 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Cross-Layer Transcoders Replace Vision Transformer Activations? An Interpretable Perspective on Vision
Apr 14, 2026Understanding the internal activations of Vision Transformers (ViTs) is critical for building interpretable and trustworthy models. While Sparse Autoencoders (SAEs) have been used to extract human-interpretable features, they operate on individual layers and fail to capture the cross-layer computational structure of Transformers, as well as the relative significance of each layer in forming the last-layer representation. Alternatively, we introduce the adoption of Cross-Layer Transcoders (CLTs) as reliable, sparse, and depth-aware proxy models for MLP blocks in ViTs. CLTs use an encoder-decoder scheme to reconstruct each post-MLP activation from learned sparse embeddings of preceding layers, yielding a linear decomposition that transforms the final representation of ViTs from an opaque embedding into an additive, layer-resolved construction that enables faithful attribution and process-level interpretability. We train CLTs on CLIP ViT-B/32 and ViT-B/16 across CIFAR-100, COCO, and ImageNet-100. We show that CLTs achieve high reconstruction fidelity with post-MLP activations while preserving and even improving, in some cases, CLIP zero-shot classification accuracy. In terms of interpretability, we show that the cross-layer contribution scores provide faithful attribution, revealing that the final representation is concentrated in a smaller set of dominant layer-wise terms whose removal degrades performance and whose retention largely preserves it. These results showcase the significance of adopting CLTs as an alternative interpretable proxy of ViTs in the vision domain.
VisRef: Visual Refocusing while Thinking Improves Test-Time Scaling in Multi-Modal Large Reasoning Models
Feb 27, 2026Advances in large reasoning models have shown strong performance on complex reasoning tasks by scaling test-time compute through extended reasoning. However, recent studies observe that in vision-dependent tasks, extended textual reasoning at inference time can degrade performance as models progressively lose attention to visual tokens and increasingly rely on textual priors alone. To address this, prior works use reinforcement learning (RL)-based fine-tuning to route visual tokens or employ refocusing mechanisms during reasoning. While effective, these methods are computationally expensive, requiring large-scale data generation and policy optimization. To leverage the benefits of test-time compute without additional RL fine-tuning, we propose VisRef, a visually grounded test-time scaling framework. Our key idea is to actively guide the reasoning process by re-injecting a coreset of visual tokens that are semantically relevant to the reasoning context while remaining diverse and globally representative of the image, enabling more grounded multi-modal reasoning. Experiments on three visual reasoning benchmarks with state-of-the-art multi-modal large reasoning models demonstrate that, under fixed test-time compute budgets, VisRef consistently outperforms existing test-time scaling approaches by up to 6.4%.
Decoupling Vision and Language: Codebook Anchored Visual Adaptation
Feb 23, 2026Large Vision-Language Models (LVLMs) use their vision encoders to translate images into representations for downstream reasoning, but the encoders often underperform in domain-specific visual tasks such as medical image diagnosis or fine-grained classification, where representation errors can cascade through the language model, leading to incorrect responses. Existing adaptation methods modify the continuous feature interface between encoder and language model through projector tuning or other parameter-efficient updates, which still couples the two components and requires re-alignment whenever the encoder changes. We introduce CRAFT (Codebook RegulAted Fine-Tuning), a lightweight method that fine-tunes the encoder using a discrete codebook that anchors visual representations to a stable token space, achieving domain adaptation without modifying other parts of the model. This decoupled design allows the adapted encoder to seamlessly boost the performance of LVLMs with different language architectures, as long as they share the same codebook. Empirically, CRAFT achieves an average gain of 13.51% across 10 domain-specific benchmarks such as VQARAD and PlantVillage, while preserving the LLM's linguistic capabilities and outperforming peer methods that operate on continuous tokens.
T3D: Few-Step Diffusion Language Models via Trajectory Self-Distillation with Direct Discriminative Optimization
Feb 13, 2026Diffusion large language models (DLLMs) have the potential to enable fast text generation by decoding multiple tokens in parallel. However, in practice, their inference efficiency is constrained by the need for many refinement steps, while aggressively reducing the number of steps leads to a substantial degradation in generation quality. To alleviate this, we propose a trajectory self-distillation framework that improves few-step decoding by distilling the model's own generative trajectories. We incorporate Direct Discriminative Optimization (DDO), a reverse-KL objective that promotes mode-seeking distillation and encourages the student to concentrate on high-probability teacher modes. Across benchmarks, our approach consistently outperforms strong few-step baselines and standard training under tight step budgets. Although full-step decoding remains superior, we substantially narrow the gap, establishing a strong foundation towards practical few-step DLLMs. The source code is available at https://github.com/Tyrion58/T3D.
