 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInconsistent Few-Shot Relation Classification via Cross-Attentional Prototype Networks with Contrastive Learning
Oct 13, 2021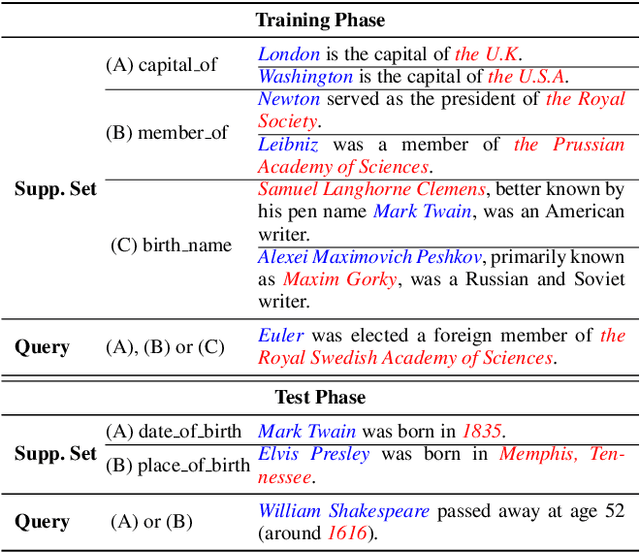
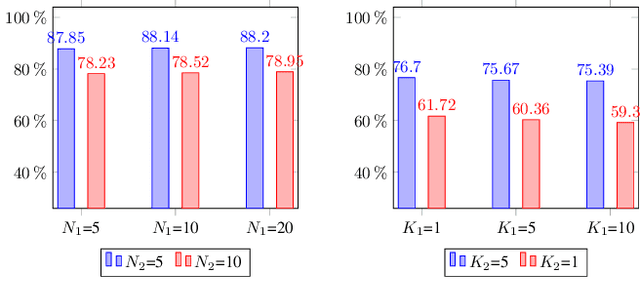
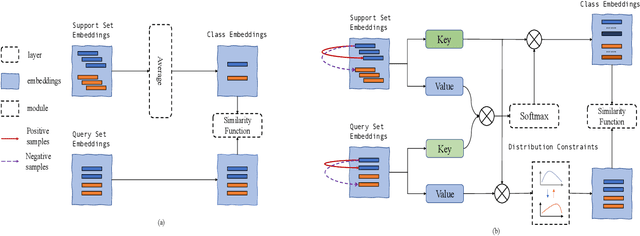

Standard few-shot relation classification (RC) is designed to learn a robust classifier with only few labeled data for each class. However, previous works rarely investigate the effects of a different number of classes (i.e., $N$-way) and number of labeled data per class (i.e., $K$-shot) during training vs. testing. In this work, we define a new task, \textit{inconsistent few-shot RC}, where the model needs to handle the inconsistency of $N$ and $K$ between training and testing. To address this new task, we propose Prototype Network-based cross-attention contrastive learning (ProtoCACL) to capture the rich mutual interactions between the support set and query set. Experimental results demonstrate that our ProtoCACL can outperform the state-of-the-art baseline model under both inconsistent $K$ and inconsistent $N$ settings, owing to its more robust and discriminate representations. Moreover, we identify that in the inconsistent few-shot learning setting, models can achieve better performance with \textit{less data} than the standard few-shot setting with carefully-selected $N$ and $K$. In the end of the paper, we provide further analyses and suggestions to systematically guide the selection of $N$ and $K$ under different scenarios.
