 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Tokens Matter Equally: Dynamic In-context Vector Distillation with Decisive-Token Supervision for Long-form Medical Report Generation
May 26, 2026Distilling demonstration effects into hidden-space interventions offers a lightweight alternative to full finetuning. However, existing multimodal variants are mostly evaluated on short-form tasks, where outputs end after a few tokens. Extending these methods to long-form generation exposes a fundamental yet underexamined limitation: token-level distillation implicitly treats all output tokens as equally informative, but long-form outputs are dominated by high-frequency template and grammatical tokens, while the tokens that actually determine output quality are sparsely distributed. In medical report generation (MRG), two such decisive tokens stand out: pathology-related tokens that determine diagnostic content, and the end-of-sequence (EOS) event that determines termination. Both receive insufficient supervision under uniform cross-entropy, and autoregressive decoding further compounds the problem by drifting away from teacher-forced trajectories. We propose DIVE, a frozen-backbone distillation framework that addresses long-form report generation through two complementary mechanisms matched to these failures. Decisive-token supervision restores supervision balance by upweighting the cross-entropy contribution of pathology-related tokens and the EOS event, ensuring that content fidelity and termination are learned during training rather than imposed at decoding time. State-conditioned dynamic steering replaces fixed open-loop residuals with hidden-state-dependent adapters, allowing the injected signal to adapt as decoding drifts. Experiments on MIMIC-CXR and CheXpert Plus with two medical VLM backbones show that DIVE consistently ranks among the strongest methods across lexical and clinical-proxy metrics. Our method achieves the best BLEU-4, ROUGE-L, and RadGraph F1 in all dataset--backbone settings, while remaining competitive on coarse label-level CheXbert F1.
A Generative Foundation Model for Multimodal Histopathology
Apr 04, 2026Accurate diagnosis and treatment of complex diseases require integrating histological, molecular, and clinical data, yet in practice these modalities are often incomplete owing to tissue scarcity, assay cost, and workflow constraints. Existing computational approaches attempt to impute missing modalities from available data but rely on task-specific models trained on narrow, single source-target pairs, limiting their generalizability. Here we introduce MuPD (Multimodal Pathology Diffusion), a generative foundation model that embeds hematoxylin and eosin (H&E)-stained histology, molecular RNA profiles, and clinical text into a shared latent space through a diffusion transformer with decoupled cross-modal attention. Pretrained on 100 million histology image patches, 1.6 million text-histology pairs, and 10.8 million RNA-histology pairs spanning 34 human organs, MuPD supports diverse cross-modal synthesis tasks with minimal or no task-specific fine-tuning. For text-conditioned and image-to-image generation, MuPD synthesizes histologically faithful tissue architectures, reducing Fréchet inception distance (FID) scores by 50% relative to domain-specific models and improving few-shot classification accuracy by up to 47% through synthetic data augmentation. For RNA-conditioned histology generation, MuPD reduces FID by 23% compared with the next-best method while preserving cell-type distributions across five cancer types. As a virtual stainer, MuPD translates H&E images to immunohistochemistry and multiplex immunofluorescence, improving average marker correlation by 37% over existing approaches. These results demonstrate that a single, unified generative model pretrained across heterogeneous pathology modalities can substantially outperform specialized alternatives, providing a scalable computational framework for multimodal histopathology.
A Multimodal Foundation Model of Spatial Transcriptomics and Histology for Biological Discovery and Clinical Prediction
Apr 04, 2026Spatial transcriptomics (ST) enables gene expression mapping within anatomical context but remains costly and low-throughput. Hematoxylin and eosin (H\&E) staining offers rich morphology yet lacks molecular resolution. We present \textbf{\ours} (\textbf{S}patial \textbf{T}ranscriptomics and hist\textbf{O}logy \textbf{R}epresentation \textbf{M}odel), a foundation model trained on 1.2 million spatially resolved transcriptomic profiles with matched histology across 18 organs. Using a hierarchical architecture integrating morphological features, gene expression, and spatial context, STORM bridges imaging and omics through robust molecular--morphological representations. STORM enhances spatial domain discovery, producing biologically coherent tissue maps, and outperforms existing methods in predicting spatial gene expression from H\&E images across 11 tumor types. The model is platform-agnostic, performing consistently across Visium, Xenium, Visium HD, and CosMx. Applied to 23 independent cohorts comprising 7,245 patients, STORM significantly improves immunotherapy response prediction and prognostication over established biomarkers, providing a scalable framework for spatially informed discovery and clinical precision medicine.
