 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTROVE: A Challenge for Fine-Grained Text Provenance via Source Sentence Tracing and Relationship Classification
Mar 19, 2025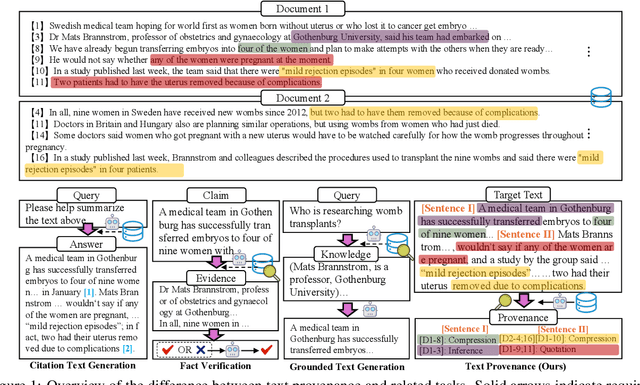
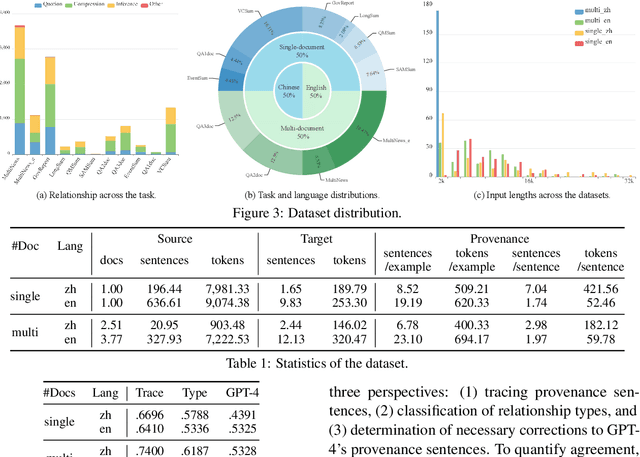
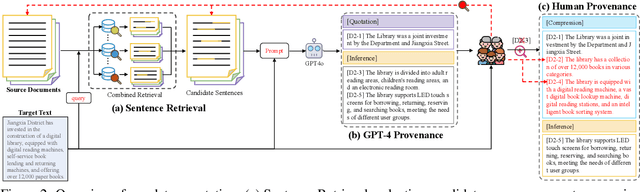
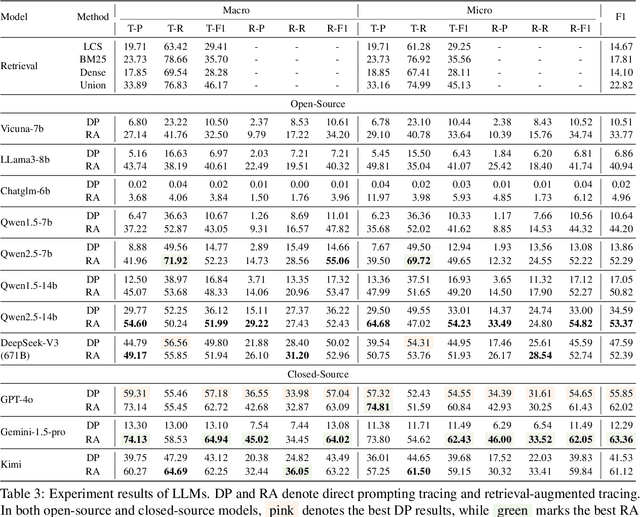
LLMs have achieved remarkable fluency and coherence in text generation, yet their widespread adoption has raised concerns about content reliability and accountability. In high-stakes domains such as healthcare, law, and news, it is crucial to understand where and how the content is created. To address this, we introduce the Text pROVEnance (TROVE) challenge, designed to trace each sentence of a target text back to specific source sentences within potentially lengthy or multi-document inputs. Beyond identifying sources, TROVE annotates the fine-grained relationships (quotation, compression, inference, and others), providing a deep understanding of how each target sentence is formed. To benchmark TROVE, we construct our dataset by leveraging three public datasets covering 11 diverse scenarios (e.g., QA and summarization) in English and Chinese, spanning source texts of varying lengths (0-5k, 5-10k, 10k+), emphasizing the multi-document and long-document settings essential for provenance. To ensure high-quality data, we employ a three-stage annotation process: sentence retrieval, GPT provenance, and human provenance. We evaluate 11 LLMs under direct prompting and retrieval-augmented paradigms, revealing that retrieval is essential for robust performance, larger models perform better in complex relationship classification, and closed-source models often lead, yet open-source models show significant promise, particularly with retrieval augmentation.
