 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCardinality Estimation for High Dimensional Similarity Queries with Adaptive Bucket Probing
Apr 06, 2026In this work, we address the problem of cardinality estimation for similarity search in high-dimensional spaces. Our goal is to design a framework that is lightweight, easy to construct, and capable of providing accurate estimates with satisfying online efficiency. We leverage locality-sensitive hashing (LSH) to partition the vector space while preserving distance proximity. Building on this, we adopt the principles of classical multi-probe LSH to adaptively explore neighboring buckets, accounting for distance thresholds of varying magnitudes. To improve online efficiency, we employ progressive sampling to reduce the number of distance computations and utilize asymmetric distance computation in product quantization to accelerate distance calculations in high-dimensional spaces. In addition to handling static datasets, our framework includes updating algorithm designed to efficiently support large-scale dynamic scenarios of data updates.Experiments demonstrate that our methods can accurately estimate the cardinality of similarity queries, yielding satisfying efficiency.
GEM: A Native Graph-based Index for Multi-Vector Retrieval
Mar 20, 2026In multi-vector retrieval, both queries and data are represented as sets of high-dimensional vectors, enabling finer-grained semantic matching and improving retrieval quality over single-vector approaches. However, its practical adoption is held back by the lack of effective indexing algorithms. Existing work, attempting to reuse standard single-vector indexes, often fails to preserve multi-vector semantics or remains slow. In this work, we present GEM, a native indexing framework for multi-vector representations. The core idea is to construct a proximity graph directly over vector sets, preserving their fine-grained semantics while enabling efficient navigation. First, GEM designs a set-level clustering scheme. It associates each vector set with only its most informative clusters, effectively reducing redundancy without hurting semantic coverage. Then, it builds local proximity graphs within clusters and bridges them into a globally navigable structure. To handle the non-metric nature of multi-vector similarity, GEM decouples the graph construction metric from the final relevance score and injects semantic shortcuts to guide efficient navigation toward relevant regions. At query time, GEM launches beam search from multiple entry points and prunes paths early using cluster cues. To further enhance efficiency, a quantized distance estimation technique is used for both indexing and search. Across in-domain, out-of-domain, and multi-modal benchmarks, GEM achieves up to 16x speedup over state-of-the-art methods while matching or improving accuracy.
Breaking the Static Graph: Context-Aware Traversal for Robust Retrieval-Augmented Generation
Feb 02, 2026Recent advances in Retrieval-Augmented Generation (RAG) have shifted from simple vector similarity to structure-aware approaches like HippoRAG, which leverage Knowledge Graphs (KGs) and Personalized PageRank (PPR) to capture multi-hop dependencies. However, these methods suffer from a "Static Graph Fallacy": they rely on fixed transition probabilities determined during indexing. This rigidity ignores the query-dependent nature of edge relevance, causing semantic drift where random walks are diverted into high-degree "hub" nodes before reaching critical downstream evidence. Consequently, models often achieve high partial recall but fail to retrieve the complete evidence chain required for multi-hop queries. To address this, we propose CatRAG, Context-Aware Traversal for robust RAG, a framework that builds on the HippoRAG 2 architecture and transforms the static KG into a query-adaptive navigation structure. We introduce a multi-faceted framework to steer the random walk: (1) Symbolic Anchoring, which injects weak entity constraints to regularize the random walk; (2) Query-Aware Dynamic Edge Weighting, which dynamically modulates graph structure, to prune irrelevant paths while amplifying those aligned with the query's intent; and (3) Key-Fact Passage Weight Enhancement, a cost-efficient bias that structurally anchors the random walk to likely evidence. Experiments across four multi-hop benchmarks demonstrate that CatRAG consistently outperforms state of the art baselines. Our analysis reveals that while standard Recall metrics show modest gains, CatRAG achieves substantial improvements in reasoning completeness, the capacity to recover the entire evidence path without gaps. These results reveal that our approach effectively bridges the gap between retrieving partial context and enabling fully grounded reasoning. Resources are available at https://github.com/kwunhang/CatRAG.