nnMIL: A generalizable multiple instance learning framework for computational pathology
Nov 18, 2025Computational pathology holds substantial promise for improving diagnosis and guiding treatment decisions. Recent pathology foundation models enable the extraction of rich patch-level representations from large-scale whole-slide images (WSIs), but current approaches for aggregating these features into slide-level predictions remain constrained by design limitations that hinder generalizability and reliability. Here, we developed nnMIL, a simple yet broadly applicable multiple-instance learning framework that connects patch-level foundation models to robust slide-level clinical inference. nnMIL introduces random sampling at both the patch and feature levels, enabling large-batch optimization, task-aware sampling strategies, and efficient and scalable training across datasets and model architectures. A lightweight aggregator performs sliding-window inference to generate ensemble slide-level predictions and supports principled uncertainty estimation. Across 40,000 WSIs encompassing 35 clinical tasks and four pathology foundation models, nnMIL consistently outperformed existing MIL methods for disease diagnosis, histologic subtyping, molecular biomarker detection, and pan- cancer prognosis prediction. It further demonstrated strong cross-model generalization, reliable uncertainty quantification, and robust survival stratification in multiple external cohorts. In conclusion, nnMIL offers a practical and generalizable solution for translating pathology foundation models into clinically meaningful predictions, advancing the development and deployment of reliable AI systems in real-world settings.
Image Super-resolution Via Latent Diffusion: A Sampling-space Mixture Of Experts And Frequency-augmented Decoder Approach
Oct 20, 2023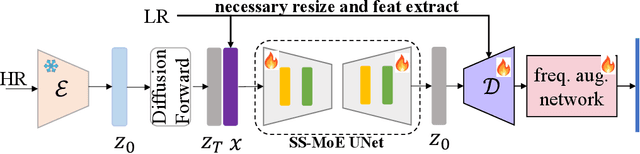
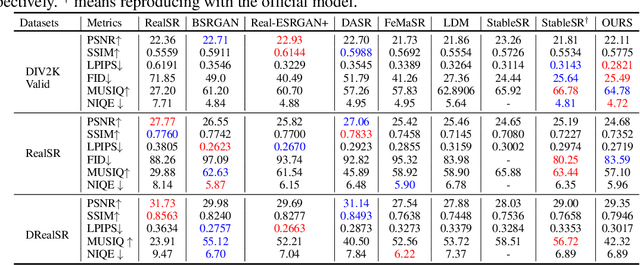
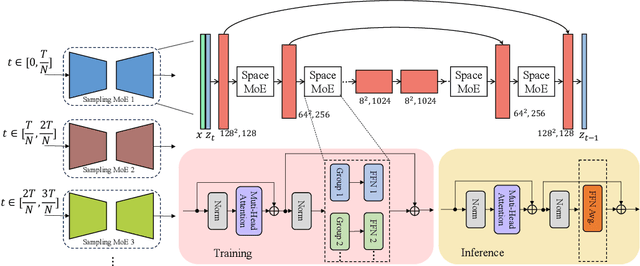

The recent use of diffusion prior, enhanced by pre-trained text-image models, has markedly elevated the performance of image super-resolution (SR). To alleviate the huge computational cost required by pixel-based diffusion SR, latent-based methods utilize a feature encoder to transform the image and then implement the SR image generation in a compact latent space. Nevertheless, there are two major issues that limit the performance of latent-based diffusion. First, the compression of latent space usually causes reconstruction distortion. Second, huge computational cost constrains the parameter scale of the diffusion model. To counteract these issues, we first propose a frequency compensation module that enhances the frequency components from latent space to pixel space. The reconstruction distortion (especially for high-frequency information) can be significantly decreased. Then, we propose to use Sample-Space Mixture of Experts (SS-MoE) to achieve more powerful latent-based SR, which steadily improves the capacity of the model without a significant increase in inference costs. These carefully crafted designs contribute to performance improvements in largely explored 4x blind super-resolution benchmarks and extend to large magnification factors, i.e., 8x image SR benchmarks. The code is available at https://github.com/amandaluof/moe_sr.
