 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2K Retrofit: Entropy-Guided Efficient Sparse Refinement for High-Resolution 3D Geometry Prediction
Mar 23, 2026High-resolution geometric prediction is essential for robust perception in autonomous driving, robotics, and AR/MR, but current foundation models are fundamentally limited by their scalability to real-world, high-resolution scenarios. Direct inference on 2K images with these models incurs prohibitive computational and memory demands, making practical deployment challenging. To tackle the issue, we present 2K Retrofit, a novel framework that enables efficient 2K-resolution inference for any geometric foundation model, without modifying or retraining the backbone. Our approach leverages fast coarse predictions and an entropy-based sparse refinement to selectively enhance high-uncertainty regions, achieving precise and high-fidelity 2K outputs with minimal overhead. Extensive experiments on widely used benchmark demonstrate that 2K Retrofit consistently achieves state-of-the-art accuracy and speed, bridging the gap between research advances and scalable deployment in high-resolution 3D vision applications. Code will be released upon acceptance.
MemFly: On-the-Fly Memory Optimization via Information Bottleneck
Feb 08, 2026Long-term memory enables large language model agents to tackle complex tasks through historical interactions. However, existing frameworks encounter a fundamental dilemma between compressing redundant information efficiently and maintaining precise retrieval for downstream tasks. To bridge this gap, we propose MemFly, a framework grounded in information bottleneck principles that facilitates on-the-fly memory evolution for LLMs. Our approach minimizes compression entropy while maximizing relevance entropy via a gradient-free optimizer, constructing a stratified memory structure for efficient storage. To fully leverage MemFly, we develop a hybrid retrieval mechanism that seamlessly integrates semantic, symbolic, and topological pathways, incorporating iterative refinement to handle complex multi-hop queries. Comprehensive experiments demonstrate that MemFly substantially outperforms state-of-the-art baselines in memory coherence, response fidelity, and accuracy.
APD-Agents: A Large Language Model-Driven Multi-Agents Collaborative Framework for Automated Page Design
Nov 18, 2025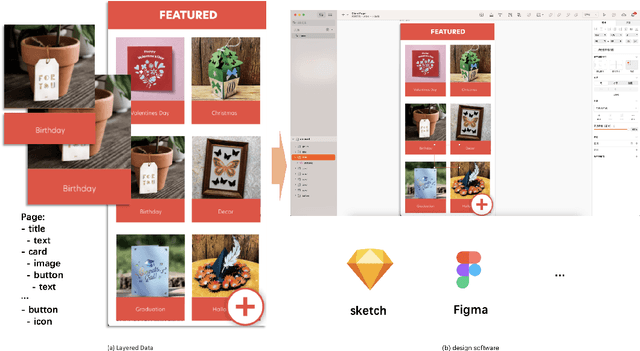
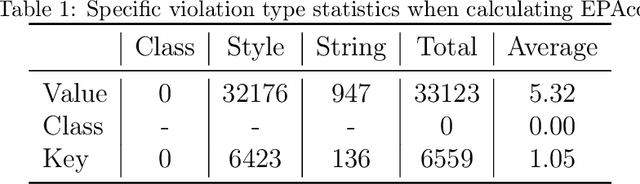
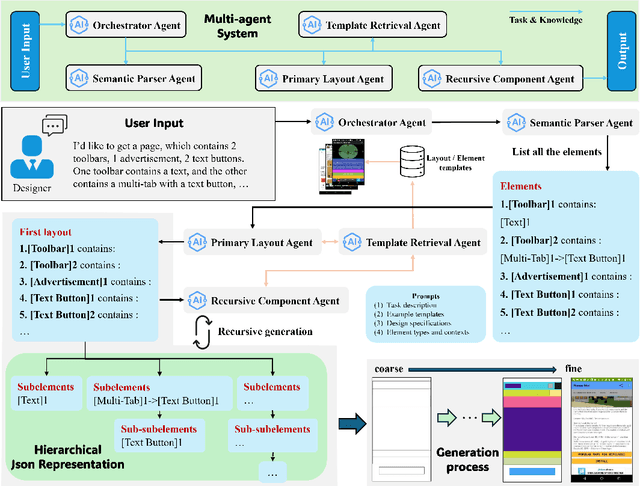
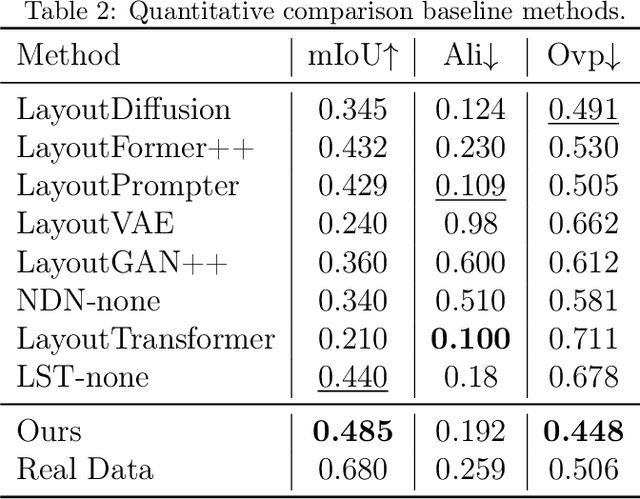
Layout design is a crucial step in developing mobile app pages. However, crafting satisfactory designs is time-intensive for designers: they need to consider which controls and content to present on the page, and then repeatedly adjust their size, position, and style for better aesthetics and structure. Although many design software can now help to perform these repetitive tasks, extensive training is needed to use them effectively. Moreover, collaborative design across app pages demands extra time to align standards