Merge, Ensemble, and Cooperate! A Survey on Collaborative Strategies in the Era of Large Language Models
Jul 08, 2024

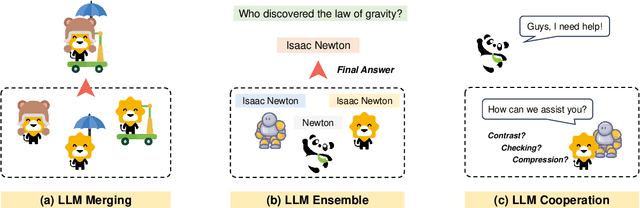
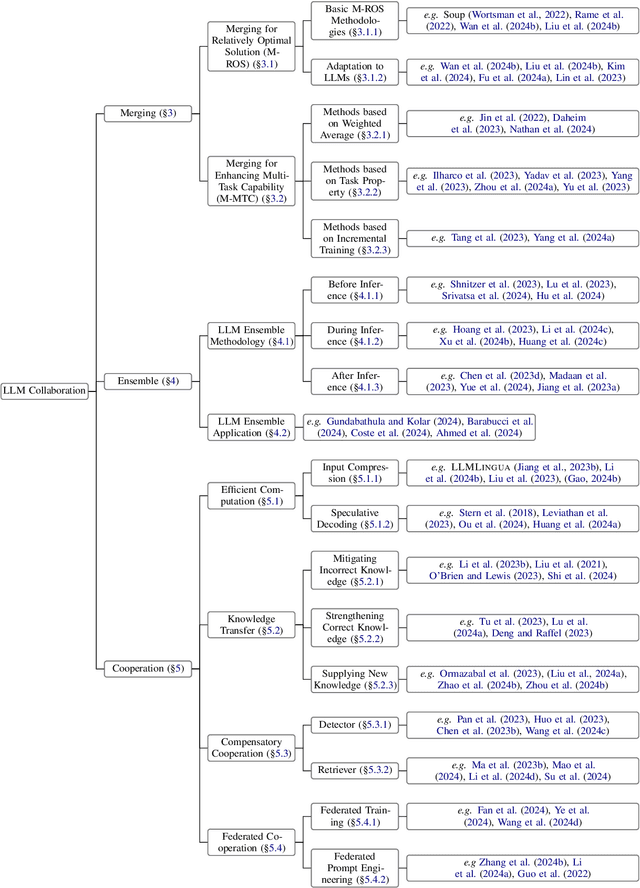
The remarkable success of Large Language Models (LLMs) has ushered natural language processing (NLP) research into a new era. Despite their diverse capabilities, LLMs trained on different corpora exhibit varying strengths and weaknesses, leading to challenges in maximizing their overall efficiency and versatility. To address these challenges, recent studies have explored collaborative strategies for LLMs. This paper provides a comprehensive overview of this emerging research area, highlighting the motivation behind such collaborations. Specifically, we categorize collaborative strategies into three primary approaches: Merging, Ensemble, and Cooperation. Merging involves integrating multiple LLMs in the parameter space. Ensemble combines the outputs of various LLMs. Cooperation} leverages different LLMs to allow full play to their diverse capabilities for specific tasks. We provide in-depth introductions to these methods from different perspectives and discuss their potential applications. Additionally, we outline future research directions, hoping this work will catalyze further studies on LLM collaborations and paving the way for advanced NLP applications.
