 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-Express: Conditional Dropout for Progressive Training of Portrait Video Generation
Paper and Code
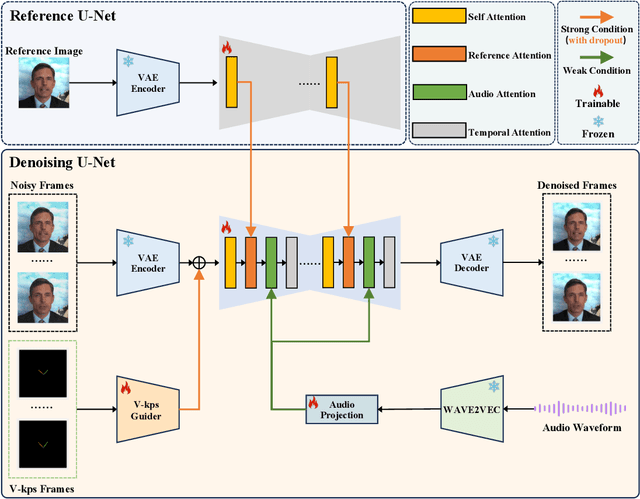

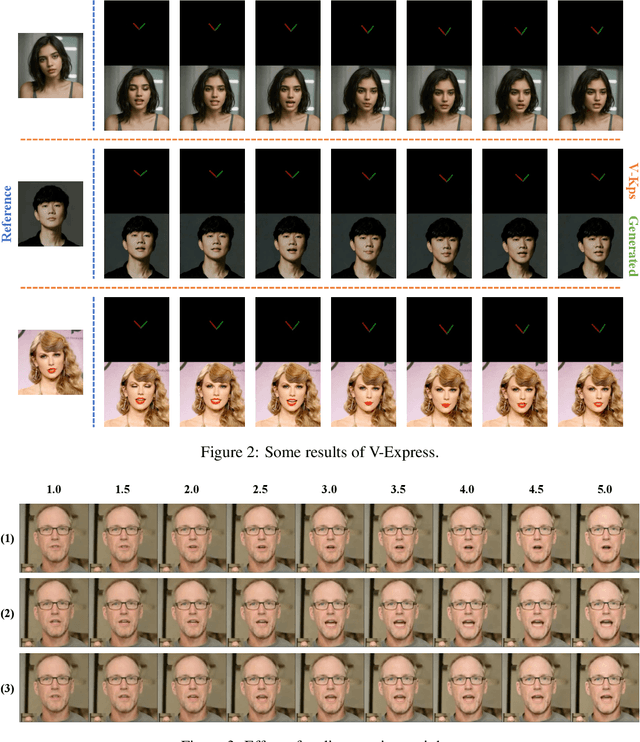
In the field of portrait video generation, the use of single images to generate portrait videos has become increasingly prevalent. A common approach involves leveraging generative models to enhance adapters for controlled generation. However, control signals (e.g., text, audio, reference image, pose, depth map, etc.) can vary in strength. Among these, weaker conditions often struggle to be effective due to interference from stronger conditions, posing a challenge in balancing these conditions. In our work on portrait video generation, we identified audio signals as particularly weak, often overshadowed by stronger signals such as facial pose and reference image. However, direct training with weak signals often leads to difficulties in convergence. To address this, we propose V-Express, a simple method that balances different control signals through the progressive training and the conditional dropout operation. Our method gradually enables effective control by weak conditions, thereby achieving generation capabilities that simultaneously take into account the facial pose, reference image, and audio. The experimental results demonstrate that our method can effectively generate portrait videos controlled by audio. Furthermore, a potential solution is provided for the simultaneous and effective use of conditions of varying strengths.