Effortless Cross-Platform Video Codec: A Codebook-Based Method
Oct 16, 2023Under certain circumstances, advanced neural video codecs can surpass the most complex traditional codecs in their rate-distortion (RD) performance. One of the main reasons for the high performance of existing neural video codecs is the use of the entropy model, which can provide more accurate probability distribution estimations for compressing the latents. This also implies the rigorous requirement that entropy models running on different platforms should use consistent distribution estimations. However, in cross-platform scenarios, entropy models running on different platforms usually yield inconsistent probability distribution estimations due to floating point computation errors that are platform-dependent, which can cause the decoding side to fail in correctly decoding the compressed bitstream sent by the encoding side. In this paper, we propose a cross-platform video compression framework based on codebooks, which avoids autoregressive entropy modeling and achieves video compression by transmitting the index sequence of the codebooks. Moreover, instead of using optical flow for context alignment, we propose to use the conditional cross-attention module to obtain the context between frames. Due to the absence of autoregressive modeling and optical flow alignment, we can design an extremely minimalist framework that can greatly benefit computational efficiency. Importantly, our framework no longer contains any distribution estimation modules for entropy modeling, and thus computations across platforms are not necessarily consistent. Experimental results show that our method can outperform the traditional H.265 (medium) even without any entropy constraints, while achieving the cross-platform property intrinsically.
Towards Real-Time Neural Video Codec for Cross-Platform Application Using Calibration Information
Sep 20, 2023



The state-of-the-art neural video codecs have outperformed the most sophisticated traditional codecs in terms of RD performance in certain cases. However, utilizing them for practical applications is still challenging for two major reasons. 1) Cross-platform computational errors resulting from floating point operations can lead to inaccurate decoding of the bitstream. 2) The high computational complexity of the encoding and decoding process poses a challenge in achieving real-time performance. In this paper, we propose a real-time cross-platform neural video codec, which is capable of efficiently decoding of 720P video bitstream from other encoding platforms on a consumer-grade GPU. First, to solve the problem of inconsistency of codec caused by the uncertainty of floating point calculations across platforms, we design a calibration transmitting system to guarantee the consistent quantization of entropy parameters between the encoding and decoding stages. The parameters that may have transboundary quantization between encoding and decoding are identified in the encoding stage, and their coordinates will be delivered by auxiliary transmitted bitstream. By doing so, these inconsistent parameters can be processed properly in the decoding stage. Furthermore, to reduce the bitrate of the auxiliary bitstream, we rectify the distribution of entropy parameters using a piecewise Gaussian constraint. Second, to match the computational limitations on the decoding side for real-time video codec, we design a lightweight model. A series of efficiency techniques enable our model to achieve 25 FPS decoding speed on NVIDIA RTX 2080 GPU. Experimental results demonstrate that our model can achieve real-time decoding of 720P videos while encoding on another platform. Furthermore, the real-time model brings up to a maximum of 24.2\% BD-rate improvement from the perspective of PSNR with the anchor H.265.