PFAvatar: Pose-Fusion 3D Personalized Avatar Reconstruction from Real-World Outfit-of-the-Day Photos
Nov 18, 2025We propose PFAvatar (Pose-Fusion Avatar), a new method that reconstructs high-quality 3D avatars from Outfit of the Day(OOTD) photos, which exhibit diverse poses, occlusions, and complex backgrounds. Our method consists of two stages: (1) fine-tuning a pose-aware diffusion model from few-shot OOTD examples and (2) distilling a 3D avatar represented by a neural radiance field (NeRF). In the first stage, unlike previous methods that segment images into assets (e.g., garments, accessories) for 3D assembly, which is prone to inconsistency, we avoid decomposition and directly model the full-body appearance. By integrating a pre-trained ControlNet for pose estimation and a novel Condition Prior Preservation Loss (CPPL), our method enables end-to-end learning of fine details while mitigating language drift in few-shot training. Our method completes personalization in just 5 minutes, achieving a 48x speed-up compared to previous approaches. In the second stage, we introduce a NeRF-based avatar representation optimized by canonical SMPL-X space sampling and Multi-Resolution 3D-SDS. Compared to mesh-based representations that suffer from resolution-dependent discretization and erroneous occluded geometry, our continuous radiance field can preserve high-frequency textures (e.g., hair) and handle occlusions correctly through transmittance. Experiments demonstrate that PFAvatar outperforms state-of-the-art methods in terms of reconstruction fidelity, detail preservation, and robustness to occlusions/truncations, advancing practical 3D avatar generation from real-world OOTD albums. In addition, the reconstructed 3D avatar supports downstream applications such as virtual try-on, animation, and human video reenactment, further demonstrating the versatility and practical value of our approach.
E3-Rewrite: Learning to Rewrite SQL for Executability, Equivalence,and Efficiency
Aug 12, 2025SQL query rewriting aims to reformulate a query into a more efficient form while preserving equivalence. Most existing methods rely on predefined rewrite rules. However, such rule-based approaches face fundamental limitations: (1) fixed rule sets generalize poorly to novel query patterns and struggle with complex queries; (2) a wide range of effective rewriting strategies cannot be fully captured by declarative rules. To overcome these issues, we propose using large language models (LLMs) to generate rewrites. LLMs can capture complex strategies, such as evaluation reordering and CTE rewriting. Despite this potential, directly applying LLMs often results in suboptimal or non-equivalent rewrites due to a lack of execution awareness and semantic grounding. To address these challenges, We present E3-Rewrite, an LLM-based SQL rewriting framework that produces executable, equivalent, and efficient queries. It integrates two core components: a context construction module and a reinforcement learning framework. First, the context module leverages execution plans and retrieved demonstrations to build bottleneck-aware prompts that guide inference-time rewriting. Second, we design a reward function targeting executability, equivalence, and efficiency, evaluated via syntax checks, equivalence verification, and cost estimation. Third, to ensure stable multi-objective learning, we adopt a staged curriculum that first emphasizes executability and equivalence, then gradually incorporates efficiency. Extensive experiments show that E3-Rewrite achieves up to a 25.6\% reduction in query execution time compared to state-of-the-art methods across multiple SQL benchmarks. Moreover, it delivers up to 24.4\% more successful rewrites, expanding coverage to complex queries that previous systems failed to handle.
Data-Aware Socratic Query Refinement in Database Systems
Aug 07, 2025

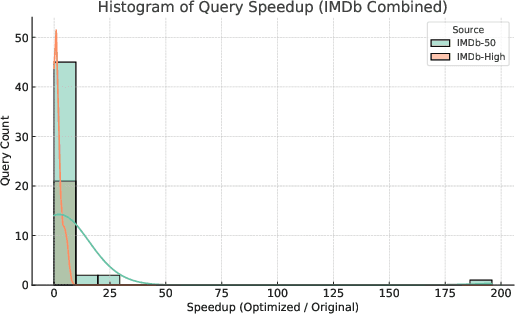

In this paper, we propose Data-Aware Socratic Guidance (DASG), a dialogue-based query enhancement framework that embeds \linebreak interactive clarification as a first-class operator within database systems to resolve ambiguity in natural language queries. DASG treats dialogue as an optimization decision, asking clarifying questions only when the expected execution cost reduction exceeds the interaction overhead. The system quantifies ambiguity through linguistic fuzziness, schema grounding confidence, and projected costs across relational and vector backends. Our algorithm selects the optimal clarifications by combining semantic relevance, catalog-based information gain, and potential cost reduction. We evaluate our proposed framework on three datasets. The results show that DASG demonstrates improved query precision while maintaining efficiency, establishing a cooperative analytics paradigm where systems actively participate in query formulation rather than passively translating user requests.
