 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-Express: Conditional Dropout for Progressive Training of Portrait Video Generation
Jun 04, 2024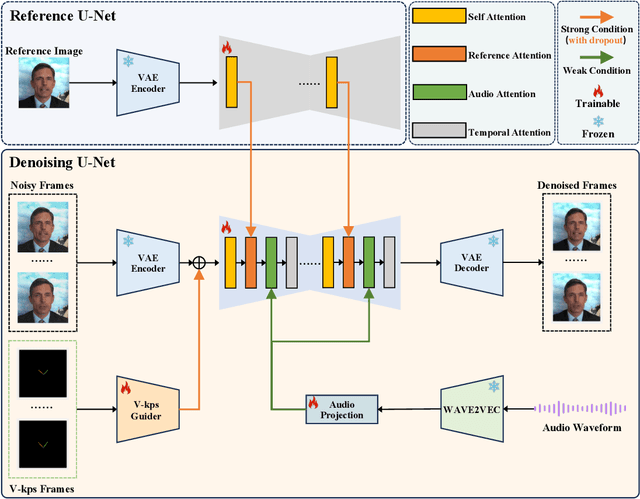

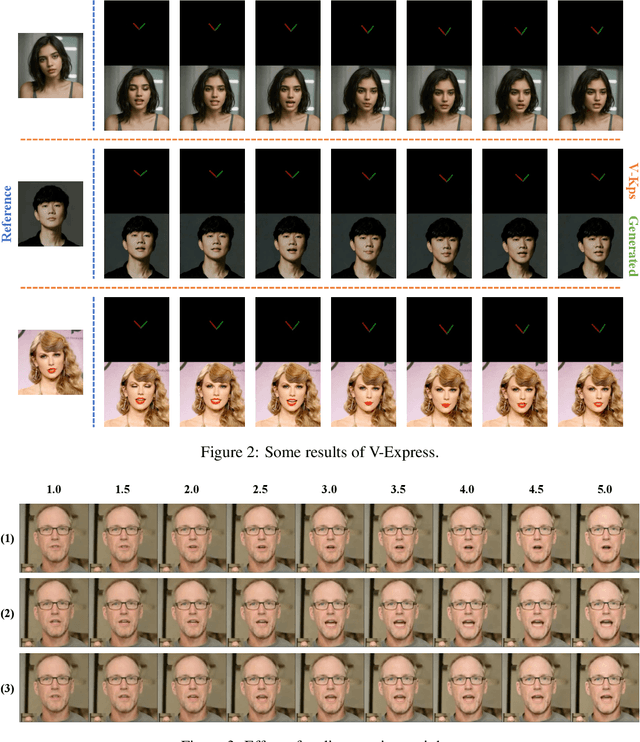
In the field of portrait video generation, the use of single images to generate portrait videos has become increasingly prevalent. A common approach involves leveraging generative models to enhance adapters for controlled generation. However, control signals (e.g., text, audio, reference image, pose, depth map, etc.) can vary in strength. Among these, weaker conditions often struggle to be effective due to interference from stronger conditions, posing a challenge in balancing these conditions. In our work on portrait video generation, we identified audio signals as particularly weak, often overshadowed by stronger signals such as facial pose and reference image. However, direct training with weak signals often leads to difficulties in convergence. To address this, we propose V-Express, a simple method that balances different control signals through the progressive training and the conditional dropout operation. Our method gradually enables effective control by weak conditions, thereby achieving generation capabilities that simultaneously take into account the facial pose, reference image, and audio. The experimental results demonstrate that our method can effectively generate portrait videos controlled by audio. Furthermore, a potential solution is provided for the simultaneous and effective use of conditions of varying strengths.
Ensembling Diffusion Models via Adaptive Feature Aggregation
May 27, 2024



The success of the text-guided diffusion model has inspired the development and release of numerous powerful diffusion models within the open-source community. These models are typically fine-tuned on various expert datasets, showcasing diverse denoising capabilities. Leveraging multiple high-quality models to produce stronger generation ability is valuable, but has not been extensively studied. Existing methods primarily adopt parameter merging strategies to produce a new static model. However, they overlook the fact that the divergent denoising capabilities of the models may dynamically change across different states, such as when experiencing different prompts, initial noises, denoising steps, and spatial locations. In this paper, we propose a novel ensembling method, Adaptive Feature Aggregation (AFA), which dynamically adjusts the contributions of multiple models at the feature level according to various states (i.e., prompts, initial noises, denoising steps, and spatial locations), thereby keeping the advantages of multiple diffusion models, while suppressing their disadvantages. Specifically, we design a lightweight Spatial-Aware Block-Wise (SABW) feature aggregator that adaptive aggregates the block-wise intermediate features from multiple U-Net denoisers into a unified one. The core idea lies in dynamically producing an individual attention map for each model's features by comprehensively considering various states. It is worth noting that only SABW is trainable with about 50 million parameters, while other models are frozen. Both the quantitative and qualitative experiments demonstrate the effectiveness of our proposed Adaptive Feature Aggregation method. The code is available at https://github.com/tenvence/afa/.
Effortless Cross-Platform Video Codec: A Codebook-Based Method
Oct 16, 2023Under certain circumstances, advanced neural video codecs can surpass the most complex traditional codecs in their rate-distortion (RD) performance. One of the main reasons for the high performance of existing neural video codecs is the use of the entropy model, which can provide more accurate probability distribution estimations for compressing the latents. This also implies the rigorous requirement that entropy models running on different platforms should use consistent distribution estimations. However, in cross-platform scenarios, entropy models running on different platforms usually yield inconsistent probability distribution estimations due to floating point computation errors that are platform-dependent, which can cause the decoding side to fail in correctly decoding the compressed bitstream sent by the encoding side. In this paper, we propose a cross-platform video compression framework based on codebooks, which avoids autoregressive entropy modeling and achieves video compression by transmitting the index sequence of the codebooks. Moreover, instead of using optical flow for context alignment, we propose to use the conditional cross-attention module to obtain the context between frames. Due to the absence of autoregressive modeling and optical flow alignment, we can design an extremely minimalist framework that can greatly benefit computational efficiency. Importantly, our framework no longer contains any distribution estimation modules for entropy modeling, and thus computations across platforms are not necessarily consistent. Experimental results show that our method can outperform the traditional H.265 (medium) even without any entropy constraints, while achieving the cross-platform property intrinsically.
Towards Real-Time Neural Video Codec for Cross-Platform Application Using Calibration Information
Sep 20, 2023



