 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Iteration-Free Fixed-Point Estimator for Diffusion Inversion
Dec 09, 2025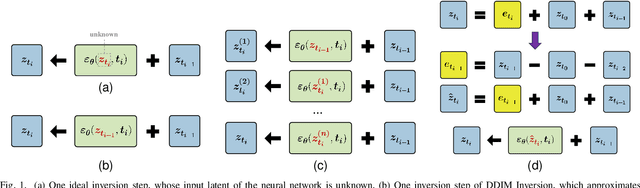



Diffusion inversion aims to recover the initial noise corresponding to a given image such that this noise can reconstruct the original image through the denoising diffusion process. The key component of diffusion inversion is to minimize errors at each inversion step, thereby mitigating cumulative inaccuracies. Recently, fixed-point iteration has emerged as a widely adopted approach to minimize reconstruction errors at each inversion step. However, it suffers from high computational costs due to its iterative nature and the complexity of hyperparameter selection. To address these issues, we propose an iteration-free fixed-point estimator for diffusion inversion. First, we derive an explicit expression of the fixed point from an ideal inversion step. Unfortunately, it inherently contains an unknown data prediction error. Building upon this, we introduce the error approximation, which uses the calculable error from the previous inversion step to approximate the unknown error at the current inversion step. This yields a calculable, approximate expression for the fixed point, which is an unbiased estimator characterized by low variance, as shown by our theoretical analysis. We evaluate reconstruction performance on two text-image datasets, NOCAPS and MS-COCO. Compared to DDIM inversion and other inversion methods based on the fixed-point iteration, our method achieves consistent and superior performance in reconstruction tasks without additional iterations or training.
HV-Attack: Hierarchical Visual Attack for Multimodal Retrieval Augmented Generation
Nov 19, 2025Advanced multimodal Retrieval-Augmented Generation (MRAG) techniques have been widely applied to enhance the capabilities of Large Multimodal Models (LMMs), but they also bring along novel safety issues. Existing adversarial research has revealed the vulnerability of MRAG systems to knowledge poisoning attacks, which fool the retriever into recalling injected poisoned contents. However, our work considers a different setting: visual attack of MRAG by solely adding imperceptible perturbations at the image inputs of users, without manipulating any other components. This is challenging due to the robustness of fine-tuned retrievers and large-scale generators, and the effect of visual perturbation may be further weakened by propagation through the RAG chain. We propose a novel Hierarchical Visual Attack that misaligns and disrupts the two inputs (the multimodal query and the augmented knowledge) of MRAG's generator to confuse its generation. We further design a hierarchical two-stage strategy to obtain misaligned augmented knowledge. We disrupt the image input of the retriever to make it recall irrelevant knowledge from the original database, by optimizing the perturbation which first breaks the cross-modal alignment and then disrupts the multimodal semantic alignment. We conduct extensive experiments on two widely-used MRAG datasets: OK-VQA and InfoSeek. We use CLIP-based retrievers and two LMMs BLIP-2 and LLaVA as generators. Results demonstrate the effectiveness of our visual attack on MRAG through the significant decrease in both retrieval and generation performance.
Rethinking Oversaturation in Classifier-Free Guidance via Low Frequency
Jun 26, 2025



