 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClawNet: Human-Symbiotic Agent Network for Cross-User Autonomous Cooperation
Apr 21, 2026Current AI agent frameworks have made remarkable progress in automating individual tasks, yet all existing systems serve a single user. Human productivity rests on the social and organizational relationships through which people coordinate, negotiate, and delegate. When agents move beyond performing tasks for one person to representing that person in collaboration with others, the infrastructure for cross-user agent collaboration is entirely absent, let alone the governance mechanisms needed to secure it. We argue that the next frontier for AI agents lies not in stronger individual capability, but in the digitization of human collaborative relationships. To this end, we propose a human-symbiotic agent paradigm. Each user owns a permanently bound agent system that collaborates on the owner's behalf, forming a network whose nodes are humans rather than agents. This paradigm rests on three governance primitives. A layered identity architecture separates a Manager Agent from multiple context-specific Identity Agents; the Manager Agent holds global knowledge but is architecturally isolated from external communication. Scoped authorization enforces per-identity access control and escalates boundary violations to the owner. Action-level accountability logs every operation against its owner's identity and authorization, ensuring full auditability. We instantiate this paradigm in ClawNet, an identity-governed agent collaboration framework that enforces identity binding and authorization verification through a central orchestrator, enabling multiple users to collaborate securely through their respective agents.
MemFly: On-the-Fly Memory Optimization via Information Bottleneck
Feb 08, 2026Long-term memory enables large language model agents to tackle complex tasks through historical interactions. However, existing frameworks encounter a fundamental dilemma between compressing redundant information efficiently and maintaining precise retrieval for downstream tasks. To bridge this gap, we propose MemFly, a framework grounded in information bottleneck principles that facilitates on-the-fly memory evolution for LLMs. Our approach minimizes compression entropy while maximizing relevance entropy via a gradient-free optimizer, constructing a stratified memory structure for efficient storage. To fully leverage MemFly, we develop a hybrid retrieval mechanism that seamlessly integrates semantic, symbolic, and topological pathways, incorporating iterative refinement to handle complex multi-hop queries. Comprehensive experiments demonstrate that MemFly substantially outperforms state-of-the-art baselines in memory coherence, response fidelity, and accuracy.
Motion-R1: Chain-of-Thought Reasoning and Reinforcement Learning for Human Motion Generation
Jun 12, 2025Recent advances in large language models, especially in natural language understanding and reasoning, have opened new possibilities for text-to-motion generation. Although existing approaches have made notable progress in semantic alignment and motion synthesis, they often rely on end-to-end mapping strategies that fail to capture deep linguistic structures and logical reasoning. Consequently, generated motions tend to lack controllability, consistency, and diversity. To address these limitations, we propose Motion-R1, a unified motion-language modeling framework that integrates a Chain-of-Thought mechanism. By explicitly decomposing complex textual instructions into logically structured action paths, Motion-R1 provides high-level semantic guidance for motion generation, significantly enhancing the model's ability to interpret and execute multi-step, long-horizon, and compositionally rich commands. To train our model, we adopt Group Relative Policy Optimization, a reinforcement learning algorithm designed for large models, which leverages motion quality feedback to optimize reasoning chains and motion synthesis jointly. Extensive experiments across multiple benchmark datasets demonstrate that Motion-R1 achieves competitive or superior performance compared to state-of-the-art methods, particularly in scenarios requiring nuanced semantic understanding and long-term temporal coherence. The code, model and data will be publicly available.
Adversarial Purification and Fine-tuning for Robust UDC Image Restoration
Feb 21, 2024This study delves into the enhancement of Under-Display Camera (UDC) image restoration models, focusing on their robustness against adversarial attacks. Despite its innovative approach to seamless display integration, UDC technology faces unique image degradation challenges exacerbated by the susceptibility to adversarial perturbations. Our research initially conducts an in-depth robustness evaluation of deep-learning-based UDC image restoration models by employing several white-box and black-box attacking methods. This evaluation is pivotal in understanding the vulnerabilities of current UDC image restoration techniques. Following the assessment, we introduce a defense framework integrating adversarial purification with subsequent fine-tuning processes. First, our approach employs diffusion-based adversarial purification, effectively neutralizing adversarial perturbations. Then, we apply the fine-tuning methodologies to refine the image restoration models further, ensuring that the quality and fidelity of the restored images are maintained. The effectiveness of our proposed approach is validated through extensive experiments, showing marked improvements in resilience against typical adversarial attacks.