and ensure consistent styling. In this work, we propose APD-agents, a large language model (LLM) driven multi-agent framework for automated page design in mobile applications. Our framework contains OrchestratorAgent, SemanticParserAgent, PrimaryLayoutAgent, TemplateRetrievalAgent, and RecursiveComponentAgent. Upon receiving the user's description of the page, the OrchestratorAgent can dynamically can direct other agents to accomplish users' design task. To be specific, the SemanticParserAgent is responsible for converting users' descriptions of page content into structured data. The PrimaryLayoutAgent can generate an initial coarse-grained layout of this page. The TemplateRetrievalAgent can fetch semantically relevant few-shot examples and enhance the quality of layout generation. Besides, a RecursiveComponentAgent can be used to decide how to recursively generate all the fine-grained sub-elements it contains for each element in the layout. Our work fully leverages the automatic collaboration capabilities of large-model-driven multi-agent systems. Experimental results on the RICO dataset show that our APD-agents achieve state-of-the-art performance.
MimicDreamer: Aligning Human and Robot Demonstrations for Scalable VLA Training
Sep 26, 2025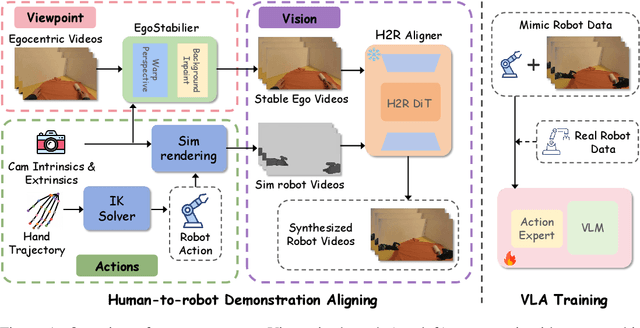

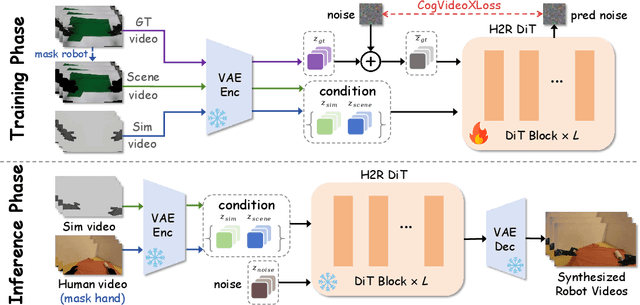
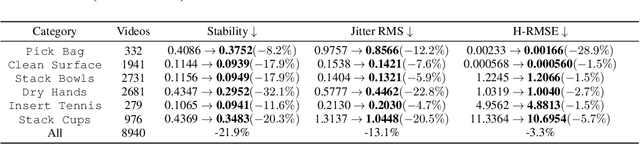
Vision Language Action (VLA) models derive their generalization capability from diverse training data, yet collecting embodied robot interaction data remains prohibitively expensive. In contrast, human demonstration videos are far more scalable and cost-efficient to collect, and recent studies confirm their effectiveness in training VLA models. However, a significant domain gap persists between human videos and robot-executed videos, including unstable camera viewpoints, visual discrepancies between human hands and robotic arms, and differences in motion dynamics. To bridge this gap, we propose MimicDreamer, a framework that turns fast, low-cost human demonstrations into robot-usable supervision by jointly aligning vision, viewpoint, and actions to directly support policy training. For visual alignment, we propose H2R Aligner, a video diffusion model that generates high-fidelity robot demonstration videos by transferring motion from human manipulation footage. For viewpoint stabilization, EgoStabilizer is proposed, which canonicalizes egocentric videos via homography and inpaints occlusions and distortions caused by warping. For action alignment, we map human hand trajectories to the robot frame and apply a constrained inverse kinematics solver to produce feasible, low-jitter joint commands with accurate pose tracking. Empirically, VLA models trained purely on our synthesized human-to-robot videos achieve few-shot execution on real robots. Moreover, scaling training with human data significantly boosts performance compared to models trained solely on real robot data; our approach improves the average success rate by 14.7\% across six representative manipulation tasks.
