 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Entropy-Based Test-Time Adaptation from a Clustering View
Nov 18, 2023



Domain shift is a common problem in the realistic world, where training data and test data follow different data distributions. To deal with this problem, fully test-time adaptation (TTA) leverages the unlabeled data encountered during test time to adapt the model. In particular, Entropy-Based TTA (EBTTA) methods, which minimize the prediction's entropy on test samples, have shown great success. In this paper, we introduce a new perspective on the EBTTA, which interprets these methods from a view of clustering. It is an iterative algorithm: 1) in the assignment step, the forward process of the EBTTA models is the assignment of labels for these test samples, and 2) in the updating step, the backward process is the update of the model via the assigned samples. Based on the interpretation, we can gain a deeper understanding of EBTTA, where we show that the entropy loss would further increase the largest probability. Accordingly, we offer an alternative explanation for why existing EBTTA methods are sensitive to initial assignments, outliers, and batch size. This observation can guide us to put forward the improvement of EBTTA. We propose robust label assignment, weight adjustment, and gradient accumulation to alleviate the above problems. Experimental results demonstrate that our method can achieve consistent improvements on various datasets. Code is provided in the supplementary material.
Revisiting Few-Shot Learning from a Causal Perspective
Sep 28, 2022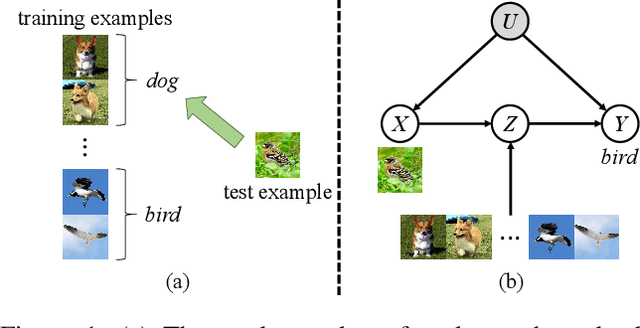
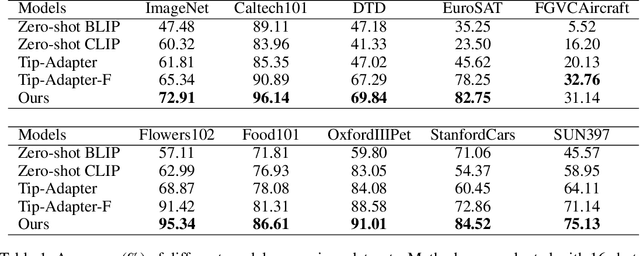
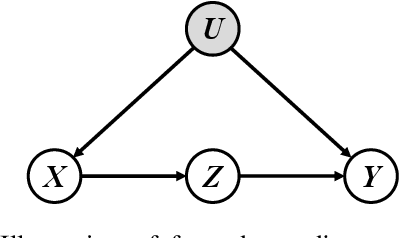
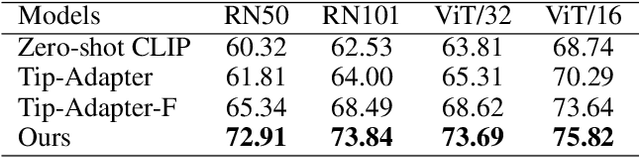
Few-shot learning with N-way K-shot scheme is an open challenge in machine learning. Many approaches have been proposed to tackle this problem, e.g., the Matching Networks and CLIP-Adapter. Despite that these approaches have shown significant progress, the mechanism of why these methods succeed has not been well explored. In this paper, we interpret these few-shot learning methods via causal mechanism. We show that the existing approaches can be viewed as specific forms of front-door adjustment, which is to remove the effects of confounders. Based on this, we introduce a general causal method for few-shot learning, which considers not only the relationship between examples but also the diversity of representations. Experimental results demonstrate the superiority of our proposed method in few-shot classification on various benchmark datasets. Code is available in the supplementary material.
Towards Better Plasticity-Stability Trade-off in Incremental Learning: A simple Linear Connector
Oct 15, 2021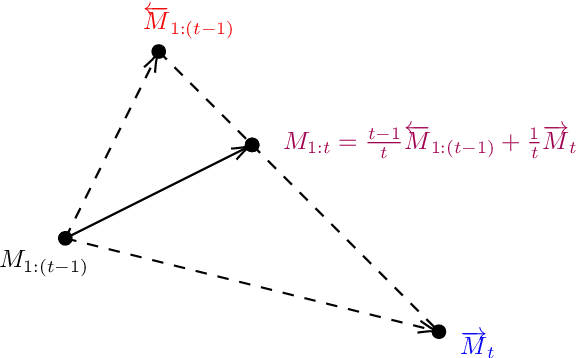
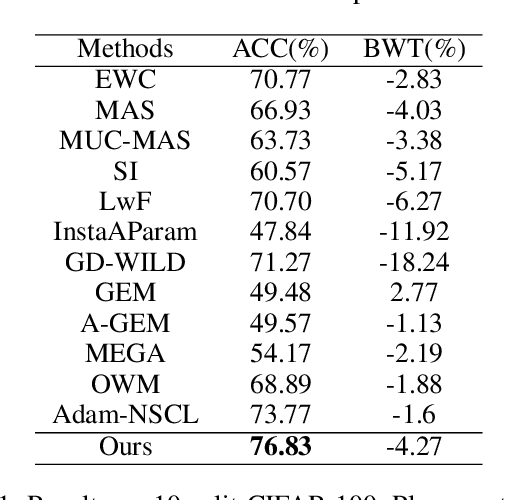
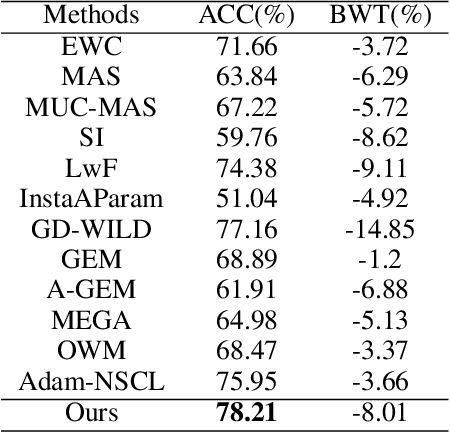
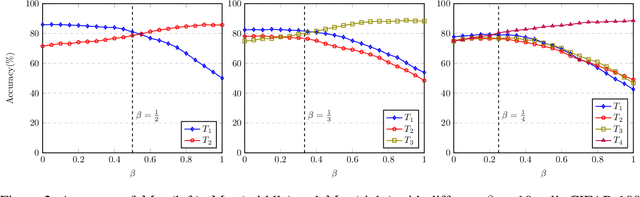
Plasticity-stability dilemma is a main problem for incremental learning, with plasticity referring to the ability to learn new knowledge, and stability retaining the knowledge of previous tasks. Due to the lack of training samples from previous tasks, it is hard to balance the plasticity and stability. For example, the recent null-space projection methods (e.g., Adam-NSCL) have shown promising performance on preserving previous knowledge, while such strong projection also causes the performance degradation of the current task. To achieve better plasticity-stability trade-off, in this paper, we show that a simple averaging of two independently optimized optima of networks, null-space projection for past tasks and simple SGD for the current task, can attain a meaningful balance between preserving already learned knowledge and granting sufficient flexibility for learning a new task. This simple linear connector also provides us a new perspective and technology to control the trade-off between plasticity and stability. We evaluate the proposed method on several benchmark datasets. The results indicate our simple method can achieve notable improvement, and perform well on both the past and current tasks. In short, our method is an extremely simple approach and achieves a better balance model.