 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Separable Spatiotemporal Learning for Fast Dynamic Cardiac MRI
Feb 24, 2024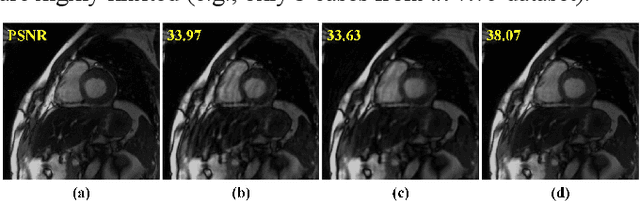
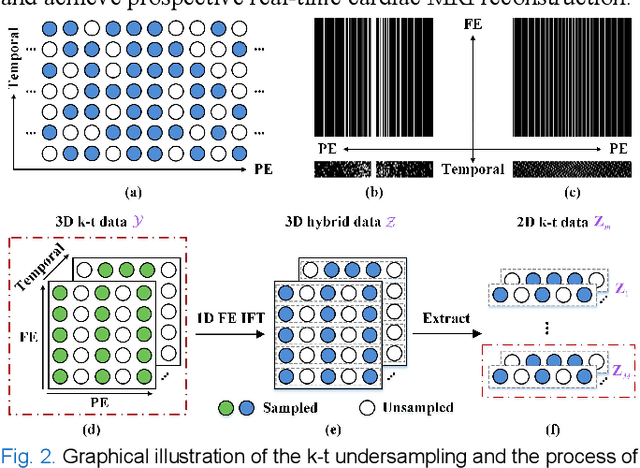
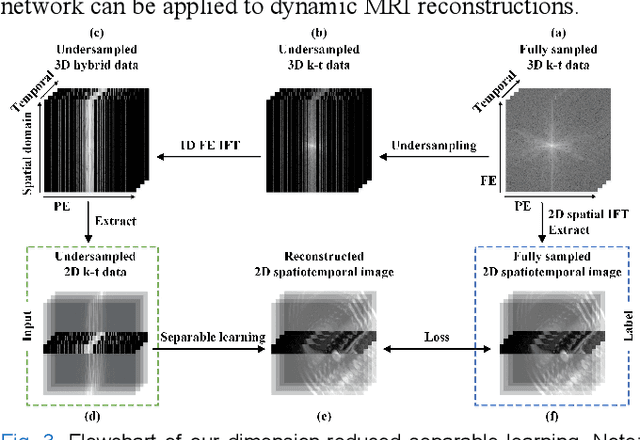
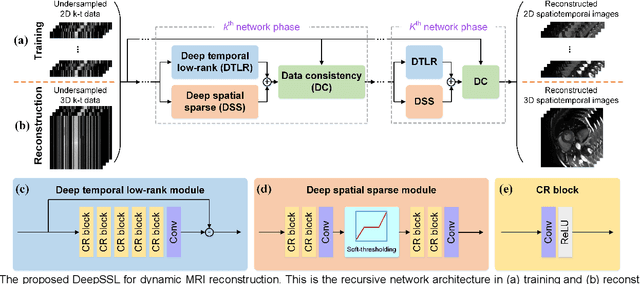
Dynamic magnetic resonance imaging (MRI) plays an indispensable role in cardiac diagnosis. To enable fast imaging, the k-space data can be undersampled but the image reconstruction poses a great challenge of high-dimensional processing. This challenge leads to necessitate extensive training data in many deep learning reconstruction methods. This work proposes a novel and efficient approach, leveraging a dimension-reduced separable learning scheme that excels even with highly limited training data. We further integrate it with spatiotemporal priors to develop a Deep Separable Spatiotemporal Learning network (DeepSSL), which unrolls an iteration process of a reconstruction model with both temporal low-rankness and spatial sparsity. Intermediate outputs are visualized to provide insights into the network's behavior and enhance its interpretability. Extensive results on cardiac cine datasets show that the proposed DeepSSL is superior to the state-of-the-art methods visually and quantitatively, while reducing the demand for training cases by up to 75%. And its preliminary adaptability to cardiac patients has been verified through experienced radiologists' and cardiologists' blind reader study. Additionally, DeepSSL also benefits for achieving the downstream task of cardiac segmentation with higher accuracy and shows robustness in prospective real-time cardiac MRI.