HieroAction: Hierarchically Guided VLM for Fine-Grained Action Analysis
Aug 23, 2025Evaluating human actions with clear and detailed feedback is important in areas such as sports, healthcare, and robotics, where decisions rely not only on final outcomes but also on interpretable reasoning. However, most existing methods provide only a final score without explanation or detailed analysis, limiting their practical applicability. To address this, we introduce HieroAction, a vision-language model that delivers accurate and structured assessments of human actions. HieroAction builds on two key ideas: (1) Stepwise Action Reasoning, a tailored chain of thought process designed specifically for action assessment, which guides the model to evaluate actions step by step, from overall recognition through sub action analysis to final scoring, thus enhancing interpretability and structured understanding; and (2) Hierarchical Policy Learning, a reinforcement learning strategy that enables the model to learn fine grained sub action dynamics and align them with high level action quality, thereby improving scoring precision. The reasoning pathway structures the evaluation process, while policy learning refines each stage through reward based optimization. Their integration ensures accurate and interpretable assessments, as demonstrated by superior performance across multiple benchmark datasets. Code will be released upon acceptance.
Controllable Satellite-to-Street-View Synthesis with Precise Pose Alignment and Zero-Shot Environmental Control
Feb 05, 2025
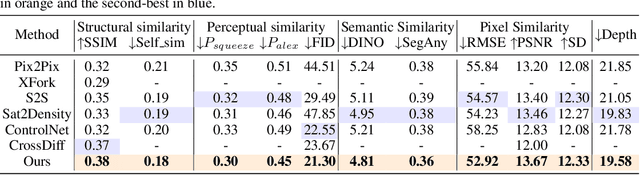
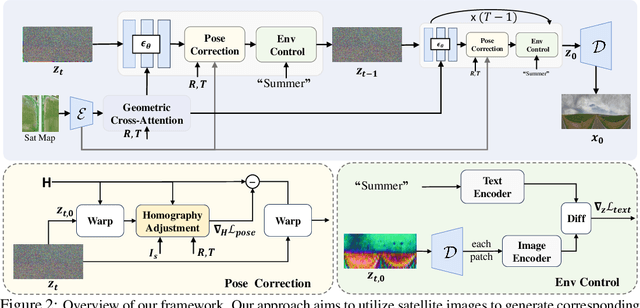
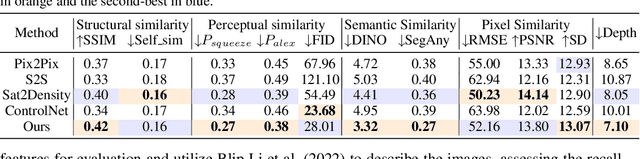
Generating street-view images from satellite imagery is a challenging task, particularly in maintaining accurate pose alignment and incorporating diverse environmental conditions. While diffusion models have shown promise in generative tasks, their ability to maintain strict pose alignment throughout the diffusion process is limited. In this paper, we propose a novel Iterative Homography Adjustment (IHA) scheme applied during the denoising process, which effectively addresses pose misalignment and ensures spatial consistency in the generated street-view images. Additionally, currently, available datasets for satellite-to-street-view generation are limited in their diversity of illumination and weather conditions, thereby restricting the generalizability of the generated outputs. To mitigate this, we introduce a text-guided illumination and weather-controlled sampling strategy that enables fine-grained control over the environmental factors. Extensive quantitative and qualitative evaluations demonstrate that our approach significantly improves pose accuracy and enhances the diversity and realism of generated street-view images, setting a new benchmark for satellite-to-street-view generation tasks.
