 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Singers: A Review of Deep-Learning-based Singing Voice Synthesis Approaches
Jan 20, 2026Recent advances in singing voice synthesis (SVS) have attracted substantial attention from both academia and industry. With the advent of large language models and novel generative paradigms, producing controllable, high-fidelity singing voices has become an attainable goal. Yet the field still lacks a comprehensive survey that systematically analyzes deep-learning-based singing voice synthesis systems and their enabling technologies. To address the aforementioned issue, this survey first categorizes existing systems by task type and then organizes current architectures into two major paradigms: cascaded and end-to-end approaches. Moreover, we provide an in-depth analysis of core technologies, covering singing modeling and control techniques. Finally, we review relevant datasets, annotation tools, and evaluation benchmarks that support training and assessment. In appendix, we introduce training strategies and further discussion of SVS. This survey provides an up-to-date review of the literature on SVS models, which would be a useful reference for both researchers and engineers. Related materials are available at https://github.com/David-Pigeon/SyntheticSingers.
STARS: A Unified Framework for Singing Transcription, Alignment, and Refined Style Annotation
Jul 09, 2025Recent breakthroughs in singing voice synthesis (SVS) have heightened the demand for high-quality annotated datasets, yet manual annotation remains prohibitively labor-intensive and resource-intensive. Existing automatic singing annotation (ASA) methods, however, primarily tackle isolated aspects of the annotation pipeline. To address this fundamental challenge, we present STARS, which is, to our knowledge, the first unified framework that simultaneously addresses singing transcription, alignment, and refined style annotation. Our framework delivers comprehensive multi-level annotations encompassing: (1) precise phoneme-audio alignment, (2) robust note transcription and temporal localization, (3) expressive vocal technique identification, and (4) global stylistic characterization including emotion and pace. The proposed architecture employs hierarchical acoustic feature processing across frame, word, phoneme, note, and sentence levels. The novel non-autoregressive local acoustic encoders enable structured hierarchical representation learning. Experimental validation confirms the framework's superior performance across multiple evaluation dimensions compared to existing annotation approaches. Furthermore, applications in SVS training demonstrate that models utilizing STARS-annotated data achieve significantly enhanced perceptual naturalness and precise style control. This work not only overcomes critical scalability challenges in the creation of singing datasets but also pioneers new methodologies for controllable singing voice synthesis. Audio samples are available at https://gwx314.github.io/stars-demo/.
Speech Quality Assessment Model Based on Mixture of Experts: System-Level Performance Enhancement and Utterance-Level Challenge Analysis
Jul 08, 2025Automatic speech quality assessment plays a crucial role in the development of speech synthesis systems, but existing models exhibit significant performance variations across different granularity levels of prediction tasks. This paper proposes an enhanced MOS prediction system based on self-supervised learning speech models, incorporating a Mixture of Experts (MoE) classification head and utilizing synthetic data from multiple commercial generation models for data augmentation. Our method builds upon existing self-supervised models such as wav2vec2, designing a specialized MoE architecture to address different types of speech quality assessment tasks. We also collected a large-scale synthetic speech dataset encompassing the latest text-to-speech, speech conversion, and speech enhancement systems. However, despite the adoption of the MoE architecture and expanded dataset, the model's performance improvements in sentence-level prediction tasks remain limited. Our work reveals the limitations of current methods in handling sentence-level quality assessment, provides new technical pathways for the field of automatic speech quality assessment, and also delves into the fundamental causes of performance differences across different assessment granularities.