Deep Structured Feature Networks for Table Detection and Tabular Data Extraction from Scanned Financial Document Images
Feb 20, 2021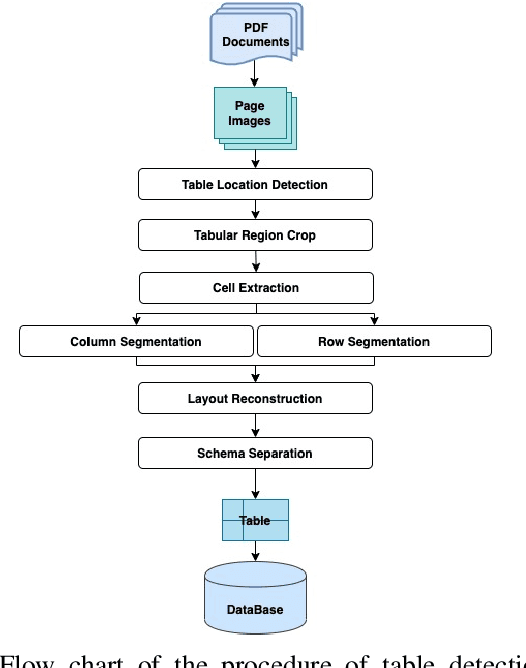
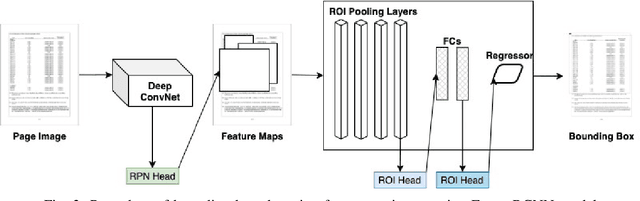
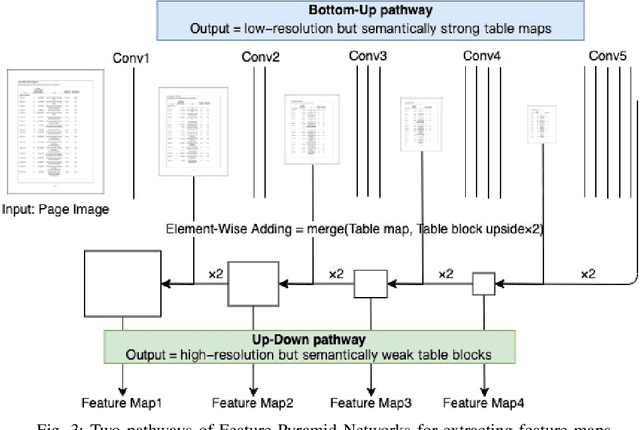
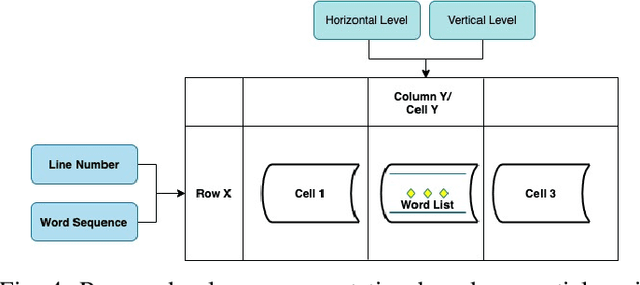
Automatic table detection in PDF documents has achieved a great success but tabular data extraction are still challenging due to the integrity and noise issues in detected table areas. The accurate data extraction is extremely crucial in finance area. Inspired by this, the aim of this research is proposing an automated table detection and tabular data extraction from financial PDF documents. We proposed a method that consists of three main processes, which are detecting table areas with a Faster R-CNN (Region-based Convolutional Neural Network) model with Feature Pyramid Network (FPN) on each page image, extracting contents and structures by a compounded layout segmentation technique based on optical character recognition (OCR) and formulating regular expression rules for table header separation. The tabular data extraction feature is embedded with rule-based filtering and restructuring functions that are highly scalable. We annotate a new Financial Documents dataset with table regions for the experiment. The excellent table detection performance of the detection model is obtained from our customized dataset. The main contributions of this paper are proposing the Financial Documents dataset with table-area annotations, the superior detection model and the rule-based layout segmentation technique for the tabular data extraction from PDF files.