AS-FIBA: Adaptive Selective Frequency-Injection for Backdoor Attack on Deep Face Restoration
Mar 11, 2024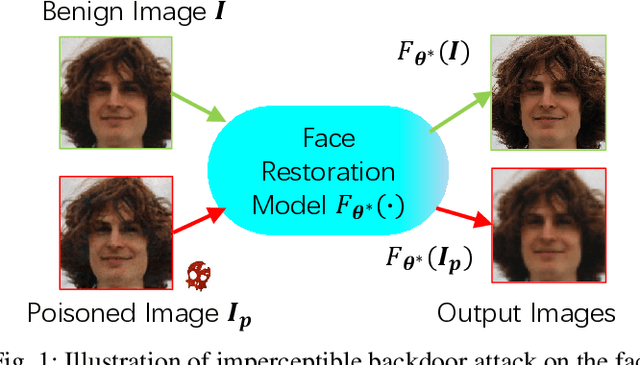
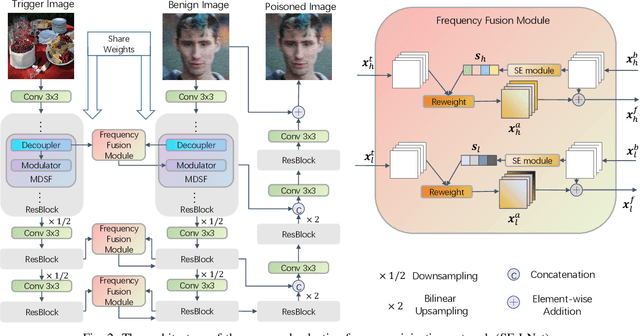
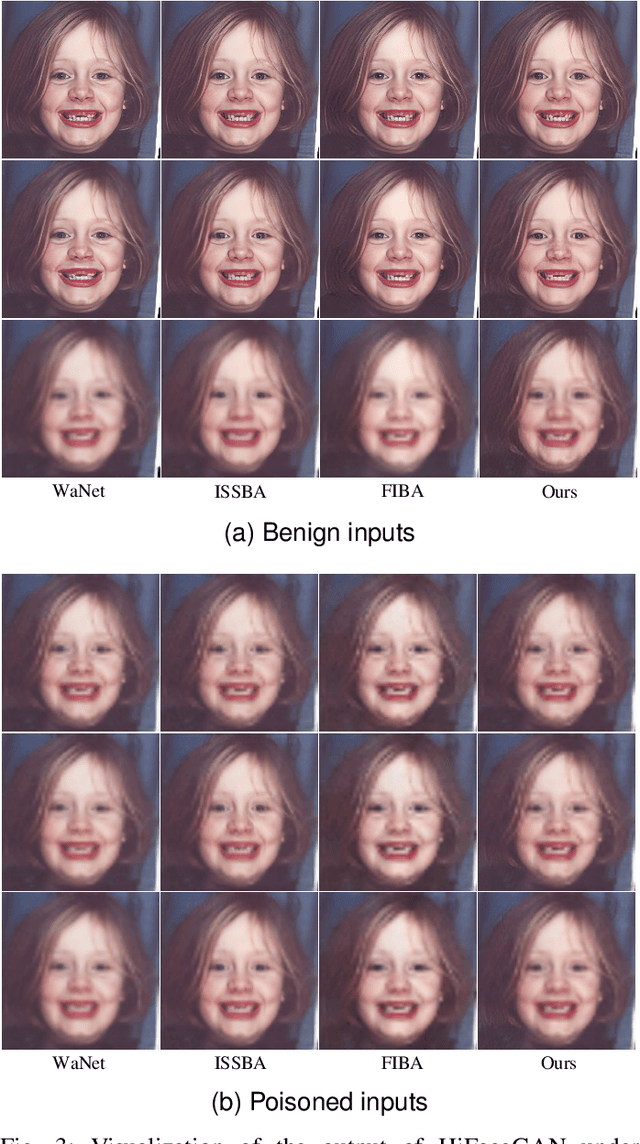

Deep learning-based face restoration models, increasingly prevalent in smart devices, have become targets for sophisticated backdoor attacks. These attacks, through subtle trigger injection into input face images, can lead to unexpected restoration outcomes. Unlike conventional methods focused on classification tasks, our approach introduces a unique degradation objective tailored for attacking restoration models. Moreover, we propose the Adaptive Selective Frequency Injection Backdoor Attack (AS-FIBA) framework, employing a neural network for input-specific trigger generation in the frequency domain, seamlessly blending triggers with benign images. This results in imperceptible yet effective attacks, guiding restoration predictions towards subtly degraded outputs rather than conspicuous targets. Extensive experiments demonstrate the efficacy of the degradation objective on state-of-the-art face restoration models. Additionally, it is notable that AS-FIBA can insert effective backdoors that are more imperceptible than existing backdoor attack methods, including WaNet, ISSBA, and FIBA.
