 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIDS: Domain Impact-aware Data Sampling for Large Language Model Training
Apr 17, 2025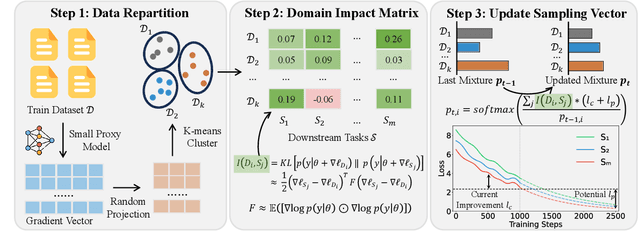


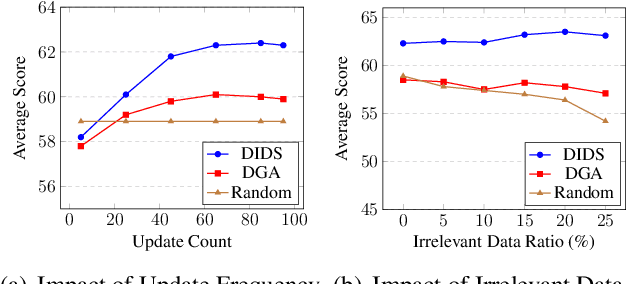
Large language models (LLMs) are commonly trained on multi-domain datasets, where domain sampling strategies significantly impact model performance due to varying domain importance across downstream tasks. Existing approaches for optimizing domain-level sampling strategies struggle with maintaining intra-domain consistency and accurately measuring domain impact. In this paper, we present Domain Impact-aware Data Sampling (DIDS). To ensure intra-domain consistency, a gradient clustering algorithm is proposed to group training data based on their learning effects, where a proxy language model and dimensionality reduction are employed to reduce computational overhead. To accurately measure domain impact, we develop a Fisher Information Matrix (FIM) guided metric that quantifies how domain-specific parameter updates affect the model's output distributions on downstream tasks, with theoretical guarantees. Furthermore, to determine optimal sampling ratios, DIDS combines both the FIM-guided domain impact assessment and loss learning trajectories that indicate domain-specific potential, while accounting for diminishing marginal returns. Extensive experiments demonstrate that DIDS achieves 3.4% higher average performance while maintaining comparable training efficiency.
Unit Region Encoding: A Unified and Compact Geometry-aware Representation for Floorplan Applications
Jan 19, 2025We present the Unit Region Encoding of floorplans, which is a unified and compact geometry-aware encoding representation for various applications, ranging from interior space planning, floorplan metric learning to floorplan generation tasks. The floorplans are represented as the latent encodings on a set of boundary-adaptive unit region partition based on the clustering of the proposed geometry-aware density map. The latent encodings are extracted by a trained network (URE-Net) from the input dense density map and other available semantic maps. Compared to the over-segmented rasterized images and the room-level graph structures, our representation can be flexibly adapted to different applications with the sliced unit regions while achieving higher accuracy performance and better visual quality. We conduct a variety of experiments and compare to the state-of-the-art methods on the aforementioned applications to validate the superiority of our representation, as well as extensive ablation studies to demonstrate the effect of our slicing choices.
LocRef-Diffusion:Tuning-Free Layout and Appearance-Guided Generation
Nov 22, 2024



Recently, text-to-image models based on diffusion have achieved remarkable success in generating high-quality images. However, the challenge of personalized, controllable generation of instances within these images remains an area in need of further development. In this paper, we present LocRef-Diffusion, a novel, tuning-free model capable of personalized customization of multiple instances' appearance and position within an image. To enhance the precision of instance placement, we introduce a Layout-net, which controls instance generation locations by leveraging both explicit instance layout information and an instance region cross-attention module. To improve the appearance fidelity to reference images, we employ an appearance-net that extracts instance appearance features and integrates them into the diffusion model through cross-attention mechanisms. We conducted extensive experiments on the COCO and OpenImages datasets, and the results demonstrate that our proposed method achieves state-of-the-art performance in layout and appearance guided generation.