 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoopGuard: Breaking Self-Reinforcing Attention Loops via Dynamic KV Cache Intervention
Apr 11, 2026Through systematic experiments on long-context generation, we observe a damaging failure mode in which decoding can collapse into persistent repetition loops. We find that this degeneration is driven by collapsed attention patterns, where a subset of heads locks onto a narrow suffix of the history, and is further stabilized by inference-time KV cache reuse. Crucially, since many existing KV cache policies rely on attention-based importance, this collapse can produce spuriously high scores for repetitive tokens, causing cache management to inadvertently amplify repetition. To study this phenomenon in a controlled and reproducible manner, we introduce LoopBench, a benchmark with explicit loop-inducing conditions and loop-oriented metrics that quantify repetition severity and generation instability beyond downstream task scores. Building on these insights, we propose LoopGuard, a lightweight, plug-in KV cache guard that detects loop onset online and disrupts the feedback cycle by pruning repetitive tail spans under a fixed cache budget. Experiments on LoopBench show that LoopGuard reduces loop incidence by over 90 percentage points, while restoring output diversity and reducing token waste.
Head-wise Modality Specialization within MLLMs for Robust Fake News Detection under Missing Modality
Apr 08, 2026Multimodal fake news detection (MFND) aims to verify news credibility by jointly exploiting textual and visual evidence. However, real-world news dissemination frequently suffers from missing modality due to deleted images, corrupted screenshots, and similar issues. Thus, robust detection in this scenario requires preserving strong verification ability for each modality, which is challenging in MFND due to insufficient learning of the low-contribution modality and scarce unimodal annotations. To address this issue, we propose Head-wise Modality Specialization within Multimodal Large Language Models (MLLMs) for robust MFND under missing modality. Specifically, we first systematically study attention heads in MLLMs and their relationship with performance under missing modality, showing that modality-critical heads serve as key carriers of unimodal verification ability through their modality specialization. Based on this observation, to better preserve verification ability for the low-contribution modality, we introduce a head-wise specialization mechanism that explicitly allocates these heads to different modalities and preserves their specialization through lower-bound attention constraints. Furthermore, to better exploit scarce unimodal annotations, we propose a Unimodal Knowledge Retention strategy that prevents these heads from drifting away from the unimodal knowledge learned from limited supervision. Experiments show that our method improves robustness under missing modality while preserving performance with full multimodal input.
PeroMAS: A Multi-agent System of Perovskite Material Discovery
Feb 10, 2026As a pioneer of the third-generation photovoltaic revolution, Perovskite Solar Cells (PSCs) are renowned for their superior optoelectronic performance and cost potential. The development process of PSCs is precise and complex, involving a series of closed-loop workflows such as literature retrieval, data integration, experimental design, and synthesis. However, existing AI perovskite approaches focus predominantly on discrete models, including material design, process optimization,and property prediction. These models fail to propagate physical constraints across the workflow, hindering end-to-end optimization. In this paper, we propose a multi-agent system for perovskite material discovery, named PeroMAS. We first encapsulated a series of perovskite-specific tools into Model Context Protocols (MCPs). By planning and invoking these tools, PeroMAS can design perovskite materials under multi-objective constraints, covering the entire process from literature retrieval and data extraction to property prediction and mechanism analysis. Furthermore, we construct an evaluation benchmark by perovskite human experts to assess this multi-agent system. Results demonstrate that, compared to single Large Language Model (LLM) or traditional search strategies, our system significantly enhances discovery efficiency. It successfully identified candidate materials satisfying multi-objective constraints. Notably, we verify PeroMAS's effectiveness in the physical world through real synthesis experiments.
