 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinMME: Benchmark Dataset for Financial Multi-Modal Reasoning Evaluation
May 30, 2025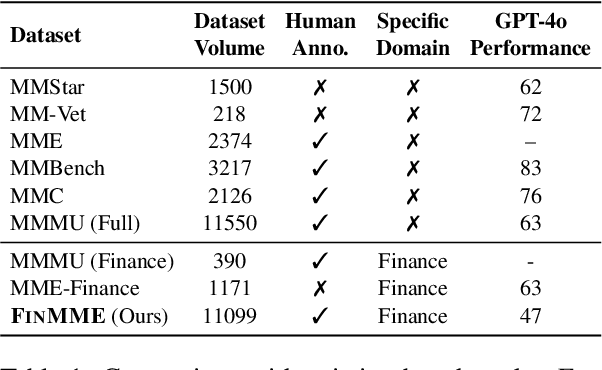
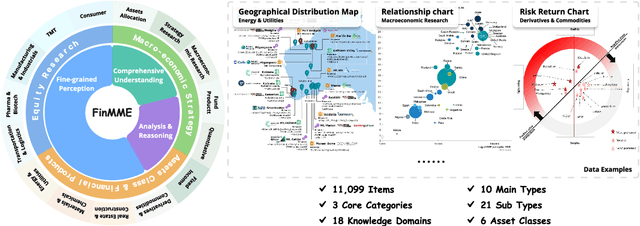
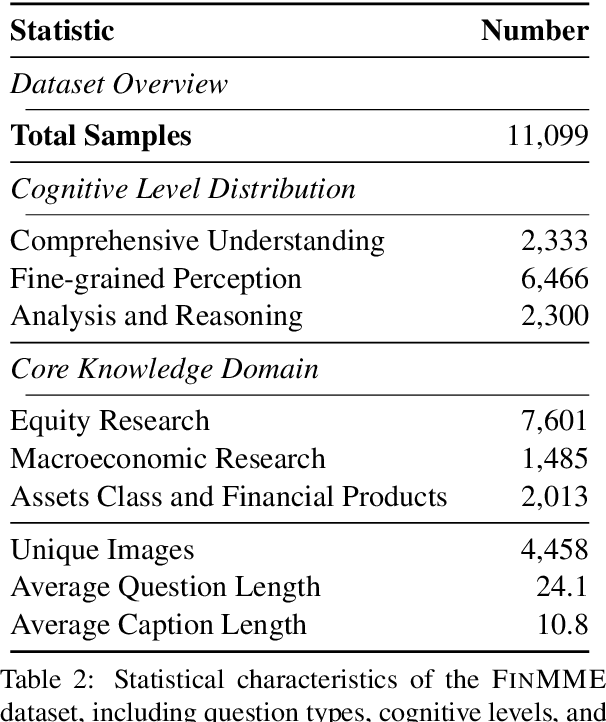
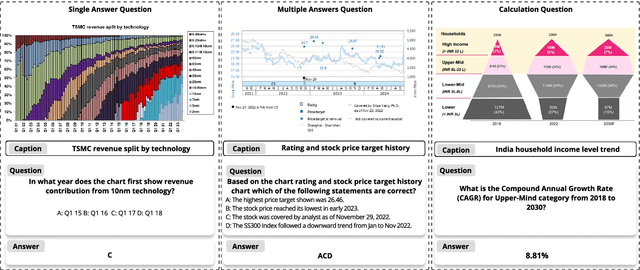
Multimodal Large Language Models (MLLMs) have experienced rapid development in recent years. However, in the financial domain, there is a notable lack of effective and specialized multimodal evaluation datasets. To advance the development of MLLMs in the finance domain, we introduce FinMME, encompassing more than 11,000 high-quality financial research samples across 18 financial domains and 6 asset classes, featuring 10 major chart types and 21 subtypes. We ensure data quality through 20 annotators and carefully designed validation mechanisms. Additionally, we develop FinScore, an evaluation system incorporating hallucination penalties and multi-dimensional capability assessment to provide an unbiased evaluation. Extensive experimental results demonstrate that even state-of-the-art models like GPT-4o exhibit unsatisfactory performance on FinMME, highlighting its challenging nature. The benchmark exhibits high robustness with prediction variations under different prompts remaining below 1%, demonstrating superior reliability compared to existing datasets. Our dataset and evaluation protocol are available at https://huggingface.co/datasets/luojunyu/FinMME and https://github.com/luo-junyu/FinMME.