TCSinger 2: Customizable Multilingual Zero-shot Singing Voice Synthesis
May 20, 2025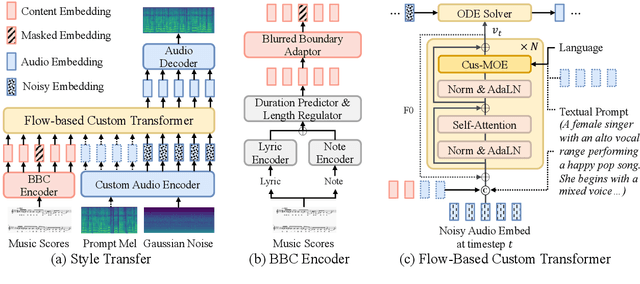
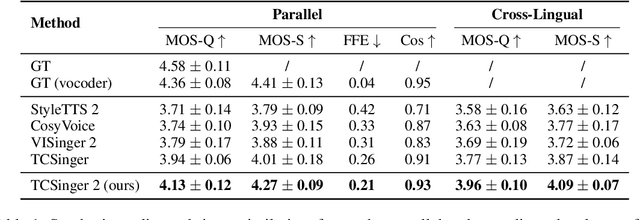
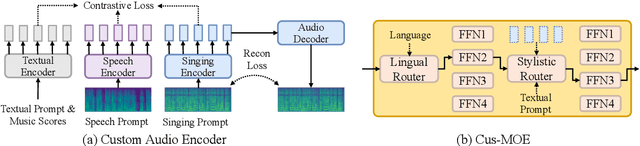
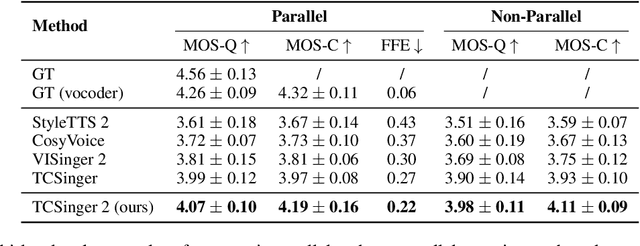
Customizable multilingual zero-shot singing voice synthesis (SVS) has various potential applications in music composition and short video dubbing. However, existing SVS models overly depend on phoneme and note boundary annotations, limiting their robustness in zero-shot scenarios and producing poor transitions between phonemes and notes. Moreover, they also lack effective multi-level style control via diverse prompts. To overcome these challenges, we introduce TCSinger 2, a multi-task multilingual zero-shot SVS model with style transfer and style control based on various prompts. TCSinger 2 mainly includes three key modules: 1) Blurred Boundary Content (BBC) Encoder, predicts duration, extends content embedding, and applies masking to the boundaries to enable smooth transitions. 2) Custom Audio Encoder, uses contrastive learning to extract aligned representations from singing, speech, and textual prompts. 3) Flow-based Custom Transformer, leverages Cus-MOE, with F0 supervision, enhancing both the synthesis quality and style modeling of the generated singing voice. Experimental results show that TCSinger 2 outperforms baseline models in both subjective and objective metrics across multiple related tasks.
ISDrama: Immersive Spatial Drama Generation through Multimodal Prompting
Apr 29, 2025Multimodal immersive spatial drama generation focuses on creating continuous multi-speaker binaural speech with dramatic prosody based on multimodal prompts, with potential applications in AR, VR, and others. This task requires simultaneous modeling of spatial information and dramatic prosody based on multimodal inputs, with high data collection costs. To the best of our knowledge, our work is the first attempt to address these challenges. We construct MRSDrama, the first multimodal recorded spatial drama dataset, containing binaural drama audios, scripts, videos, geometric poses, and textual prompts. Then, we propose ISDrama, the first immersive spatial drama generation model through multimodal prompting. ISDrama comprises these primary components: 1) Multimodal Pose Encoder, based on contrastive learning, considering the Doppler effect caused by moving speakers to extract unified pose information from multimodal prompts. 2) Immersive Drama Transformer, a flow-based mamba-transformer model that generates high-quality drama, incorporating Drama-MOE to select proper experts for enhanced prosody and pose control. We also design a context-consistent classifier-free guidance strategy to coherently generate complete drama. Experimental results show that ISDrama outperforms baseline models on objective and subjective metrics. The demos and dataset are available at https://aaronz345.github.io/ISDramaDemo.
