 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse-softmax: A Simpler and Faster Alternative Softmax Transformation
Dec 23, 2021
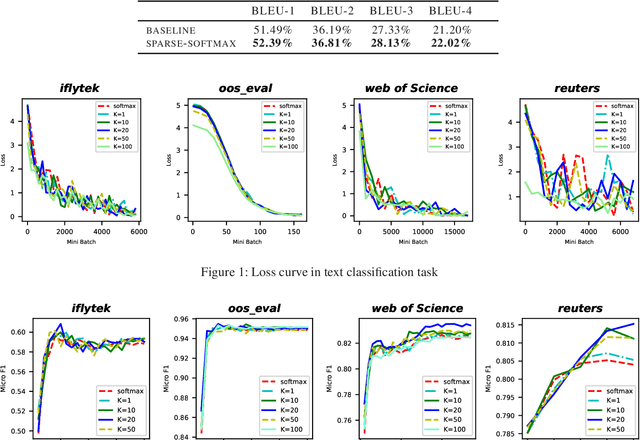
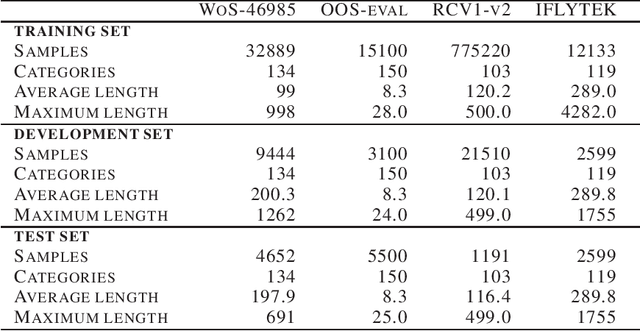
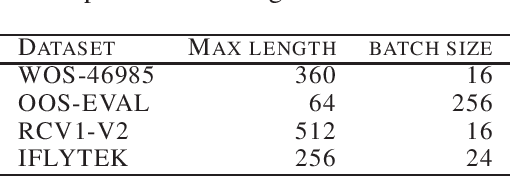
The softmax function is widely used in artificial neural networks for the multiclass classification problems, where the softmax transformation enforces the output to be positive and sum to one, and the corresponding loss function allows to use maximum likelihood principle to optimize the model. However, softmax leaves a large margin for loss function to conduct optimizing operation when it comes to high-dimensional classification, which results in low-performance to some extent. In this paper, we provide an empirical study on a simple and concise softmax variant, namely sparse-softmax, to alleviate the problem that occurred in traditional softmax in terms of high-dimensional classification problems. We evaluate our approach in several interdisciplinary tasks, the experimental results show that sparse-softmax is simpler, faster, and produces better results than the baseline models.
Inconsistent Few-Shot Relation Classification via Cross-Attentional Prototype Networks with Contrastive Learning
Oct 13, 2021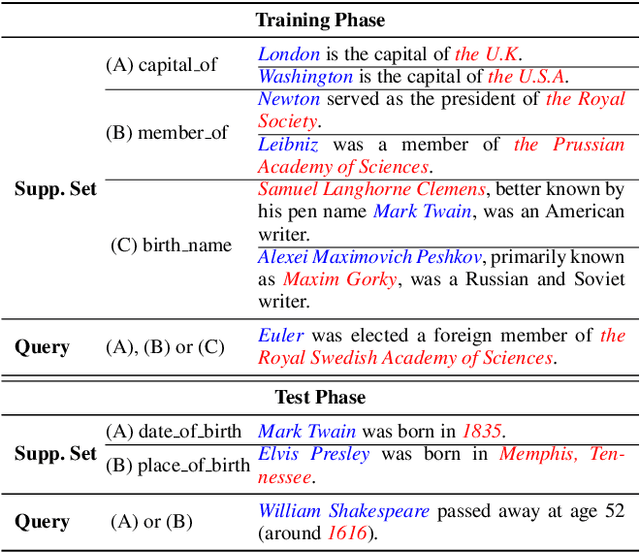
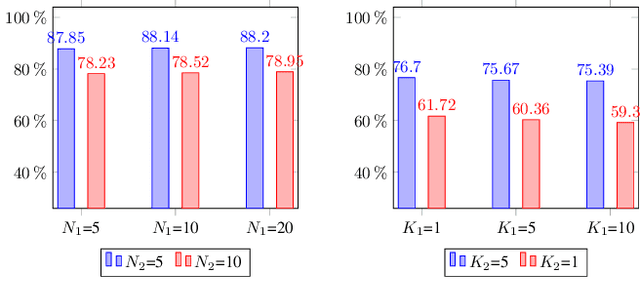
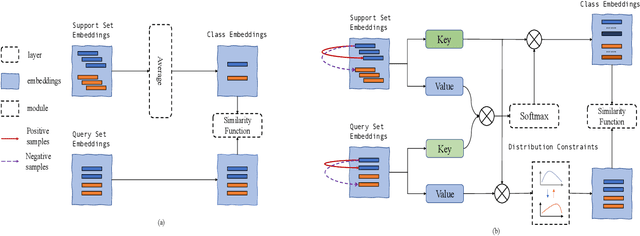

Standard few-shot relation classification (RC) is designed to learn a robust classifier with only few labeled data for each class. However, previous works rarely investigate the effects of a different number of classes (i.e., $N$-way) and number of labeled data per class (i.e., $K$-shot) during training vs. testing. In this work, we define a new task, \textit{inconsistent few-shot RC}, where the model needs to handle the inconsistency of $N$ and $K$ between training and testing. To address this new task, we propose Prototype Network-based cross-attention contrastive learning (ProtoCACL) to capture the rich mutual interactions between the support set and query set. Experimental results demonstrate that our ProtoCACL can outperform the state-of-the-art baseline model under both inconsistent $K$ and inconsistent $N$ settings, owing to its more robust and discriminate representations. Moreover, we identify that in the inconsistent few-shot learning setting, models can achieve better performance with \textit{less data} than the standard few-shot setting with carefully-selected $N$ and $K$. In the end of the paper, we provide further analyses and suggestions to systematically guide the selection of $N$ and $K$ under different scenarios.
EPICURE Ensemble Pretrained Models for Extracting Cancer Mutations from Literature
Jun 11, 2021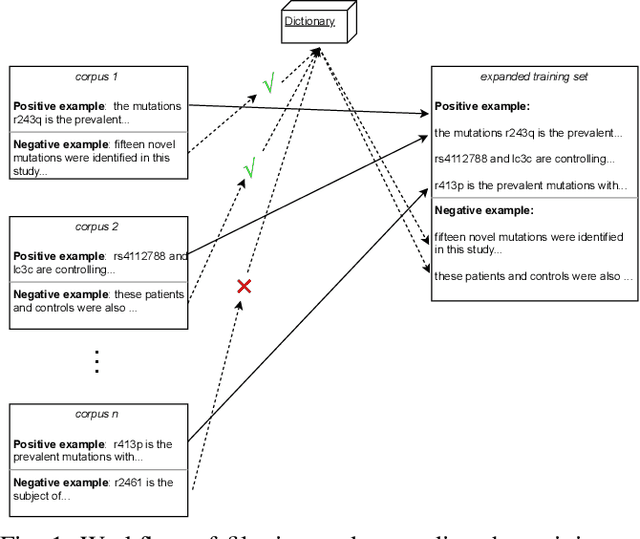
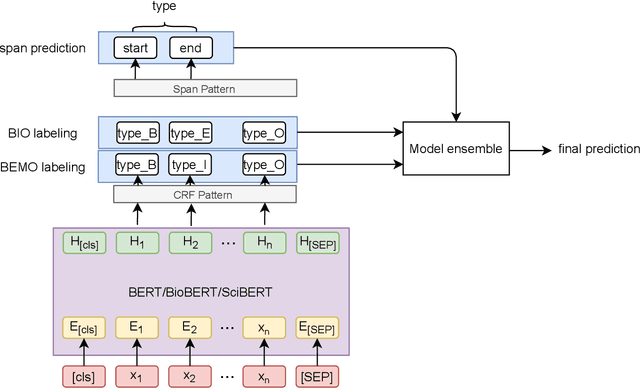

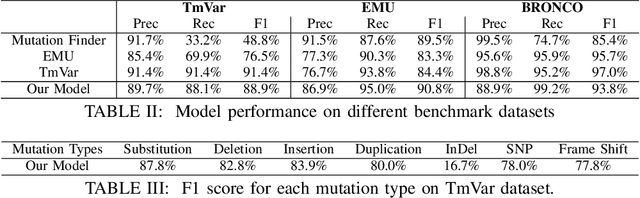
To interpret the genetic profile present in a patient sample, it is necessary to know which mutations have important roles in the development of the corresponding cancer type. Named entity recognition is a core step in the text mining pipeline which facilitates mining valuable cancer information from the scientific literature. However, due to the scarcity of related datasets, previous NER attempts in this domain either suffer from low performance when deep learning based models are deployed, or they apply feature based machine learning models or rule based models to tackle this problem, which requires intensive efforts from domain experts, and limit the model generalization capability. In this paper, we propose EPICURE, an ensemble pre trained model equipped with a conditional random field pattern layer and a span prediction pattern layer to extract cancer mutations from text. We also adopt a data augmentation strategy to expand our training set from multiple datasets. Experimental results on three benchmark datasets show competitive results compared to the baseline models.