DynaGen: Unifying Temporal Knowledge Graph Reasoning with Dynamic Subgraphs and Generative Regularization
Dec 14, 2025Temporal Knowledge Graph Reasoning (TKGR) aims to complete missing factual elements along the timeline. Depending on the temporal position of the query, the task is categorized into interpolation and extrapolation. Existing interpolation methods typically embed temporal information into individual facts to complete missing historical knowledge, while extrapolation techniques often leverage sequence models over graph snapshots to identify recurring patterns for future event prediction. These methods face two critical challenges: limited contextual modeling in interpolation and cognitive generalization bias in extrapolation. To address these, we propose a unified method for TKGR, dubbed DynaGen. For interpolation, DynaGen dynamically constructs entity-centric subgraphs and processes them with a synergistic dual-branch GNN encoder to capture evolving structural context. For extrapolation, it applies a conditional diffusion process, which forces the model to learn underlying evolutionary principles rather than just superficial patterns, enhancing its ability to predict unseen future events. Extensive experiments on six benchmark datasets show DynaGen achieves state-of-the-art performance. On average, compared to the second-best models, DynaGen improves the Mean Reciprocal Rank (MRR) score by 2.61 points for interpolation and 1.45 points for extrapolation.
Automatic Failure Attribution and Critical Step Prediction Method for Multi-Agent Systems Based on Causal Inference
Sep 10, 2025Multi-agent systems (MAS) are critical for automating complex tasks, yet their practical deployment is severely hampered by the challenge of failure attribution. Current diagnostic tools, which rely on statistical correlations, are fundamentally inadequate; on challenging benchmarks like Who\&When, state-of-the-art methods achieve less than 15\% accuracy in locating the root-cause step of a failure. To address this critical gap, we introduce the first failure attribution framework for MAS grounded in multi-granularity causal inference. Our approach makes two key technical contributions: (1) a performance causal inversion principle, which correctly models performance dependencies by reversing the data flow in execution logs, combined with Shapley values to accurately assign agent-level blame; (2) a novel causal discovery algorithm, CDC-MAS, that robustly identifies critical failure steps by tackling the non-stationary nature of MAS interaction data. The framework's attribution results directly fuel an automated optimization loop, generating targeted suggestions whose efficacy is validated via counterfactual simulations. Evaluations on the Who\&When and TRAIL benchmarks demonstrate a significant leap in performance. Our method achieves up to 36.2\% step-level accuracy. Crucially, the generated optimizations boost overall task success rates by an average of 22.4\%. This work provides a principled and effective solution for debugging complex agent interactions, paving the way for more reliable and interpretable multi-agent systems.
E3-Rewrite: Learning to Rewrite SQL for Executability, Equivalence,and Efficiency
Aug 12, 2025SQL query rewriting aims to reformulate a query into a more efficient form while preserving equivalence. Most existing methods rely on predefined rewrite rules. However, such rule-based approaches face fundamental limitations: (1) fixed rule sets generalize poorly to novel query patterns and struggle with complex queries; (2) a wide range of effective rewriting strategies cannot be fully captured by declarative rules. To overcome these issues, we propose using large language models (LLMs) to generate rewrites. LLMs can capture complex strategies, such as evaluation reordering and CTE rewriting. Despite this potential, directly applying LLMs often results in suboptimal or non-equivalent rewrites due to a lack of execution awareness and semantic grounding. To address these challenges, We present E3-Rewrite, an LLM-based SQL rewriting framework that produces executable, equivalent, and efficient queries. It integrates two core components: a context construction module and a reinforcement learning framework. First, the context module leverages execution plans and retrieved demonstrations to build bottleneck-aware prompts that guide inference-time rewriting. Second, we design a reward function targeting executability, equivalence, and efficiency, evaluated via syntax checks, equivalence verification, and cost estimation. Third, to ensure stable multi-objective learning, we adopt a staged curriculum that first emphasizes executability and equivalence, then gradually incorporates efficiency. Extensive experiments show that E3-Rewrite achieves up to a 25.6\% reduction in query execution time compared to state-of-the-art methods across multiple SQL benchmarks. Moreover, it delivers up to 24.4\% more successful rewrites, expanding coverage to complex queries that previous systems failed to handle.