LegalReasoner: Step-wised Verification-Correction for Legal Judgment Reasoning
Jun 09, 2025Legal judgment prediction (LJP) aims to function as a judge by making final rulings based on case claims and facts, which plays a vital role in the judicial domain for supporting court decision-making and improving judicial efficiency. However, existing methods often struggle with logical errors when conducting complex legal reasoning. We propose LegalReasoner, which enhances LJP reliability through step-wise verification and correction of the reasoning process. Specifically, it first identifies dispute points to decompose complex cases, and then conducts step-wise reasoning while employing a process verifier to validate each step's logic from correctness, progressiveness, and potential perspectives. When errors are detected, expert-designed attribution and resolution strategies are applied for correction. To fine-tune LegalReasoner, we release the LegalHK dataset, containing 58,130 Hong Kong court cases with detailed annotations of dispute points, step-by-step reasoning chains, and process verification labels. Experiments demonstrate that LegalReasoner significantly improves concordance with court decisions from 72.37 to 80.27 on LLAMA-3.1-70B. The data is available at https://huggingface.co/datasets/weijiezz/LegalHK.
ExeSQL: Self-Taught Text-to-SQL Models with Execution-Driven Bootstrapping for SQL Dialects
May 22, 2025Recent text-to-SQL models have achieved strong performance, but their effectiveness remains largely confined to SQLite due to dataset limitations. However, real-world applications require SQL generation across multiple dialects with varying syntax and specialized features, which remains a challenge for current models. The main obstacle in building a dialect-aware model lies in acquiring high-quality dialect-specific data. Data generated purely through static prompting - without validating SQLs via execution - tends to be noisy and unreliable. Moreover, the lack of real execution environments in the training loop prevents models from grounding their predictions in executable semantics, limiting generalization despite surface-level improvements from data filtering. This work introduces ExeSQL, a text-to-SQL framework with execution-driven, agentic bootstrapping. The method consists of iterative query generation, execution-based filtering (e.g., rejection sampling), and preference-based training, enabling the model to adapt to new SQL dialects through verifiable, feedback-guided learning. Experiments show that ExeSQL bridges the dialect gap in text-to-SQL, achieving average improvements of 15.2%, 10.38%, and 4.49% over GPT-4o on PostgreSQL, MySQL, and Oracle, respectively, across multiple datasets of varying difficulty.
Leveraging Pretrained Diffusion Models for Zero-Shot Part Assembly
May 01, 20253D part assembly aims to understand part relationships and predict their 6-DoF poses to construct realistic 3D shapes, addressing the growing demand for autonomous assembly, which is crucial for robots. Existing methods mainly estimate the transformation of each part by training neural networks under supervision, which requires a substantial quantity of manually labeled data. However, the high cost of data collection and the immense variability of real-world shapes and parts make traditional methods impractical for large-scale applications. In this paper, we propose first a zero-shot part assembly method that utilizes pre-trained point cloud diffusion models as discriminators in the assembly process, guiding the manipulation of parts to form realistic shapes. Specifically, we theoretically demonstrate that utilizing a diffusion model for zero-shot part assembly can be transformed into an Iterative Closest Point (ICP) process. Then, we propose a novel pushing-away strategy to address the overlap parts, thereby further enhancing the robustness of the method. To verify our work, we conduct extensive experiments and quantitative comparisons to several strong baseline methods, demonstrating the effectiveness of the proposed approach, which even surpasses the supervised learning method. The code has been released on https://github.com/Ruiyuan-Zhang/Zero-Shot-Assembly.
* 10 pages, 12 figures, Accepted by IJCAI-2025
Versatile Framework for Song Generation with Prompt-based Control
Apr 29, 2025Song generation focuses on producing controllable high-quality songs based on various prompts. However, existing methods struggle to generate vocals and accompaniments with prompt-based control and proper alignment. Additionally, they fall short in supporting various tasks. To address these challenges, we introduce VersBand, a multi-task song generation framework for synthesizing high-quality, aligned songs with prompt-based control. VersBand comprises these primary models: 1) VocalBand, a decoupled model, leverages the flow-matching method for generating singing styles, pitches, and mel-spectrograms, allowing fast, high-quality vocal generation with style control. 2) AccompBand, a flow-based transformer model, incorporates the Band-MOE, selecting suitable experts for enhanced quality, alignment, and control. This model allows for generating controllable, high-quality accompaniments aligned with vocals. 3) Two generation models, LyricBand for lyrics and MelodyBand for melodies, contribute to the comprehensive multi-task song generation system, allowing for extensive control based on multiple prompts. Experimental results demonstrate that VersBand performs better over baseline models across multiple song generation tasks using objective and subjective metrics. Audio samples are available at https://aaronz345.github.io/VersBandDemo.