Whitening Sentence Representations for Better Semantics and Faster Retrieval
Mar 29, 2021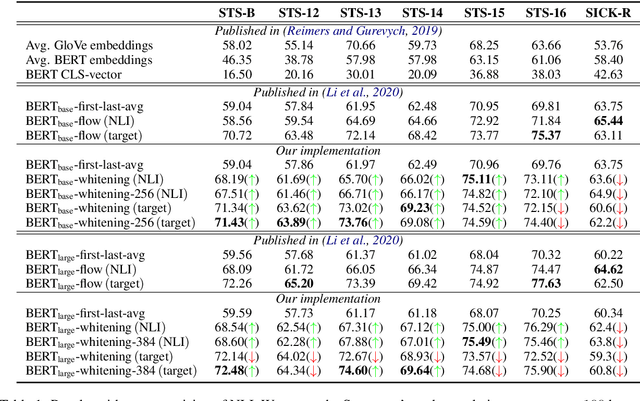
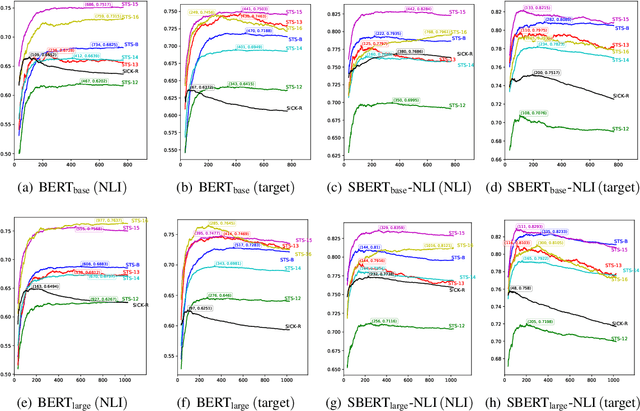
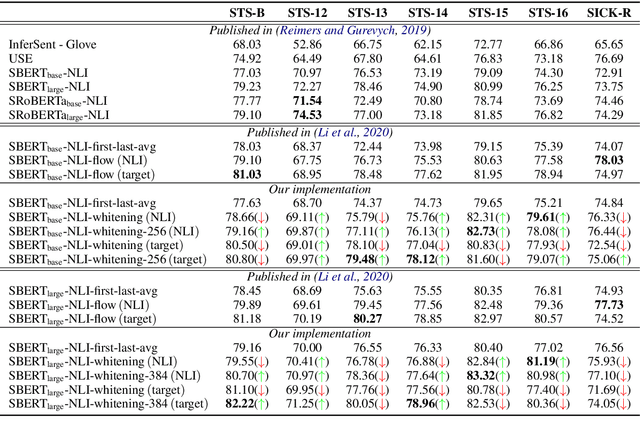
Pre-training models such as BERT have achieved great success in many natural language processing tasks. However, how to obtain better sentence representation through these pre-training models is still worthy to exploit. Previous work has shown that the anisotropy problem is an critical bottleneck for BERT-based sentence representation which hinders the model to fully utilize the underlying semantic features. Therefore, some attempts of boosting the isotropy of sentence distribution, such as flow-based model, have been applied to sentence representations and achieved some improvement. In this paper, we find that the whitening operation in traditional machine learning can similarly enhance the isotropy of sentence representations and achieve competitive results. Furthermore, the whitening technique is also capable of reducing the dimensionality of the sentence representation. Our experimental results show that it can not only achieve promising performance but also significantly reduce the storage cost and accelerate the model retrieval speed.