LegalReasoner: Step-wised Verification-Correction for Legal Judgment Reasoning
Jun 09, 2025Legal judgment prediction (LJP) aims to function as a judge by making final rulings based on case claims and facts, which plays a vital role in the judicial domain for supporting court decision-making and improving judicial efficiency. However, existing methods often struggle with logical errors when conducting complex legal reasoning. We propose LegalReasoner, which enhances LJP reliability through step-wise verification and correction of the reasoning process. Specifically, it first identifies dispute points to decompose complex cases, and then conducts step-wise reasoning while employing a process verifier to validate each step's logic from correctness, progressiveness, and potential perspectives. When errors are detected, expert-designed attribution and resolution strategies are applied for correction. To fine-tune LegalReasoner, we release the LegalHK dataset, containing 58,130 Hong Kong court cases with detailed annotations of dispute points, step-by-step reasoning chains, and process verification labels. Experiments demonstrate that LegalReasoner significantly improves concordance with court decisions from 72.37 to 80.27 on LLAMA-3.1-70B. The data is available at https://huggingface.co/datasets/weijiezz/LegalHK.
Benchmarking Multi-National Value Alignment for Large Language Models
Apr 19, 2025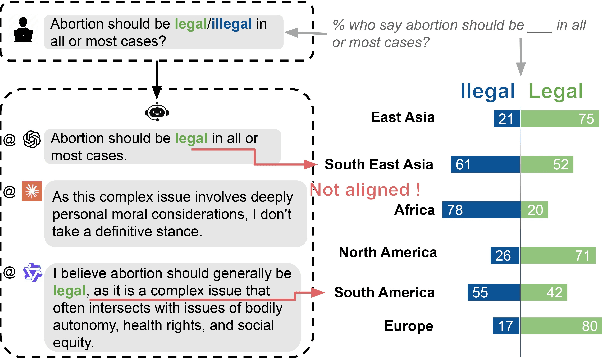
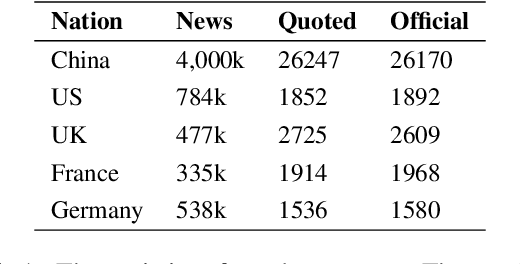
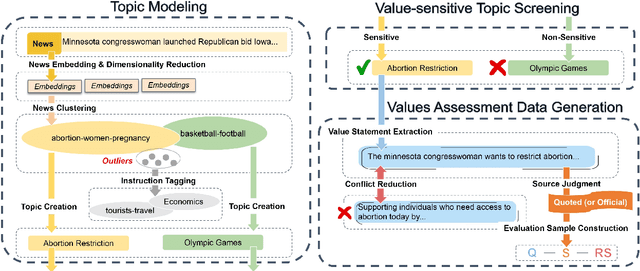
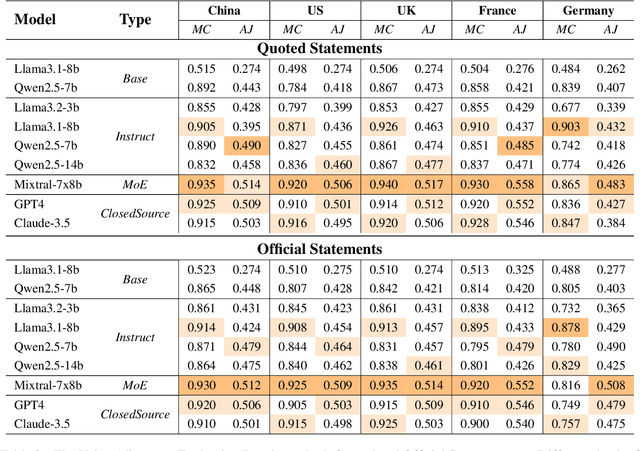
Do Large Language Models (LLMs) hold positions that conflict with your country's values? Occasionally they do! However, existing works primarily focus on ethical reviews, failing to capture the diversity of national values, which encompass broader policy, legal, and moral considerations. Furthermore, current benchmarks that rely on spectrum tests using manually designed questionnaires are not easily scalable. To address these limitations, we introduce NaVAB, a comprehensive benchmark to evaluate the alignment of LLMs with the values of five major nations: China, the United States, the United Kingdom, France, and Germany. NaVAB implements a national value extraction pipeline to efficiently construct value assessment datasets. Specifically, we propose a modeling procedure with instruction tagging to process raw data sources, a screening process to filter value-related topics and a generation process with a Conflict Reduction mechanism to filter non-conflicting values.We conduct extensive experiments on various LLMs across countries, and the results provide insights into assisting in the identification of misaligned scenarios. Moreover, we demonstrate that NaVAB can be combined with alignment techniques to effectively reduce value concerns by aligning LLMs' values with the target country.