Dynamic Low-Rank Instance Adaptation for Universal Neural Image Compression
Aug 15, 2023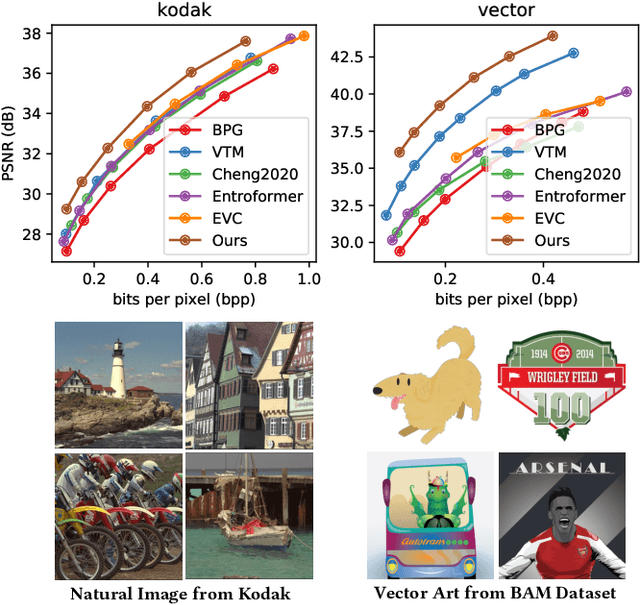
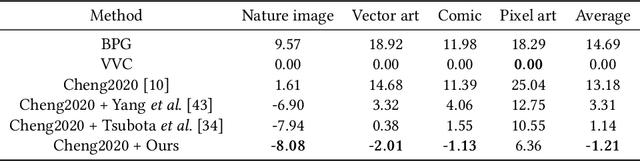
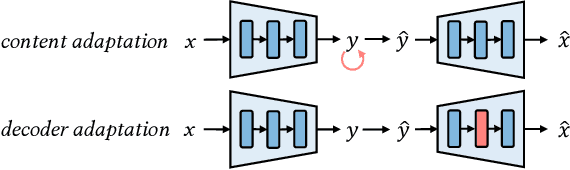

The latest advancements in neural image compression show great potential in surpassing the rate-distortion performance of conventional standard codecs. Nevertheless, there exists an indelible domain gap between the datasets utilized for training (i.e., natural images) and those utilized for inference (e.g., artistic images). Our proposal involves a low-rank adaptation approach aimed at addressing the rate-distortion drop observed in out-of-domain datasets. Specifically, we perform low-rank matrix decomposition to update certain adaptation parameters of the client's decoder. These updated parameters, along with image latents, are encoded into a bitstream and transmitted to the decoder in practical scenarios. Due to the low-rank constraint imposed on the adaptation parameters, the resulting bit rate overhead is small. Furthermore, the bit rate allocation of low-rank adaptation is \emph{non-trivial}, considering the diverse inputs require varying adaptation bitstreams. We thus introduce a dynamic gating network on top of the low-rank adaptation method, in order to decide which decoder layer should employ adaptation. The dynamic adaptation network is optimized end-to-end using rate-distortion loss. Our proposed method exhibits universality across diverse image datasets. Extensive results demonstrate that this paradigm significantly mitigates the domain gap, surpassing non-adaptive methods with an average BD-rate improvement of approximately $19\%$ across out-of-domain images. Furthermore, it outperforms the most advanced instance adaptive methods by roughly $5\%$ BD-rate. Ablation studies confirm our method's ability to universally enhance various image compression architectures.
CoNIC Challenge: Pushing the Frontiers of Nuclear Detection, Segmentation, Classification and Counting
Mar 14, 2023



Nuclear detection, segmentation and morphometric profiling are essential in helping us further understand the relationship between histology and patient outcome. To drive innovation in this area, we setup a community-wide challenge using the largest available dataset of its kind to assess nuclear segmentation and cellular composition. Our challenge, named CoNIC, stimulated the development of reproducible algorithms for cellular recognition with real-time result inspection on public leaderboards. We conducted an extensive post-challenge analysis based on the top-performing models using 1,658 whole-slide images of colon tissue. With around 700 million detected nuclei per model, associated features were used for dysplasia grading and survival analysis, where we demonstrated that the challenge's improvement over the previous state-of-the-art led to significant boosts in downstream performance. Our findings also suggest that eosinophils and neutrophils play an important role in the tumour microevironment. We release challenge models and WSI-level results to foster the development of further methods for biomarker discovery.