Prior Omission of Dissimilar Source Domain(s) for Cost-Effective Few-Shot Learning
Sep 11, 2021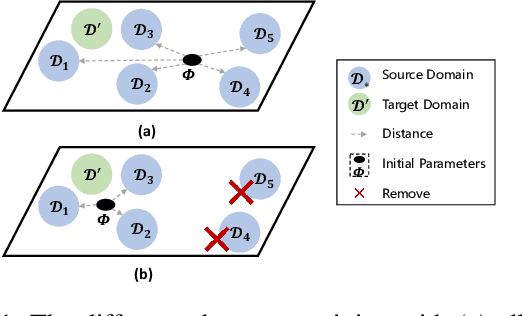
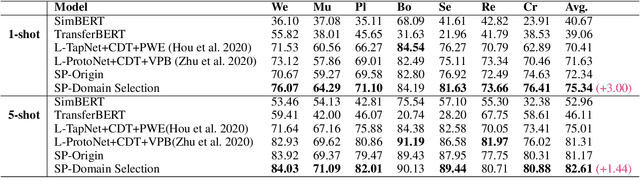
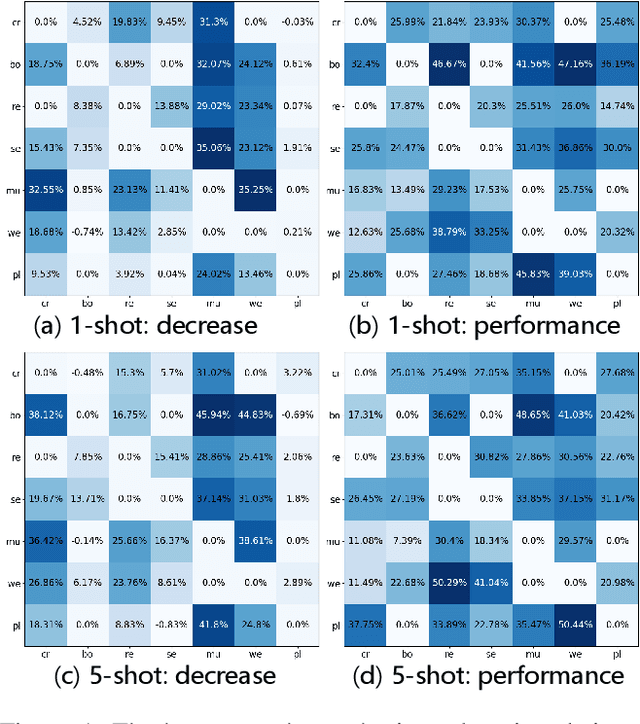
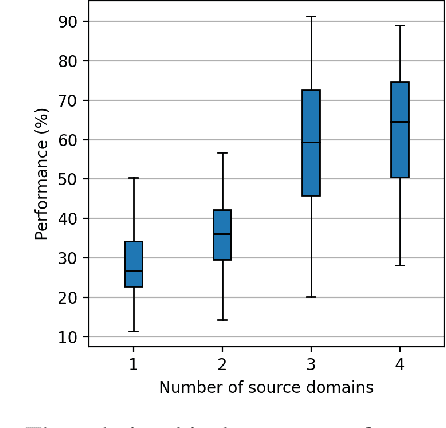
Few-shot slot tagging is an emerging research topic in the field of Natural Language Understanding (NLU). With sufficient annotated data from source domains, the key challenge is how to train and adapt the model to another target domain which only has few labels. Conventional few-shot approaches use all the data from the source domains without considering inter-domain relations and implicitly assume each sample in the domain contributes equally. However, our experiments show that the data distribution bias among different domains will significantly affect the adaption performance. Moreover, transferring knowledge from dissimilar domains will even introduce some extra noises so that affect the performance of models. To tackle this problem, we propose an effective similarity-based method to select data from the source domains. In addition, we propose a Shared-Private Network (SP-Net) for the few-shot slot tagging task. The words from the same class would have some shared features. We extract those shared features from the limited annotated data on the target domain and merge them together as the label embedding to help us predict other unlabelled data on the target domain. The experiment shows that our method outperforms the state-of-the-art approaches with fewer source data. The result also proves that some training data from dissimilar sources are redundant and even negative for the adaption.