Adaptation Method for Misinformation Identification
Apr 19, 2025



Multimodal fake news detection plays a crucial role in combating online misinformation. Unfortunately, effective detection methods rely on annotated labels and encounter significant performance degradation when domain shifts exist between training (source) and test (target) data. To address the problems, we propose ADOSE, an Active Domain Adaptation (ADA) framework for multimodal fake news detection which actively annotates a small subset of target samples to improve detection performance. To identify various deceptive patterns in cross-domain settings, we design multiple expert classifiers to learn dependencies across different modalities. These classifiers specifically target the distinct deception patterns exhibited in fake news, where two unimodal classifiers capture knowledge errors within individual modalities while one cross-modal classifier identifies semantic inconsistencies between text and images. To reduce annotation costs from the target domain, we propose a least-disagree uncertainty selector with a diversity calculator for selecting the most informative samples. The selector leverages prediction disagreement before and after perturbations by multiple classifiers as an indicator of uncertain samples, whose deceptive patterns deviate most from source domains. It further incorporates diversity scores derived from multi-view features to ensure the chosen samples achieve maximal coverage of target domain features. The extensive experiments on multiple datasets show that ADOSE outperforms existing ADA methods by 2.72\% $\sim$ 14.02\%, indicating the superiority of our model.
DIDS: Domain Impact-aware Data Sampling for Large Language Model Training
Apr 17, 2025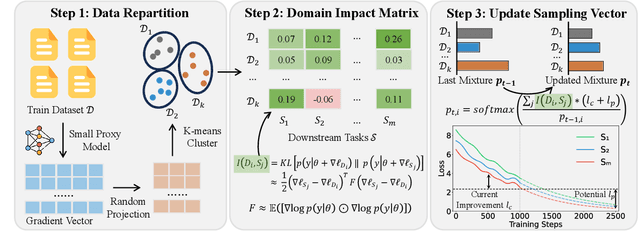


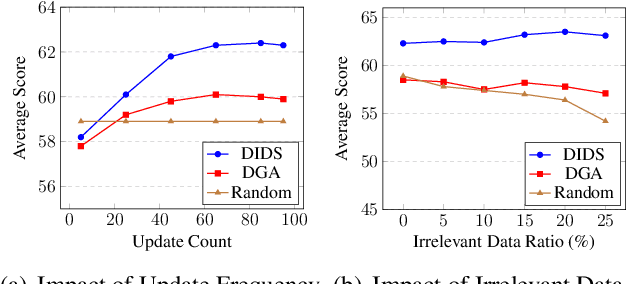
Large language models (LLMs) are commonly trained on multi-domain datasets, where domain sampling strategies significantly impact model performance due to varying domain importance across downstream tasks. Existing approaches for optimizing domain-level sampling strategies struggle with maintaining intra-domain consistency and accurately measuring domain impact. In this paper, we present Domain Impact-aware Data Sampling (DIDS). To ensure intra-domain consistency, a gradient clustering algorithm is proposed to group training data based on their learning effects, where a proxy language model and dimensionality reduction are employed to reduce computational overhead. To accurately measure domain impact, we develop a Fisher Information Matrix (FIM) guided metric that quantifies how domain-specific parameter updates affect the model's output distributions on downstream tasks, with theoretical guarantees. Furthermore, to determine optimal sampling ratios, DIDS combines both the FIM-guided domain impact assessment and loss learning trajectories that indicate domain-specific potential, while accounting for diminishing marginal returns. Extensive experiments demonstrate that DIDS achieves 3.4% higher average performance while maintaining comparable training efficiency.