback AI results to the pathologists while reading the slide. The pathologists can help select informative fields of view (FOVs), avoiding the confounding regions, such as DCIS. Importantly, we illustrate the intermediate results with membrane staining condition and cell classification results, making it possible to evaluate the reliability of the diagnostic results. Also, we support the interactive modification of selecting regions-of-interest, making our system more flexible in clinical practice. The collaboration of AI and pathologists can significantly improve the robustness of our system. We evaluate our system with 285 breast IHC HER2 slides, and the classification accuracy of 95\% shows the effectiveness of our HER2 scoring system.
D-UNet: a dimension-fusion U shape network for chronic stroke lesion segmentation
Aug 14, 2019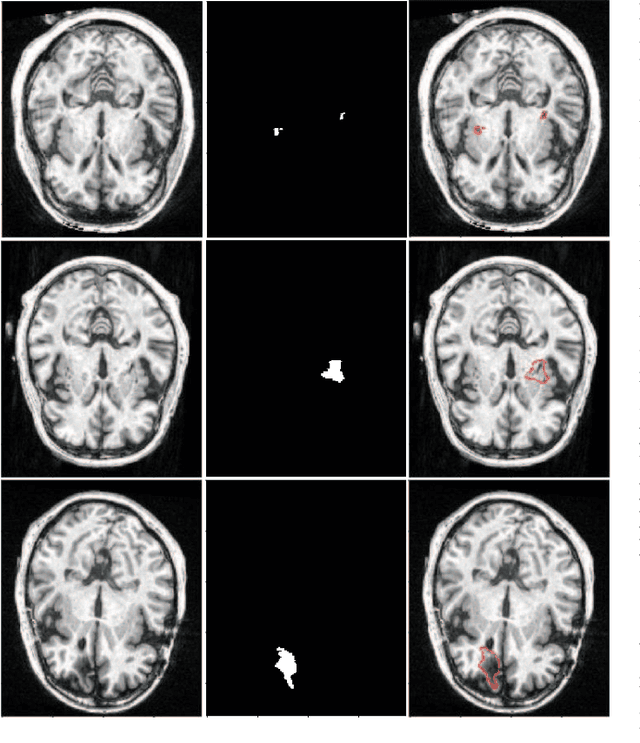
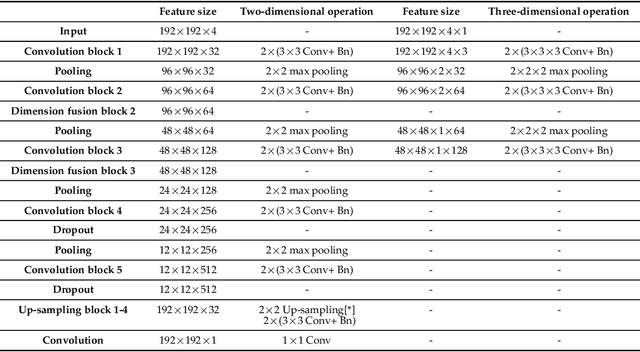
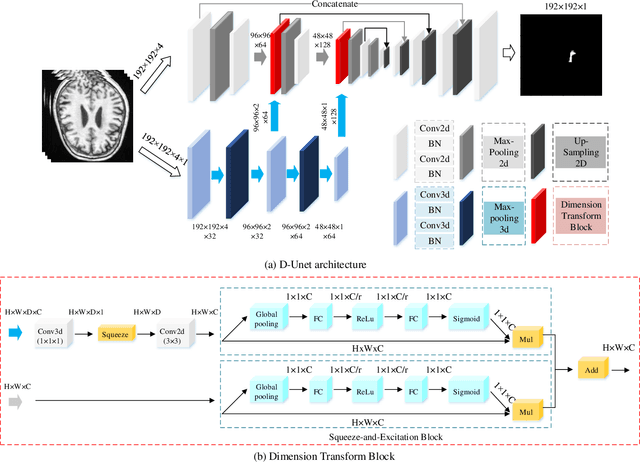
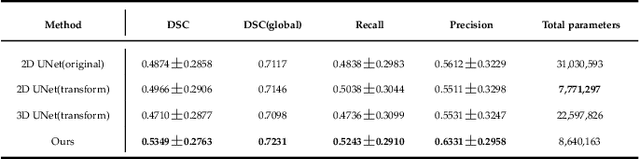
Assessing the location and extent of lesions caused by chronic stroke is critical for medical diagnosis, surgical planning, and prognosis. In recent years, with the rapid development of 2D and 3D convolutional neural networks (CNN), the encoder-decoder structure has shown great potential in the field of medical image segmentation. However, the 2D CNN ignores the 3D information of medical images, while the 3D CNN suffers from high computational resource demands. This paper proposes a new architecture called dimension-fusion-UNet (D-UNet), which combines 2D and 3D convolution innovatively in the encoding stage. The proposed architecture achieves a better segmentation performance than 2D networks, while requiring significantly less computation time in comparison to 3D networks. Furthermore, to alleviate the data imbalance issue between positive and negative samples for the network training, we propose a new loss function called Enhance Mixing Loss (EML). This function adds a weighted focal coefficient and combines two traditional loss functions. The proposed method has been tested on the ATLAS dataset and compared to three state-of-the-art methods. The results demonstrate that the proposed method achieves the best quality performance in terms of DSC = 0.5349+0.2763 and precision = 0.6331+0.295).
Combining SLAM with muti-spectral photometric stereo for real-time dense 3D reconstruction
Jul 06, 2018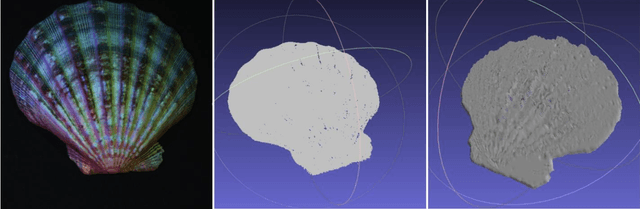
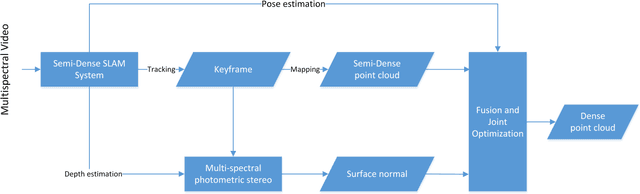


Obtaining dense 3D reconstrution with low computational cost is one of the important goals in the field of SLAM. In this paper we propose a dense 3D reconstruction framework from monocular multispectral video sequences using jointly semi-dense SLAM and Multispectral Photometric Stereo approaches. Starting from multispectral video, SALM (a) reconstructs a semi-dense 3D shape that will be densified;(b) recovers relative sparse depth map that is then fed as prioris into optimization-based multispectral photometric stereo for a more accurate dense surface normal recovery;(c)obtains camera pose that is subsequently used for conversion of view in the process of fusion where we combine the relative sparse point cloud with the dense surface normal using the automated cross-scale fusion method proposed in this paper to get a dense point cloud with subtle texture information. Experiments show that our method can effectively obtain denser 3D reconstructions.