Deep Separable Spatiotemporal Learning for Fast Dynamic Cardiac MRI
Feb 24, 2024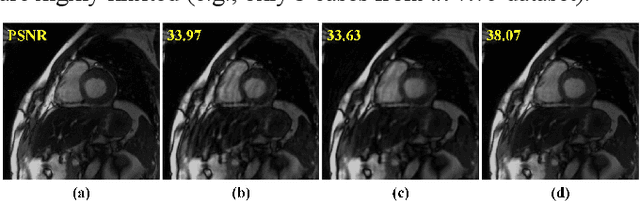
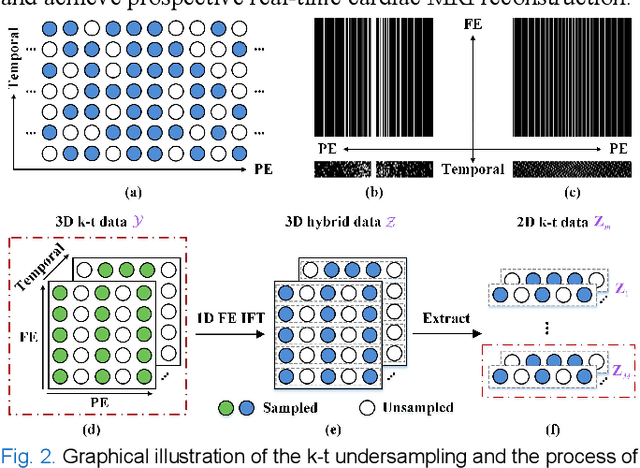
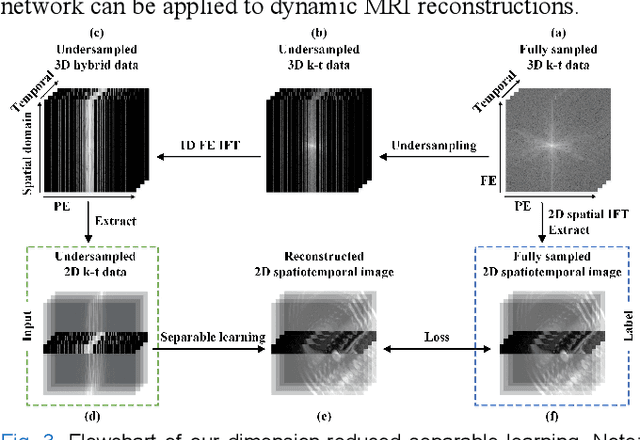
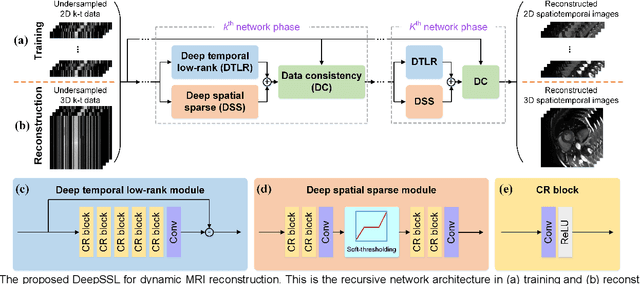
Dynamic magnetic resonance imaging (MRI) plays an indispensable role in cardiac diagnosis. To enable fast imaging, the k-space data can be undersampled but the image reconstruction poses a great challenge of high-dimensional processing. This challenge leads to necessitate extensive training data in many deep learning reconstruction methods. This work proposes a novel and efficient approach, leveraging a dimension-reduced separable learning scheme that excels even with highly limited training data. We further integrate it with spatiotemporal priors to develop a Deep Separable Spatiotemporal Learning network (DeepSSL), which unrolls an iteration process of a reconstruction model with both temporal low-rankness and spatial sparsity. Intermediate outputs are visualized to provide insights into the network's behavior and enhance its interpretability. Extensive results on cardiac cine datasets show that the proposed DeepSSL is superior to the state-of-the-art methods visually and quantitatively, while reducing the demand for training cases by up to 75%. And its preliminary adaptability to cardiac patients has been verified through experienced radiologists' and cardiologists' blind reader study. Additionally, DeepSSL also benefits for achieving the downstream task of cardiac segmentation with higher accuracy and shows robustness in prospective real-time cardiac MRI.