Token-Level Uncertainty Estimation for Large Language Model Reasoning
May 16, 2025While Large Language Models (LLMs) have demonstrated impressive capabilities, their output quality remains inconsistent across various application scenarios, making it difficult to identify trustworthy responses, especially in complex tasks requiring multi-step reasoning. In this paper, we propose a token-level uncertainty estimation framework to enable LLMs to self-assess and self-improve their generation quality in mathematical reasoning. Specifically, we introduce low-rank random weight perturbation to LLM decoding, generating predictive distributions that we use to estimate token-level uncertainties. We then aggregate these uncertainties to reflect semantic uncertainty of the generated sequences. Experiments on mathematical reasoning datasets of varying difficulty demonstrate that our token-level uncertainty metrics strongly correlate with answer correctness and model robustness. Additionally, we explore using uncertainty to directly enhance the model's reasoning performance through multiple generations and the particle filtering algorithm. Our approach consistently outperforms existing uncertainty estimation methods, establishing effective uncertainty estimation as a valuable tool for both evaluating and improving reasoning generation in LLMs.
Optimal Transport-Guided Source-Free Adaptation for Face Anti-Spoofing
Mar 29, 2025Developing a face anti-spoofing model that meets the security requirements of clients worldwide is challenging due to the domain gap between training datasets and diverse end-user test data. Moreover, for security and privacy reasons, it is undesirable for clients to share a large amount of their face data with service providers. In this work, we introduce a novel method in which the face anti-spoofing model can be adapted by the client itself to a target domain at test time using only a small sample of data while keeping model parameters and training data inaccessible to the client. Specifically, we develop a prototype-based base model and an optimal transport-guided adaptor that enables adaptation in either a lightweight training or training-free fashion, without updating base model's parameters. Furthermore, we propose geodesic mixup, an optimal transport-based synthesis method that generates augmented training data along the geodesic path between source prototypes and target data distribution. This allows training a lightweight classifier to effectively adapt to target-specific characteristics while retaining essential knowledge learned from the source domain. In cross-domain and cross-attack settings, compared with recent methods, our method achieves average relative improvements of 19.17% in HTER and 8.58% in AUC, respectively.
Show and Segment: Universal Medical Image Segmentation via In-Context Learning
Mar 25, 2025Medical image segmentation remains challenging due to the vast diversity of anatomical structures, imaging modalities, and segmentation tasks. While deep learning has made significant advances, current approaches struggle to generalize as they require task-specific training or fine-tuning on unseen classes. We present Iris, a novel In-context Reference Image guided Segmentation framework that enables flexible adaptation to novel tasks through the use of reference examples without fine-tuning. At its core, Iris features a lightweight context task encoding module that distills task-specific information from reference context image-label pairs. This rich context embedding information is used to guide the segmentation of target objects. By decoupling task encoding from inference, Iris supports diverse strategies from one-shot inference and context example ensemble to object-level context example retrieval and in-context tuning. Through comprehensive evaluation across twelve datasets, we demonstrate that Iris performs strongly compared to task-specific models on in-distribution tasks. On seven held-out datasets, Iris shows superior generalization to out-of-distribution data and unseen classes. Further, Iris's task encoding module can automatically discover anatomical relationships across datasets and modalities, offering insights into medical objects without explicit anatomical supervision.
The Hidden Life of Tokens: Reducing Hallucination of Large Vision-Language Models via Visual Information Steering
Feb 05, 2025



Large Vision-Language Models (LVLMs) can reason effectively over both textual and visual inputs, but they tend to hallucinate syntactically coherent yet visually ungrounded contents. In this paper, we investigate the internal dynamics of hallucination by examining the tokens logits rankings throughout the generation process, revealing three key patterns in how LVLMs process information: (1) gradual visual information loss -- visually grounded tokens gradually become less favored throughout generation, and (2) early excitation -- semantically meaningful tokens achieve peak activation in the layers earlier than the final layer. (3) hidden genuine information -- visually grounded tokens though not being eventually decided still retain relatively high rankings at inference. Based on these insights, we propose VISTA (Visual Information Steering with Token-logit Augmentation), a training-free inference-time intervention framework that reduces hallucination while promoting genuine information. VISTA works by combining two complementary approaches: reinforcing visual information in activation space and leveraging early layer activations to promote semantically meaningful decoding. Compared to existing methods, VISTA requires no external supervision and is applicable to various decoding strategies. Extensive experiments show that VISTA on average reduces hallucination by abount 40% on evaluated open-ended generation task, and it consistently outperforms existing methods on four benchmarks across four architectures under three decoding strategies.