Federated contrastive learning models for prostate cancer diagnosis and Gleason grading
Feb 17, 2023
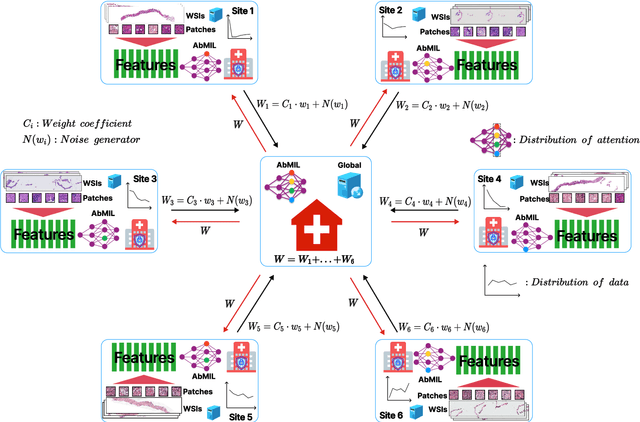
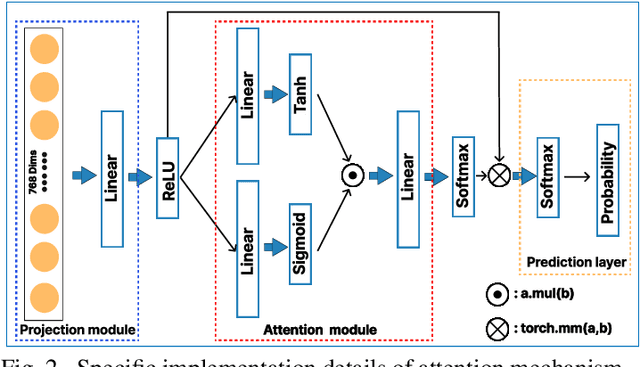
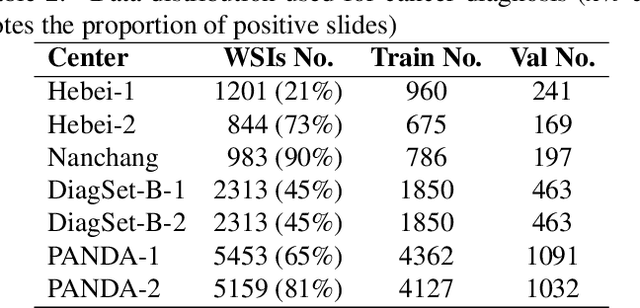
The application effect of artificial intelligence (AI) in the field of medical imaging is remarkable. Robust AI model training requires large datasets, but data collection faces communication, ethics, and privacy protection constraints. Fortunately, federated learning can solve the above problems by coordinating multiple clients to train the model without sharing the original data. In this study, we design a federated contrastive learning framework (FCL) for large-scale pathology images and the heterogeneity challenges. It enhances the model's generalization ability by maximizing the attention consistency between the local client and server models. To alleviate the privacy leakage problem when transferring parameters and verify the robustness of FCL, we use differential privacy to further protect the model by adding noise. We evaluate the effectiveness of FCL on the cancer diagnosis task and Gleason grading task on 19,635 prostate cancer WSIs from multiple clients. In the diagnosis task, the average AUC of 7 clients is 95% when the categories are relatively balanced, and our FCL achieves 97%. In the Gleason grading task, the average Kappa of 6 clients is 0.74, and the Kappa of FCL reaches 0.84. Furthermore, we also validate the robustness of the model on external datasets(one public dataset and two private datasets). In addition, to better explain the classification effect of the model, we show whether the model focuses on the lesion area by drawing a heatmap. Finally, FCL brings a robust, accurate, low-cost AI training model to biomedical research, effectively protecting medical data privacy.