TopicRefine: Joint Topic Prediction and Dialogue Response Generation for Multi-turn End-to-End Dialogue System
Sep 11, 2021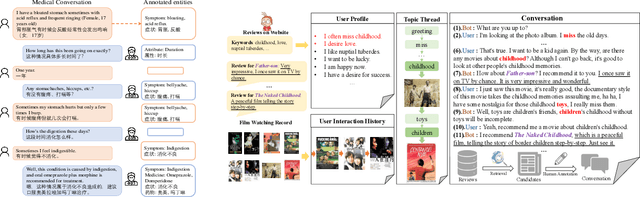
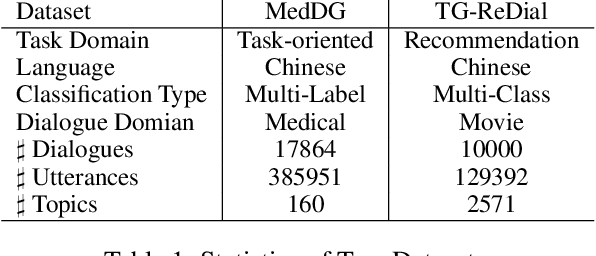
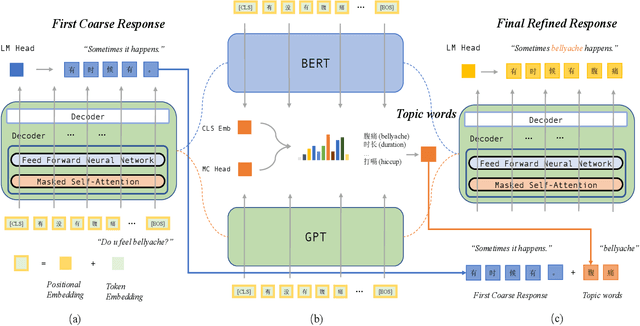
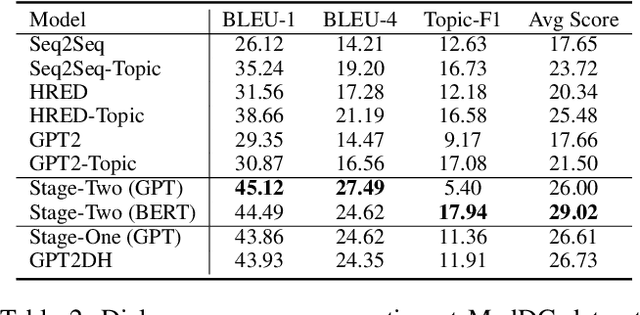
A multi-turn dialogue always follows a specific topic thread, and topic shift at the discourse level occurs naturally as the conversation progresses, necessitating the model's ability to capture different topics and generate topic-aware responses. Previous research has either predicted the topic first and then generated the relevant response, or simply applied the attention mechanism to all topics, ignoring the joint distribution of the topic prediction and response generation models and resulting in uncontrollable and unrelated responses. In this paper, we propose a joint framework with a topic refinement mechanism to learn these two tasks simultaneously. Specifically, we design a three-pass iteration mechanism to generate coarse response first, then predict corresponding topics, and finally generate refined response conditioned on predicted topics. Moreover, we utilize GPT2DoubleHeads and BERT for the topic prediction task respectively, aiming to investigate the effects of joint learning and the understanding ability of GPT model. Experimental results demonstrate that our proposed framework achieves new state-of-the-art performance at response generation task and the great potential understanding capability of GPT model.
MCML: A Novel Memory-based Contrastive Meta-Learning Method for Few Shot Slot Tagging
Aug 28, 2021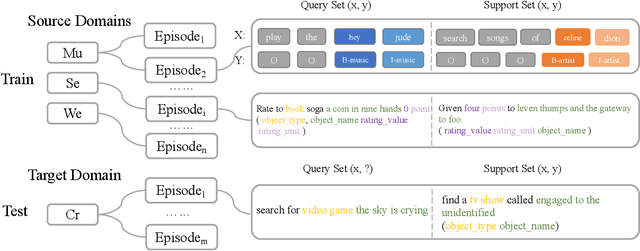
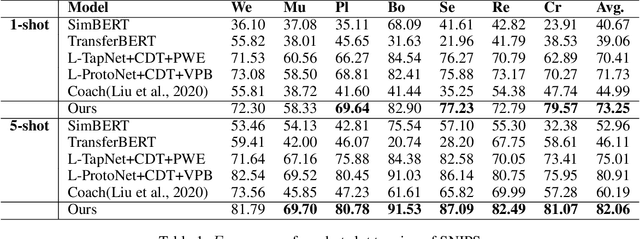
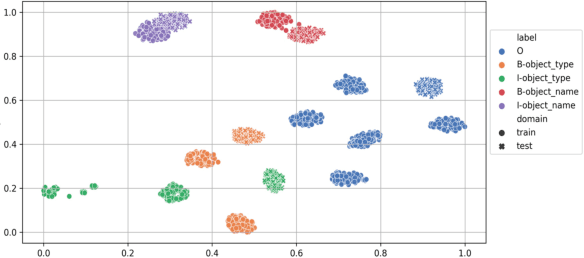
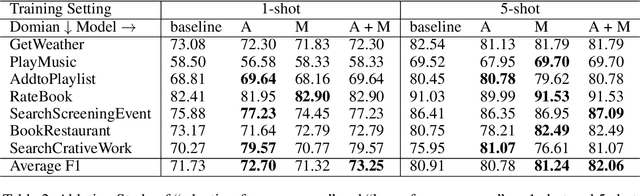