Classifier-free guidance (CFG) succeeds in condition diffusion models that use a guidance scale to balance the influence of conditional and unconditional terms. A high guidance scale is used to enhance the performance of the conditional term. However, the high guidance scale often results in oversaturation and unrealistic artifacts. In this paper, we introduce a new perspective based on low-frequency signals, identifying the accumulation of redundant information in these signals as the key factor behind oversaturation and unrealistic artifacts. Building on this insight, we propose low-frequency improved classifier-free guidance (LF-CFG) to mitigate these issues. Specifically, we introduce an adaptive threshold-based measurement to pinpoint the locations of redundant information. We determine a reasonable threshold by analyzing the change rate of low-frequency information between prior and current steps. We then apply a down-weight strategy to reduce the impact of redundant information in the low-frequency signals. Experimental results demonstrate that LF-CFG effectively alleviates oversaturation and unrealistic artifacts across various diffusion models, including Stable Diffusion-XL, Stable Diffusion 2.1, 3.0, 3.5, and SiT-XL.
Detecting Emotional Incongruity of Sarcasm by Commonsense Reasoning
Dec 17, 2024This paper focuses on sarcasm detection, which aims to identify whether given statements convey criticism, mockery, or other negative sentiment opposite to the literal meaning. To detect sarcasm, humans often require a comprehensive understanding of the semantics in the statement and even resort to external commonsense to infer the fine-grained incongruity. However, existing methods lack commonsense inferential ability when they face complex real-world scenarios, leading to unsatisfactory performance. To address this problem, we propose a novel framework for sarcasm detection, which conducts incongruity reasoning based on commonsense augmentation, called EICR. Concretely, we first employ retrieval-augmented large language models to supplement the missing but indispensable commonsense background knowledge. To capture complex contextual associations, we construct a dependency graph and obtain the optimized topology via graph refinement. We further introduce an adaptive reasoning skeleton that integrates prior rules to extract sentiment-inconsistent subgraphs explicitly. To eliminate the possible spurious relations between words and labels, we employ adversarial contrastive learning to enhance the robustness of the detector. Experiments conducted on five datasets demonstrate the effectiveness of EICR.
Test-time Alignment-Enhanced Adapter for Vision-Language Models
Nov 24, 2024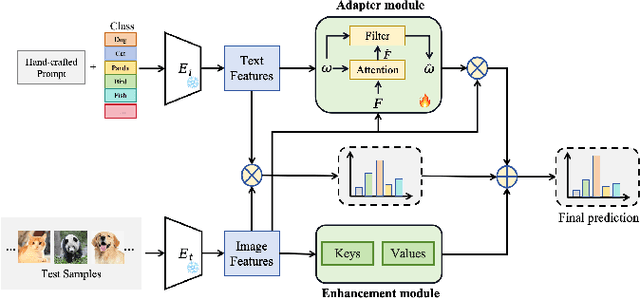



Test-time adaptation with pre-trained vision-language models (VLMs) has attracted increasing attention for tackling the issue of distribution shift during the test phase. While prior methods have shown effectiveness in addressing distribution shift by adjusting classification logits, they are not optimal due to keeping text features unchanged. To address this issue, we introduce a new approach called Test-time Alignment-Enhanced Adapter (TAEA), which trains an adapter with test samples to adjust text features during the test phase. We can enhance the text-to-image alignment prediction by utilizing an adapter to adapt text features. Furthermore, we also propose to adopt the negative cache from TDA as enhancement module, which further improves the performance of TAEA. Our approach outperforms the state-of-the-art TTA method of pre-trained VLMs by an average of 0.75% on the out-of-distribution benchmark and 2.5% on the cross-domain benchmark, with an acceptable training time. Code will be available at https://github.com/BaoshunWq/clip-TAEA.
Enhancing Few-Shot Out-of-Distribution Detection with Gradient Aligned Context Optimization
Nov 24, 2024



Few-shot out-of-distribution (OOD) detection aims to detect OOD images from unseen classes with only a few labeled in-distribution (ID) images. To detect OOD images and classify ID samples, prior methods have been proposed by regarding the background regions of ID samples as the OOD knowledge and performing OOD regularization and ID classification optimization. However, the gradient conflict still exists between ID classification optimization and OOD regularization caused by biased recognition. To address this issue, we present Gradient Aligned Context Optimization (GaCoOp) to mitigate this gradient conflict. Specifically, we decompose the optimization gradient to identify the scenario when the conflict occurs. Then we alleviate the conflict in inner ID samples and optimize the prompts via leveraging gradient projection. Extensive experiments over the large-scale ImageNet OOD detection benchmark demonstrate that our GaCoOp can effectively mitigate the conflict and achieve great performance. Code will be available at https://github.com/BaoshunWq/ood-GaCoOp.
Leveraging Previous Steps: A Training-free Fast Solver for Flow Diffusion
Nov 12, 2024



Flow diffusion models (FDMs) have recently shown potential in generation tasks due to the high generation quality. However, the current ordinary differential equation (ODE) solver for FDMs, e.g., the Euler solver, still suffers from slow generation since ODE solvers need many number function evaluations (NFE) to keep high-quality generation. In this paper, we propose a novel training-free flow-solver to reduce NFE while maintaining high-quality generation. The key insight for the flow-solver is to leverage the previous steps to reduce the NFE, where a cache is created to reuse these results from the previous steps. Specifically, the Taylor expansion is first used to approximate the ODE. To calculate the high-order derivatives of Taylor expansion, the flow-solver proposes to use the previous steps and a polynomial interpolation to approximate it, where the number of orders we could approximate equals the number of previous steps we cached. We also prove that the flow-solver has a more minor approximation error and faster generation speed. Experimental results on the CIFAR-10, CelebA-HQ, LSUN-Bedroom, LSUN-Church, ImageNet, and real text-to-image generation prove the efficiency of the flow-solver. Specifically, the flow-solver improves the FID-30K from 13.79 to 6.75, from 46.64 to 19.49 with $\text{NFE}=10$ on CIFAR-10 and LSUN-Church, respectively.
Unraveling the Connections between Flow Matching and Diffusion Probabilistic Models in Training-free Conditional Generation
Nov 12, 2024