A plug-and-play synthetic data deep learning for undersampled magnetic resonance image reconstruction
Sep 13, 2023Magnetic resonance imaging (MRI) plays an important role in modern medical diagnostic but suffers from prolonged scan time. Current deep learning methods for undersampled MRI reconstruction exhibit good performance in image de-aliasing which can be tailored to the specific kspace undersampling scenario. But it is very troublesome to configure different deep networks when the sampling setting changes. In this work, we propose a deep plug-and-play method for undersampled MRI reconstruction, which effectively adapts to different sampling settings. Specifically, the image de-aliasing prior is first learned by a deep denoiser trained to remove general white Gaussian noise from synthetic data. Then the learned deep denoiser is plugged into an iterative algorithm for image reconstruction. Results on in vivo data demonstrate that the proposed method provides nice and robust accelerated image reconstruction performance under different undersampling patterns and sampling rates, both visually and quantitatively.
GPT4RoI: Instruction Tuning Large Language Model on Region-of-Interest
Jul 07, 2023



Instruction tuning large language model (LLM) on image-text pairs has achieved unprecedented vision-language multimodal abilities. However, their vision-language alignments are only built on image-level, the lack of region-level alignment limits their advancements to fine-grained multimodal understanding. In this paper, we propose instruction tuning on region-of-interest. The key design is to reformulate the bounding box as the format of spatial instruction. The interleaved sequences of visual features extracted by the spatial instruction and the language embedding are input to LLM, and trained on the transformed region-text data in instruction tuning format. Our region-level vision-language model, termed as GPT4RoI, brings brand new conversational and interactive experience beyond image-level understanding. (1) Controllability: Users can interact with our model by both language and spatial instructions to flexibly adjust the detail level of the question. (2) Capacities: Our model supports not only single-region spatial instruction but also multi-region. This unlocks more region-level multimodal capacities such as detailed region caption and complex region reasoning. (3) Composition: Any off-the-shelf object detector can be a spatial instruction provider so as to mine informative object attributes from our model, like color, shape, material, action, relation to other objects, etc. The code, data, and demo can be found at https://github.com/jshilong/GPT4RoI.
CFSum: A Coarse-to-Fine Contribution Network for Multimodal Summarization
Jul 06, 2023



Multimodal summarization usually suffers from the problem that the contribution of the visual modality is unclear. Existing multimodal summarization approaches focus on designing the fusion methods of different modalities, while ignoring the adaptive conditions under which visual modalities are useful. Therefore, we propose a novel Coarse-to-Fine contribution network for multimodal Summarization (CFSum) to consider different contributions of images for summarization. First, to eliminate the interference of useless images, we propose a pre-filter module to abandon useless images. Second, to make accurate use of useful images, we propose two levels of visual complement modules, word level and phrase level. Specifically, image contributions are calculated and are adopted to guide the attention of both textual and visual modalities. Experimental results have shown that CFSum significantly outperforms multiple strong baselines on the standard benchmark. Furthermore, the analysis verifies that useful images can even help generate non-visual words which are implicitly represented in the image.
Cross Language Text Classification via Subspace Co-Regularized Multi-View Learning
Jun 27, 2012
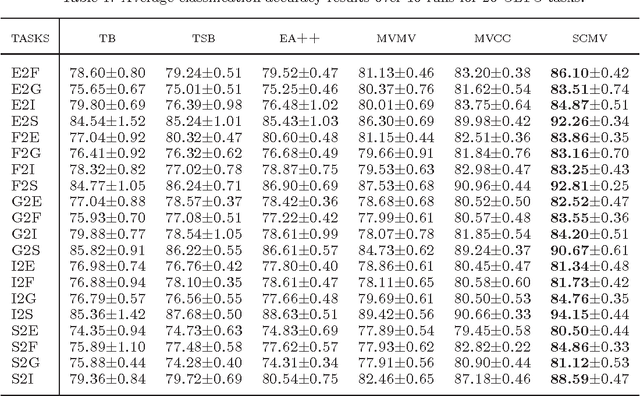

In many multilingual text classification problems, the documents in different languages often share the same set of categories. To reduce the labeling cost of training a classification model for each individual language, it is important to transfer the label knowledge gained from one language to another language by conducting cross language classification. In this paper we develop a novel subspace co-regularized multi-view learning method for cross language text classification. This method is built on parallel corpora produced by machine translation. It jointly minimizes the training error of each classifier in each language while penalizing the distance between the subspace representations of parallel documents. Our empirical study on a large set of cross language text classification tasks shows the proposed method consistently outperforms a number of inductive methods, domain adaptation methods, and multi-view learning methods.