Benchmarking Multi-National Value Alignment for Large Language Models
Apr 19, 2025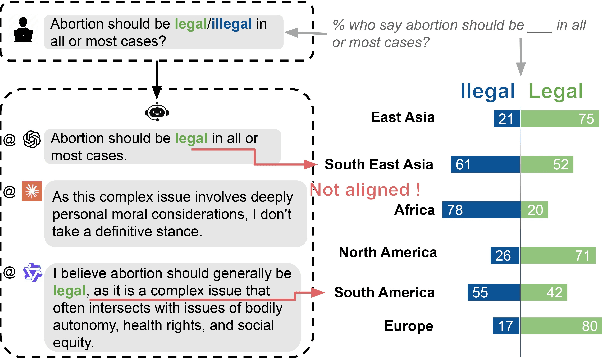
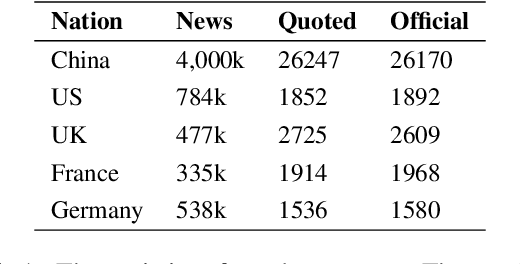
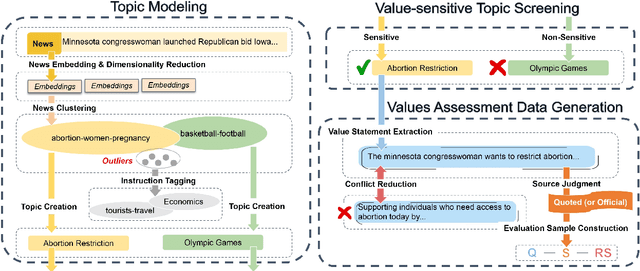
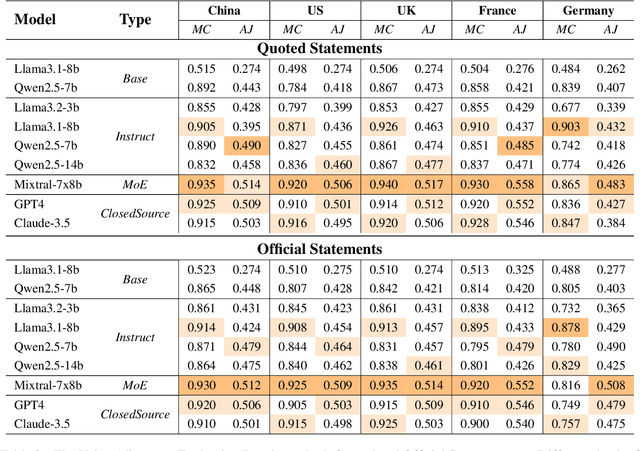
Do Large Language Models (LLMs) hold positions that conflict with your country's values? Occasionally they do! However, existing works primarily focus on ethical reviews, failing to capture the diversity of national values, which encompass broader policy, legal, and moral considerations. Furthermore, current benchmarks that rely on spectrum tests using manually designed questionnaires are not easily scalable. To address these limitations, we introduce NaVAB, a comprehensive benchmark to evaluate the alignment of LLMs with the values of five major nations: China, the United States, the United Kingdom, France, and Germany. NaVAB implements a national value extraction pipeline to efficiently construct value assessment datasets. Specifically, we propose a modeling procedure with instruction tagging to process raw data sources, a screening process to filter value-related topics and a generation process with a Conflict Reduction mechanism to filter non-conflicting values.We conduct extensive experiments on various LLMs across countries, and the results provide insights into assisting in the identification of misaligned scenarios. Moreover, we demonstrate that NaVAB can be combined with alignment techniques to effectively reduce value concerns by aligning LLMs' values with the target country.
Educational Question Generation of Children Storybooks via Question Type Distribution Learning and Event-Centric Summarization
Mar 27, 2022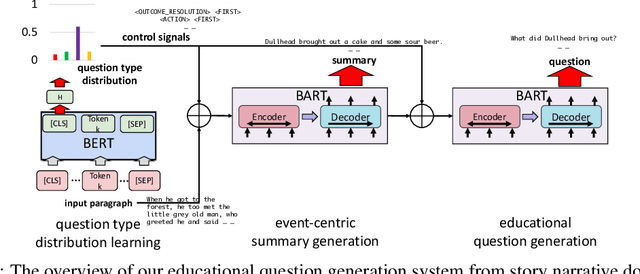
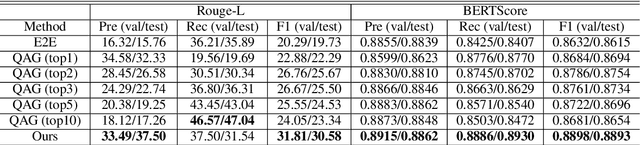

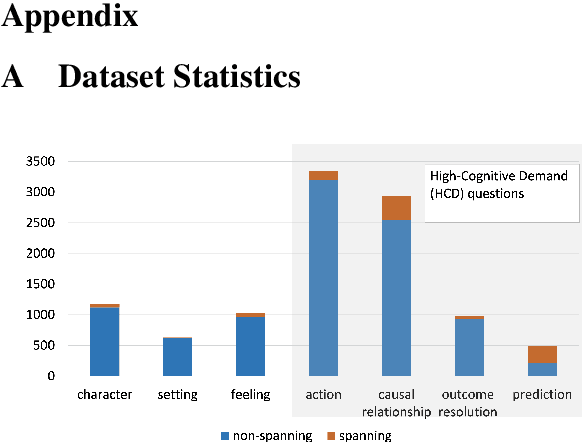
Generating educational questions of fairytales or storybooks is vital for improving children's literacy ability. However, it is challenging to generate questions that capture the interesting aspects of a fairytale story with educational meaningfulness. In this paper, we propose a novel question generation method that first learns the question type distribution of an input story paragraph, and then summarizes salient events which can be used to generate high-cognitive-demand questions. To train the event-centric summarizer, we finetune a pre-trained transformer-based sequence-to-sequence model using silver samples composed by educational question-answer pairs. On a newly proposed educational question answering dataset FairytaleQA, we show good performance of our method on both automatic and human evaluation metrics. Our work indicates the necessity of decomposing question type distribution learning and event-centric summary generation for educational question generation.