Training-free conditional generation aims to leverage the unconditional diffusion models to implement the conditional generation, where flow-matching (FM) and diffusion probabilistic models (DPMs) are two mature unconditional diffusion models that achieve high-quality generation. Two questions were asked in this paper: What are the underlying connections between FM and DPMs in training-free conditional generation? Can we leverage DPMs to improve the training-free conditional generation for FM? We first show that a probabilistic diffusion path can be associated with the FM and DPMs. Then, we reformulate the ordinary differential equation (ODE) of FM based on the score function of DPMs, and thus, the conditions in FM can be incorporated as those in DPMs. Finally, we propose two posterior sampling methods to estimate the conditional term and achieve a training-free conditional generation of FM. Experimental results show that our proposed method could be implemented for various conditional generation tasks. Our method can generate higher-quality results than the state-of-the-art methods.
Fisher Information Improved Training-Free Conditional Diffusion Model
Apr 28, 2024
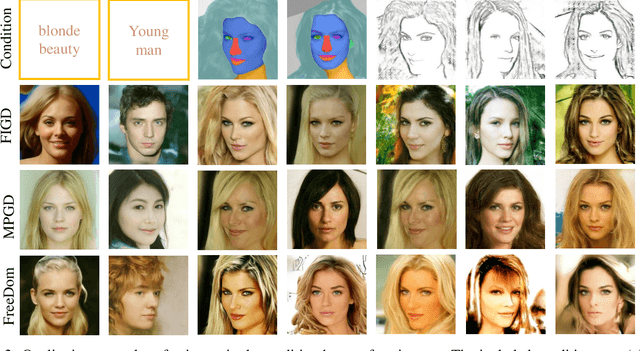

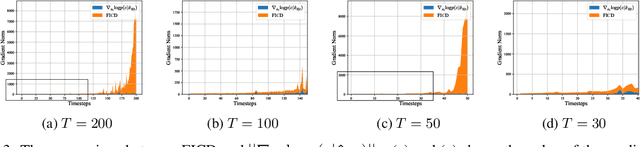
Recently, the diffusion model with the training-free methods has succeeded in conditional image generation tasks. However, there is an efficiency problem because it requires calculating the gradient with high computational cost, and previous methods make strong assumptions to solve it, sacrificing generalization. In this work, we propose the Fisher information guided diffusion model (FIGD). Concretely, we introduce the Fisher information to estimate the gradient without making any additional assumptions to reduce computation cost. Meanwhile, we demonstrate that the Fisher information ensures the generalization of FIGD and provides new insights for training-free methods based on the information theory. The experimental results demonstrate that FIGD could achieve different conditional generations more quickly while maintaining high quality.
MimicDiffusion: Purifying Adversarial Perturbation via Mimicking Clean Diffusion Model
Dec 08, 2023



Deep neural networks (DNNs) are vulnerable to adversarial perturbation, where an imperceptible perturbation is added to the image that can fool the DNNs. Diffusion-based adversarial purification focuses on using the diffusion model to generate a clean image against such adversarial attacks. Unfortunately, the generative process of the diffusion model is also inevitably affected by adversarial perturbation since the diffusion model is also a deep network where its input has adversarial perturbation. In this work, we propose MimicDiffusion, a new diffusion-based adversarial purification technique, that directly approximates the generative process of the diffusion model with the clean image as input. Concretely, we analyze the differences between the guided terms using the clean image and the adversarial sample. After that, we first implement MimicDiffusion based on Manhattan distance. Then, we propose two guidance to purify the adversarial perturbation and approximate the clean diffusion model. Extensive experiments on three image datasets including CIFAR-10, CIFAR-100, and ImageNet with three classifier backbones including WideResNet-70-16, WideResNet-28-10, and ResNet50 demonstrate that MimicDiffusion significantly performs better than the state-of-the-art baselines. On CIFAR-10, CIFAR-100, and ImageNet, it achieves 92.67\%, 61.35\%, and 61.53\% average robust accuracy, which are 18.49\%, 13.23\%, and 17.64\% higher, respectively. The code is available in the supplementary material.