 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhitening Sentence Representations for Better Semantics and Faster Retrieval
Mar 29, 2021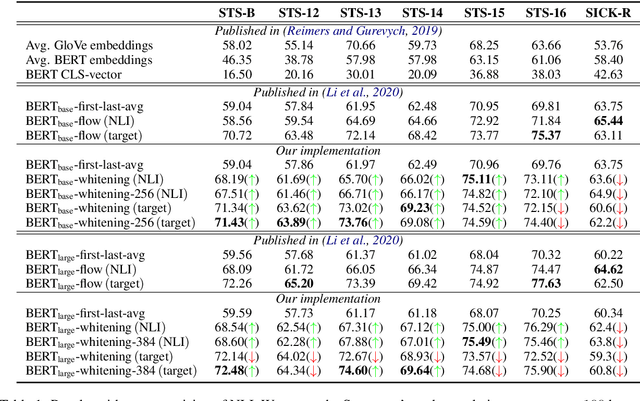
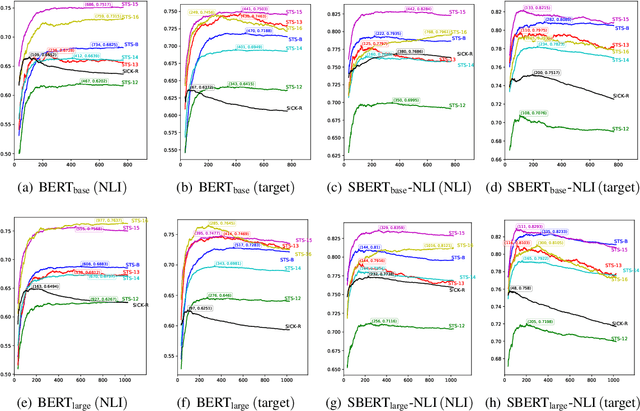
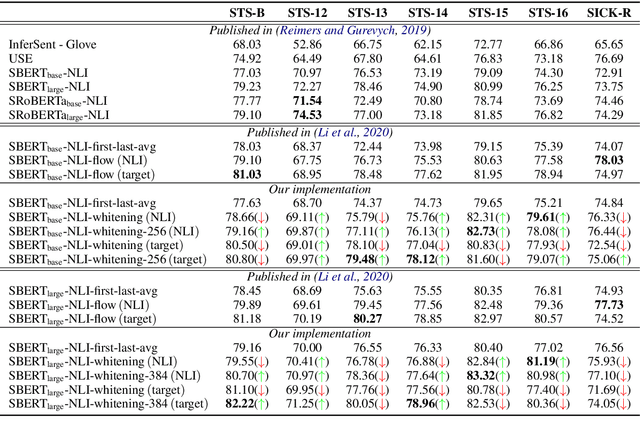
Pre-training models such as BERT have achieved great success in many natural language processing tasks. However, how to obtain better sentence representation through these pre-training models is still worthy to exploit. Previous work has shown that the anisotropy problem is an critical bottleneck for BERT-based sentence representation which hinders the model to fully utilize the underlying semantic features. Therefore, some attempts of boosting the isotropy of sentence distribution, such as flow-based model, have been applied to sentence representations and achieved some improvement. In this paper, we find that the whitening operation in traditional machine learning can similarly enhance the isotropy of sentence representations and achieve competitive results. Furthermore, the whitening technique is also capable of reducing the dimensionality of the sentence representation. Our experimental results show that it can not only achieve promising performance but also significantly reduce the storage cost and accelerate the model retrieval speed.