Meta-learning is widely used for few-shot slot tagging in the task of few-shot learning. The performance of existing methods is, however, seriously affected by catastrophic forgetting. This phenomenon is common in deep learning as the training and testing modules fail to take into account historical information, i.e. previously trained episodes in the metric-based meta-learning. To overcome this predicament, we propose the Memory-based Contrastive Meta-learning (MCML) method. Specifically, we propose a learn-from-memory mechanism that use explicit memory to keep track of the label representations of previously trained episodes and propose a contrastive learning method to compare the current label embedded in the few shot episode with the historic ones stored in the memory, and an adaption-from memory mechanism to determine the output label based on the contrast between the input labels embedded in the test episode and the label clusters in the memory. Experimental results show that MCML is scalable and outperforms metric-based meta-learning and optimization-based meta-learning on all 1shot, 5-shot, 10-shot, and 20-shot scenarios of the SNIPS dataset.
KddRES: A Multi-level Knowledge-driven Dialogue Dataset for Restaurant Towards Customized Dialogue System
Nov 18, 2020

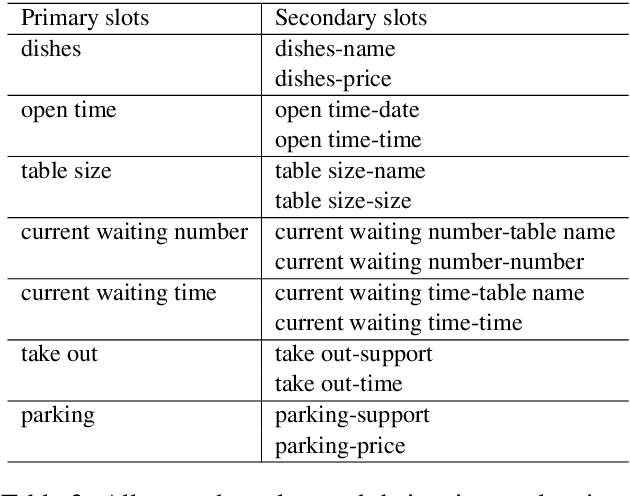
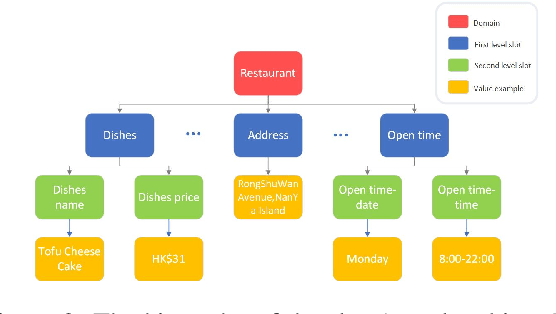
Compared with CrossWOZ (Chinese) and MultiWOZ (English) dataset which have coarse-grained information, there is no dataset which handle fine-grained and hierarchical level information properly. In this paper, we publish a first Cantonese knowledge-driven Dialogue Dataset for REStaurant (KddRES) in Hong Kong, which grounds the information in multi-turn conversations to one specific restaurant. Our corpus contains 0.8k conversations which derive from 10 restaurants with various styles in different regions. In addition to that, we designed fine-grained slots and intents to better capture semantic information. The benchmark experiments and data statistic analysis show the diversity and rich annotations of our dataset. We believe the publish of KddRES can be a necessary supplement of current dialogue datasets and more suitable and valuable for small and middle enterprises (SMEs) of society, such as build a customized dialogue system for each restaurant. The corpus and benchmark models are publicly available.