MLLM-as-a-Judge for Image Safety without Human Labeling
Dec 31, 2024



Image content safety has become a significant challenge with the rise of visual media on online platforms. Meanwhile, in the age of AI-generated content (AIGC), many image generation models are capable of producing harmful content, such as images containing sexual or violent material. Thus, it becomes crucial to identify such unsafe images based on established safety rules. Pre-trained Multimodal Large Language Models (MLLMs) offer potential in this regard, given their strong pattern recognition abilities. Existing approaches typically fine-tune MLLMs with human-labeled datasets, which however brings a series of drawbacks. First, relying on human annotators to label data following intricate and detailed guidelines is both expensive and labor-intensive. Furthermore, users of safety judgment systems may need to frequently update safety rules, making fine-tuning on human-based annotation more challenging. This raises the research question: Can we detect unsafe images by querying MLLMs in a zero-shot setting using a predefined safety constitution (a set of safety rules)? Our research showed that simply querying pre-trained MLLMs does not yield satisfactory results. This lack of effectiveness stems from factors such as the subjectivity of safety rules, the complexity of lengthy constitutions, and the inherent biases in the models. To address these challenges, we propose a MLLM-based method includes objectifying safety rules, assessing the relevance between rules and images, making quick judgments based on debiased token probabilities with logically complete yet simplified precondition chains for safety rules, and conducting more in-depth reasoning with cascaded chain-of-thought processes if necessary. Experiment results demonstrate that our method is highly effective for zero-shot image safety judgment tasks.
Implicit In-context Learning
May 23, 2024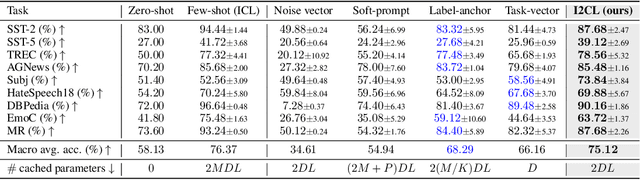
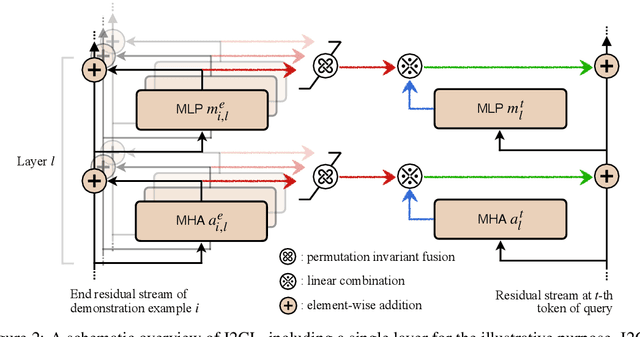

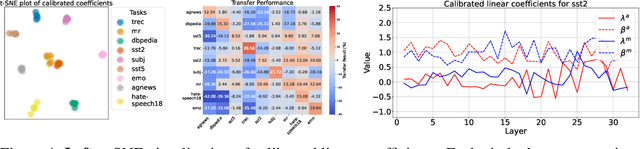
In-context Learning (ICL) empowers large language models (LLMs) to adapt to unseen tasks during inference by prefixing a few demonstration examples prior to test queries. Despite its versatility, ICL incurs substantial computational and memory overheads compared to zero-shot learning and is susceptible to the selection and order of demonstration examples. In this work, we introduce Implicit In-context Learning (I2CL), an innovative paradigm that addresses the challenges associated with traditional ICL by absorbing demonstration examples within the activation space. I2CL first generates a condensed vector representation, namely a context vector, from the demonstration examples. It then integrates the context vector during inference by injecting a linear combination of the context vector and query activations into the model's residual streams. Empirical evaluation on nine real-world tasks across three model architectures demonstrates that I2CL achieves few-shot performance with zero-shot cost and exhibits robustness against the variation of demonstration examples. Furthermore, I2CL facilitates a novel representation of "task-ids", enhancing task similarity detection and enabling effective transfer learning. We provide a comprehensive analysis of I2CL, offering deeper insights into its mechanisms and broader implications for ICL. The source code is available at: https://github.com/LzVv123456/I2CL.