The state-of-the-art neural video codecs have outperformed the most sophisticated traditional codecs in terms of RD performance in certain cases. However, utilizing them for practical applications is still challenging for two major reasons. 1) Cross-platform computational errors resulting from floating point operations can lead to inaccurate decoding of the bitstream. 2) The high computational complexity of the encoding and decoding process poses a challenge in achieving real-time performance. In this paper, we propose a real-time cross-platform neural video codec, which is capable of efficiently decoding of 720P video bitstream from other encoding platforms on a consumer-grade GPU. First, to solve the problem of inconsistency of codec caused by the uncertainty of floating point calculations across platforms, we design a calibration transmitting system to guarantee the consistent quantization of entropy parameters between the encoding and decoding stages. The parameters that may have transboundary quantization between encoding and decoding are identified in the encoding stage, and their coordinates will be delivered by auxiliary transmitted bitstream. By doing so, these inconsistent parameters can be processed properly in the decoding stage. Furthermore, to reduce the bitrate of the auxiliary bitstream, we rectify the distribution of entropy parameters using a piecewise Gaussian constraint. Second, to match the computational limitations on the decoding side for real-time video codec, we design a lightweight model. A series of efficiency techniques enable our model to achieve 25 FPS decoding speed on NVIDIA RTX 2080 GPU. Experimental results demonstrate that our model can achieve real-time decoding of 720P videos while encoding on another platform. Furthermore, the real-time model brings up to a maximum of 24.2\% BD-rate improvement from the perspective of PSNR with the anchor H.265.
Microscope Based HER2 Scoring System
Sep 15, 2020

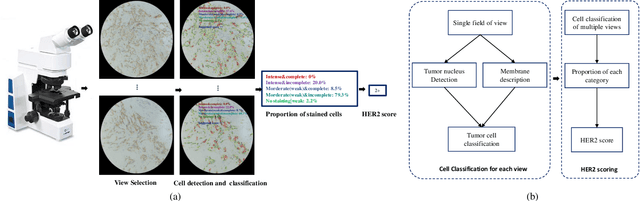
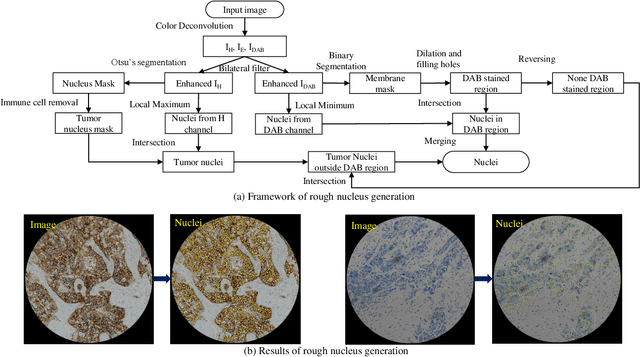
The overexpression of human epidermal growth factor receptor 2 (HER2) has been established as a therapeutic target in multiple types of cancers, such as breast and gastric cancers. Immunohistochemistry (IHC) is employed as a basic HER2 test to identify the HER2-positive, borderline, and HER2-negative patients. However, the reliability and accuracy of HER2 scoring are affected by many factors, such as pathologists' experience. Recently, artificial intelligence (AI) has been used in various disease diagnosis to improve diagnostic accuracy and reliability, but the interpretation of diagnosis results is still an open problem. In this paper, we propose a real-time HER2 scoring system, which follows the HER2 scoring guidelines to complete the diagnosis, and thus each step is explainable. Unlike the previous scoring systems based on whole-slide imaging, our HER2 scoring system is integrated into an augmented reality (AR) microscope that can feedback AI results to the pathologists while reading the slide. The pathologists can help select informative fields of view (FOVs), avoiding the confounding regions, such as DCIS. Importantly, we illustrate the intermediate results with membrane staining condition and cell classification results, making it possible to evaluate the reliability of the diagnostic results. Also, we support the interactive modification of selecting regions-of-interest, making our system more flexible in clinical practice. The collaboration of AI and pathologists can significantly improve the robustness of our system. We evaluate our system with 285 breast IHC HER2 slides, and the classification accuracy of 95\% shows the effectiveness of our HER2 scoring system.