Benchmarking Ultra-High-Definition Image Reflection Removal
Aug 01, 2023Deep learning based methods have achieved significant success in the task of single image reflection removal (SIRR). However, the majority of these methods are focused on High-Definition/Standard-Definition (HD/SD) images, while ignoring higher resolution images such as Ultra-High-Definition (UHD) images. With the increasing prevalence of UHD images captured by modern devices, in this paper, we aim to address the problem of UHD SIRR. Specifically, we first synthesize two large-scale UHD datasets, UHDRR4K and UHDRR8K. The UHDRR4K dataset consists of $2,999$ and $168$ quadruplets of images for training and testing respectively, and the UHDRR8K dataset contains $1,014$ and $105$ quadruplets. To the best of our knowledge, these two datasets are the first largest-scale UHD datasets for SIRR. Then, we conduct a comprehensive evaluation of six state-of-the-art SIRR methods using the proposed datasets. Based on the results, we provide detailed discussions regarding the strengths and limitations of these methods when applied to UHD images. Finally, we present a transformer-based architecture named RRFormer for reflection removal. RRFormer comprises three modules, namely the Prepossessing Embedding Module, Self-attention Feature Extraction Module, and Multi-scale Spatial Feature Extraction Module. These modules extract hypercolumn features, global and partial attention features, and multi-scale spatial features, respectively. To ensure effective training, we utilize three terms in our loss function: pixel loss, feature loss, and adversarial loss. We demonstrate through experimental results that RRFormer achieves state-of-the-art performance on both the non-UHD dataset and our proposed UHDRR datasets. The code and datasets are publicly available at https://github.com/Liar-zzy/Benchmarking-Ultra-High-Definition-Single-Image-Reflection-Removal.
RWKV: Reinventing RNNs for the Transformer Era
May 22, 2023



Transformers have revolutionized almost all natural language processing (NLP) tasks but suffer from memory and computational complexity that scales quadratically with sequence length. In contrast, recurrent neural networks (RNNs) exhibit linear scaling in memory and computational requirements but struggle to match the same performance as Transformers due to limitations in parallelization and scalability. We propose a novel model architecture, Receptance Weighted Key Value (RWKV), that combines the efficient parallelizable training of Transformers with the efficient inference of RNNs. Our approach leverages a linear attention mechanism and allows us to formulate the model as either a Transformer or an RNN, which parallelizes computations during training and maintains constant computational and memory complexity during inference, leading to the first non-transformer architecture to be scaled to tens of billions of parameters. Our experiments reveal that RWKV performs on par with similarly sized Transformers, suggesting that future work can leverage this architecture to create more efficient models. This work presents a significant step towards reconciling the trade-offs between computational efficiency and model performance in sequence processing tasks.
FedDTG:Federated Data-Free Knowledge Distillation via Three-Player Generative Adversarial Networks
Jan 10, 2022


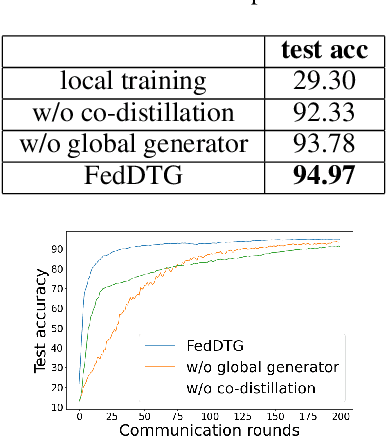
Applying knowledge distillation to personalized cross-silo federated learning can well alleviate the problem of user heterogeneity. This approach, however, requires a proxy dataset, which is difficult to obtain in the real world. Moreover, the global model based on parameter averaging will lead to the leakage of user privacy. We introduce a distributed three-player GAN to implement datafree co-distillation between clients. This technique mitigates the user heterogeneity problem and better protects user privacy. We confirmed that thefake samples generated by GAN can make federated distillation more efficient and robust, and the co-distillation can achieve good performance for individual clients on the basis of obtaining global knowledge. Our extensive experiments on benchmark datasets demonstrate the superior generalization performance of the proposed methods, compared with the state-of-the-art.
