 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLLM-as-a-Judge for Image Safety without Human Labeling
Dec 31, 2024



Image content safety has become a significant challenge with the rise of visual media on online platforms. Meanwhile, in the age of AI-generated content (AIGC), many image generation models are capable of producing harmful content, such as images containing sexual or violent material. Thus, it becomes crucial to identify such unsafe images based on established safety rules. Pre-trained Multimodal Large Language Models (MLLMs) offer potential in this regard, given their strong pattern recognition abilities. Existing approaches typically fine-tune MLLMs with human-labeled datasets, which however brings a series of drawbacks. First, relying on human annotators to label data following intricate and detailed guidelines is both expensive and labor-intensive. Furthermore, users of safety judgment systems may need to frequently update safety rules, making fine-tuning on human-based annotation more challenging. This raises the research question: Can we detect unsafe images by querying MLLMs in a zero-shot setting using a predefined safety constitution (a set of safety rules)? Our research showed that simply querying pre-trained MLLMs does not yield satisfactory results. This lack of effectiveness stems from factors such as the subjectivity of safety rules, the complexity of lengthy constitutions, and the inherent biases in the models. To address these challenges, we propose a MLLM-based method includes objectifying safety rules, assessing the relevance between rules and images, making quick judgments based on debiased token probabilities with logically complete yet simplified precondition chains for safety rules, and conducting more in-depth reasoning with cascaded chain-of-thought processes if necessary. Experiment results demonstrate that our method is highly effective for zero-shot image safety judgment tasks.
Class-RAG: Content Moderation with Retrieval Augmented Generation
Oct 18, 2024



Robust content moderation classifiers are essential for the safety of Generative AI systems. Content moderation, or safety classification, is notoriously ambiguous: differences between safe and unsafe inputs are often extremely subtle, making it difficult for classifiers (and indeed, even humans) to properly distinguish violating vs. benign samples without further context or explanation. Furthermore, as these technologies are deployed across various applications and audiences, scaling risk discovery and mitigation through continuous model fine-tuning becomes increasingly challenging and costly. To address these challenges, we propose a Classification approach employing Retrieval-Augmented Generation (Class-RAG). Class-RAG extends the capability of its base LLM through access to a retrieval library which can be dynamically updated to enable semantic hotfixing for immediate, flexible risk mitigation. Compared to traditional fine-tuned models, Class-RAG demonstrates flexibility and transparency in decision-making. As evidenced by empirical studies, Class-RAG outperforms on classification and is more robust against adversarial attack. Besides, our findings suggest that Class-RAG performance scales with retrieval library size, indicating that increasing the library size is a viable and low-cost approach to improve content moderation.
Answering Complex Open-domain Questions Through Iterative Query Generation
Oct 15, 2019

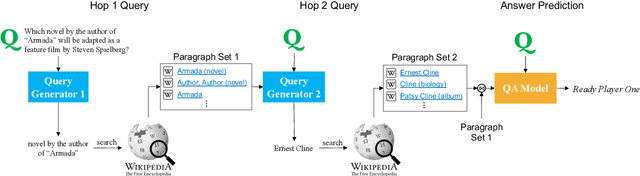
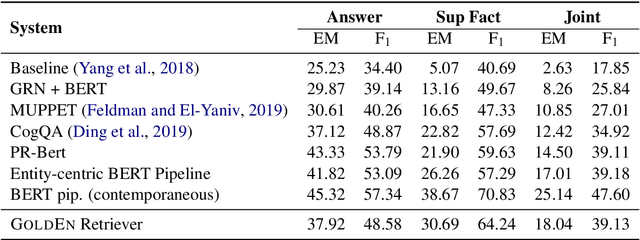
It is challenging for current one-step retrieve-and-read question answering (QA) systems to answer questions like "Which novel by the author of 'Armada' will be adapted as a feature film by Steven Spielberg?" because the question seldom contains retrievable clues about the missing entity (here, the author). Answering such a question requires multi-hop reasoning where one must gather information about the missing entity (or facts) to proceed with further reasoning. We present GoldEn (Gold Entity) Retriever, which iterates between reading context and retrieving more supporting documents to answer open-domain multi-hop questions. Instead of using opaque and computationally expensive neural retrieval models, GoldEn Retriever generates natural language search queries given the question and available context, and leverages off-the-shelf information retrieval systems to query for missing entities. This allows GoldEn Retriever to scale up efficiently for open-domain multi-hop reasoning while maintaining interpretability. We evaluate GoldEn Retriever on the recently proposed open-domain multi-hop QA dataset, HotpotQA, and demonstrate that it outperforms the best previously published model despite not using pretrained language models such as BERT.
Generating Thematic Chinese Poetry using Conditional Variational Autoencoders with Hybrid Decoders
May 25, 2018
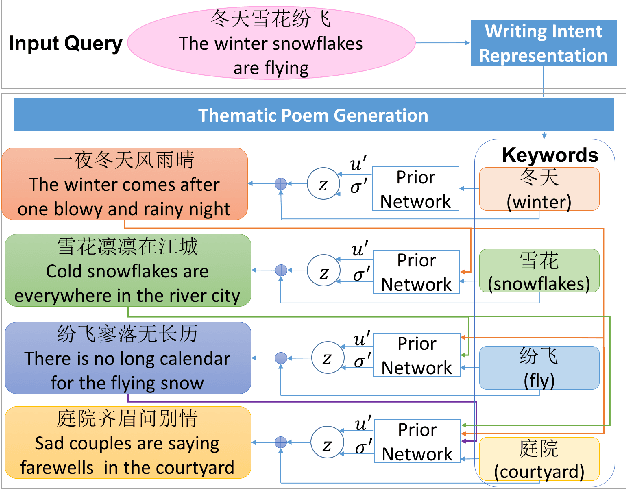
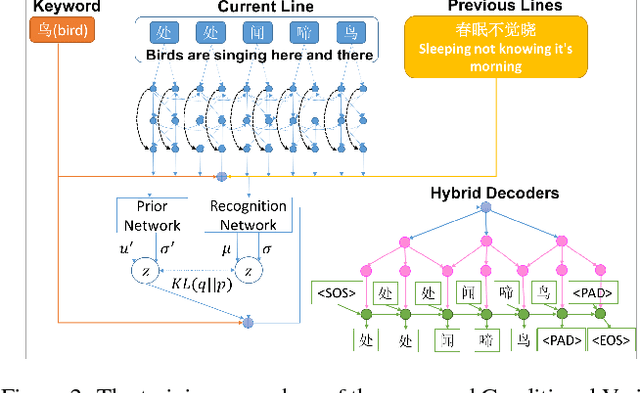
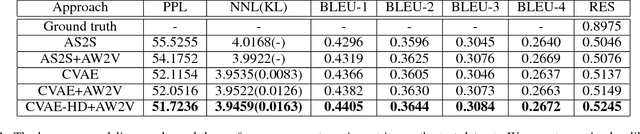
Computer poetry generation is our first step towards computer writing. Writing must have a theme. The current approaches of using sequence-to-sequence models with attention often produce non-thematic poems. We present a novel conditional variational autoencoder with a hybrid decoder adding the deconvolutional neural networks to the general recurrent neural networks to fully learn topic information via latent variables. This approach significantly improves the relevance of the generated poems by representing each line of the poem not only in a context-sensitive manner but also in a holistic way that is highly related to the given keyword and the learned topic. A proposed augmented word2vec model further improves the rhythm and symmetry. Tests show that the generated poems by our approach are mostly satisfying with regulated rules and consistent themes, and 73.42% of them receive an Overall score no less than 3 (the highest score is 5).