Versatile Framework for Song Generation with Prompt-based Control
Apr 29, 2025Song generation focuses on producing controllable high-quality songs based on various prompts. However, existing methods struggle to generate vocals and accompaniments with prompt-based control and proper alignment. Additionally, they fall short in supporting various tasks. To address these challenges, we introduce VersBand, a multi-task song generation framework for synthesizing high-quality, aligned songs with prompt-based control. VersBand comprises these primary models: 1) VocalBand, a decoupled model, leverages the flow-matching method for generating singing styles, pitches, and mel-spectrograms, allowing fast, high-quality vocal generation with style control. 2) AccompBand, a flow-based transformer model, incorporates the Band-MOE, selecting suitable experts for enhanced quality, alignment, and control. This model allows for generating controllable, high-quality accompaniments aligned with vocals. 3) Two generation models, LyricBand for lyrics and MelodyBand for melodies, contribute to the comprehensive multi-task song generation system, allowing for extensive control based on multiple prompts. Experimental results demonstrate that VersBand performs better over baseline models across multiple song generation tasks using objective and subjective metrics. Audio samples are available at https://aaronz345.github.io/VersBandDemo.
TCSinger: Zero-Shot Singing Voice Synthesis with Style Transfer and Multi-Level Style Control
Sep 26, 2024



Zero-shot singing voice synthesis (SVS) with style transfer and style control aims to generate high-quality singing voices with unseen timbres and styles (including singing method, emotion, rhythm, technique, and pronunciation) from audio and text prompts. However, the multifaceted nature of singing styles poses a significant challenge for effective modeling, transfer, and control. Furthermore, current SVS models often fail to generate singing voices rich in stylistic nuances for unseen singers. To address these challenges, we introduce TCSinger, the first zero-shot SVS model for style transfer across cross-lingual speech and singing styles, along with multi-level style control. Specifically, TCSinger proposes three primary modules: 1) the clustering style encoder employs a clustering vector quantization model to stably condense style information into a compact latent space; 2) the Style and Duration Language Model (S\&D-LM) concurrently predicts style information and phoneme duration, which benefits both; 3) the style adaptive decoder uses a novel mel-style adaptive normalization method to generate singing voices with enhanced details. Experimental results show that TCSinger outperforms all baseline models in synthesis quality, singer similarity, and style controllability across various tasks, including zero-shot style transfer, multi-level style control, cross-lingual style transfer, and speech-to-singing style transfer. Singing voice samples can be accessed at https://tcsinger.github.io/.
GTSinger: A Global Multi-Technique Singing Corpus with Realistic Music Scores for All Singing Tasks
Sep 26, 2024



The scarcity of high-quality and multi-task singing datasets significantly hinders the development of diverse controllable and personalized singing tasks, as existing singing datasets suffer from low quality, limited diversity of languages and singers, absence of multi-technique information and realistic music scores, and poor task suitability. To tackle these problems, we present GTSinger, a large global, multi-technique, free-to-use, high-quality singing corpus with realistic music scores, designed for all singing tasks, along with its benchmarks. Particularly, (1) we collect 80.59 hours of high-quality singing voices, forming the largest recorded singing dataset; (2) 20 professional singers across nine widely spoken languages offer diverse timbres and styles; (3) we provide controlled comparison and phoneme-level annotations of six commonly used singing techniques, helping technique modeling and control; (4) GTSinger offers realistic music scores, assisting real-world musical composition; (5) singing voices are accompanied by manual phoneme-to-audio alignments, global style labels, and 16.16 hours of paired speech for various singing tasks. Moreover, to facilitate the use of GTSinger, we conduct four benchmark experiments: technique-controllable singing voice synthesis, technique recognition, style transfer, and speech-to-singing conversion. The corpus and demos can be found at http://gtsinger.github.io. We provide the dataset and the code for processing data and conducting benchmarks at https://huggingface.co/datasets/GTSinger/GTSinger and https://github.com/GTSinger/GTSinger.