Adversarial Purification and Fine-tuning for Robust UDC Image Restoration
Feb 21, 2024This study delves into the enhancement of Under-Display Camera (UDC) image restoration models, focusing on their robustness against adversarial attacks. Despite its innovative approach to seamless display integration, UDC technology faces unique image degradation challenges exacerbated by the susceptibility to adversarial perturbations. Our research initially conducts an in-depth robustness evaluation of deep-learning-based UDC image restoration models by employing several white-box and black-box attacking methods. This evaluation is pivotal in understanding the vulnerabilities of current UDC image restoration techniques. Following the assessment, we introduce a defense framework integrating adversarial purification with subsequent fine-tuning processes. First, our approach employs diffusion-based adversarial purification, effectively neutralizing adversarial perturbations. Then, we apply the fine-tuning methodologies to refine the image restoration models further, ensuring that the quality and fidelity of the restored images are maintained. The effectiveness of our proposed approach is validated through extensive experiments, showing marked improvements in resilience against typical adversarial attacks.
Learning Dense Flow Field for Highly-accurate Cross-view Camera Localization
Sep 27, 2023



This paper addresses the problem of estimating the 3-DoF camera pose for a ground-level image with respect to a satellite image that encompasses the local surroundings. We propose a novel end-to-end approach that leverages the learning of dense pixel-wise flow fields in pairs of ground and satellite images to calculate the camera pose. Our approach differs from existing methods by constructing the feature metric at the pixel level, enabling full-image supervision for learning distinctive geometric configurations and visual appearances across views. Specifically, our method employs two distinct convolution networks for ground and satellite feature extraction. Then, we project the ground feature map to the bird's eye view (BEV) using a fixed camera height assumption to achieve preliminary geometric alignment. To further establish content association between the BEV and satellite features, we introduce a residual convolution block to refine the projected BEV feature. Optical flow estimation is performed on the refined BEV feature map and the satellite feature map using flow decoder networks based on RAFT. After obtaining dense flow correspondences, we apply the least square method to filter matching inliers and regress the ground camera pose. Extensive experiments demonstrate significant improvements compared to state-of-the-art methods. Notably, our approach reduces the median localization error by 89%, 19%, 80% and 35% on the KITTI, Ford multi-AV, VIGOR and Oxford RobotCar datasets, respectively.
STDG: Semi-Teacher-Student Training Paradigram for Depth-guided One-stage Scene Graph Generation
Sep 15, 2023



Scene Graph Generation is a critical enabler of environmental comprehension for autonomous robotic systems. Most of existing methods, however, are often thwarted by the intricate dynamics of background complexity, which limits their ability to fully decode the inherent topological information of the environment. Additionally, the wealth of contextual information encapsulated within depth cues is often left untapped, rendering existing approaches less effective. To address these shortcomings, we present STDG, an avant-garde Depth-Guided One-Stage Scene Graph Generation methodology. The innovative architecture of STDG is a triad of custom-built modules: The Depth Guided HHA Representation Generation Module, the Depth Guided Semi-Teaching Network Learning Module, and the Depth Guided Scene Graph Generation Module. This trifecta of modules synergistically harnesses depth information, covering all aspects from depth signal generation and depth feature utilization, to the final scene graph prediction. Importantly, this is achieved without imposing additional computational burden during the inference phase. Experimental results confirm that our method significantly enhances the performance of one-stage scene graph generation baselines.