Sparse-softmax: A Simpler and Faster Alternative Softmax Transformation
Dec 23, 2021
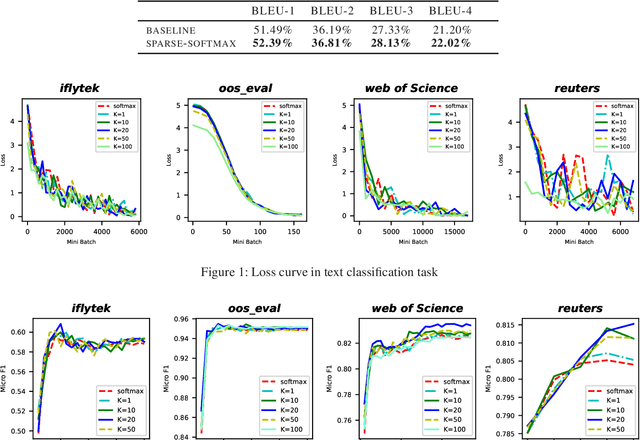
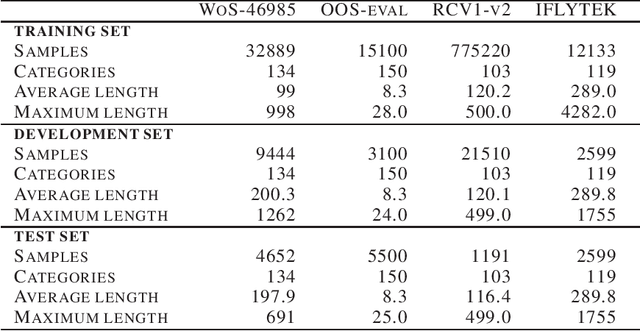
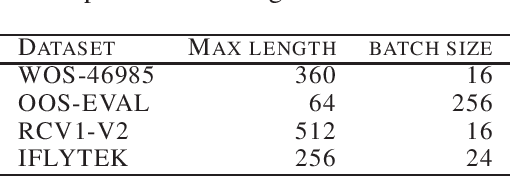
The softmax function is widely used in artificial neural networks for the multiclass classification problems, where the softmax transformation enforces the output to be positive and sum to one, and the corresponding loss function allows to use maximum likelihood principle to optimize the model. However, softmax leaves a large margin for loss function to conduct optimizing operation when it comes to high-dimensional classification, which results in low-performance to some extent. In this paper, we provide an empirical study on a simple and concise softmax variant, namely sparse-softmax, to alleviate the problem that occurred in traditional softmax in terms of high-dimensional classification problems. We evaluate our approach in several interdisciplinary tasks, the experimental results show that sparse-softmax is simpler, faster, and produces better results than the baseline models.
TAMPC: A Controller for Escaping Traps in Novel Environments
Oct 23, 2020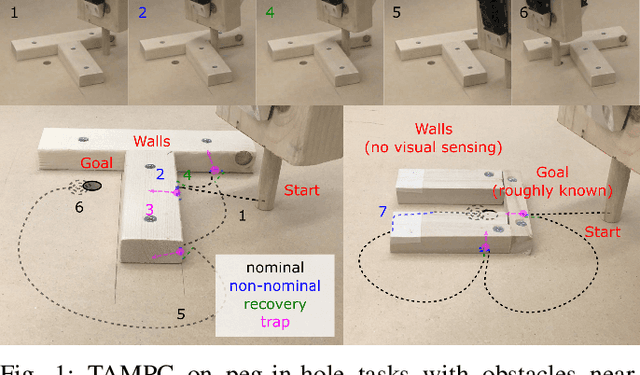
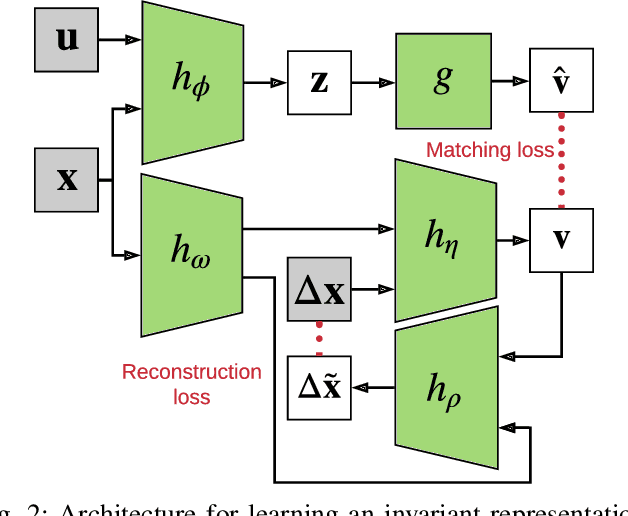


We propose an approach to online model adaptation and control in the challenging case of hybrid and discontinuous dynamics where actions may lead to difficult-to-escape "trap" states. We first learn dynamics for a given system from training data which does not contain unexpected traps (since we do not know what traps will be encountered online). These "nominal" dynamics allow us to perform tasks under ideal conditions, but when unexpected traps arise in execution, we must find a way to adapt our dynamics and control strategy and continue attempting the task. Our approach, Trap-Aware Model Predictive Control (TAMPC), is a two-level hierarchical control algorithm that reasons about traps and non-nominal dynamics to decide between goal-seeking and recovery policies. An important requirement of our method is the ability to recognize nominal dynamics even when we encounter data that is out-of-distribution w.r.t the training data. We achieve this by learning a representation for dynamics that exploits invariance in the nominal environment, thus allowing better generalization. We evaluate our method on simulated planar pushing and peg-in-hole as well as real robot peg-in-hole problems against adaptive control and reinforcement learning baselines, where traps arise due to unexpected obstacles that we only observe through contact. Our results show that our method significantly outperforms the baselines in all tested scenarios.