 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocRef-Diffusion:Tuning-Free Layout and Appearance-Guided Generation
Nov 22, 2024



Recently, text-to-image models based on diffusion have achieved remarkable success in generating high-quality images. However, the challenge of personalized, controllable generation of instances within these images remains an area in need of further development. In this paper, we present LocRef-Diffusion, a novel, tuning-free model capable of personalized customization of multiple instances' appearance and position within an image. To enhance the precision of instance placement, we introduce a Layout-net, which controls instance generation locations by leveraging both explicit instance layout information and an instance region cross-attention module. To improve the appearance fidelity to reference images, we employ an appearance-net that extracts instance appearance features and integrates them into the diffusion model through cross-attention mechanisms. We conducted extensive experiments on the COCO and OpenImages datasets, and the results demonstrate that our proposed method achieves state-of-the-art performance in layout and appearance guided generation.
Learn to Cluster Faces with Better Subgraphs
Apr 21, 2023



Face clustering can provide pseudo-labels to the massive unlabeled face data and improve the performance of different face recognition models. The existing clustering methods generally aggregate the features within subgraphs that are often implemented based on a uniform threshold or a learned cutoff position. This may reduce the recall of subgraphs and hence degrade the clustering performance. This work proposed an efficient neighborhood-aware subgraph adjustment method that can significantly reduce the noise and improve the recall of the subgraphs, and hence can drive the distant nodes to converge towards the same centers. More specifically, the proposed method consists of two components, i.e. face embeddings enhancement using the embeddings from neighbors, and enclosed subgraph construction of node pairs for structural information extraction. The embeddings are combined to predict the linkage probabilities for all node pairs to replace the cosine similarities to produce new subgraphs that can be further used for aggregation of GCNs or other clustering methods. The proposed method is validated through extensive experiments against a range of clustering solutions using three benchmark datasets and numerical results confirm that it outperforms the SOTA solutions in terms of generalization capability.
A robust deep learning-based damage identification approach for SHM considering missing data
Mar 31, 2023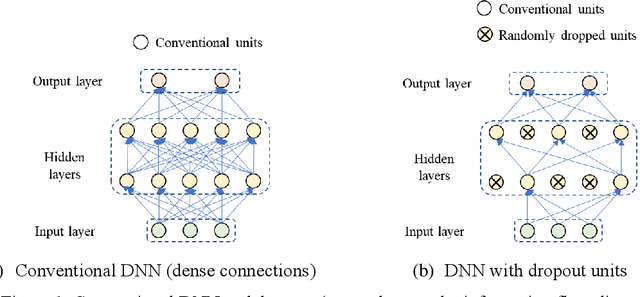
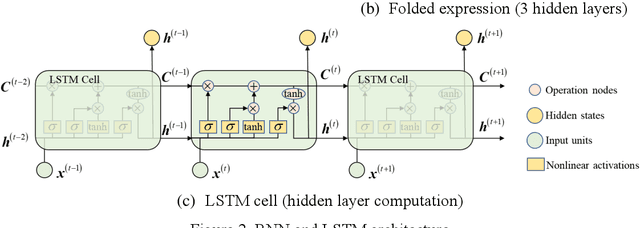
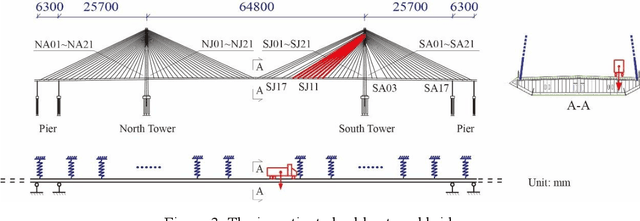
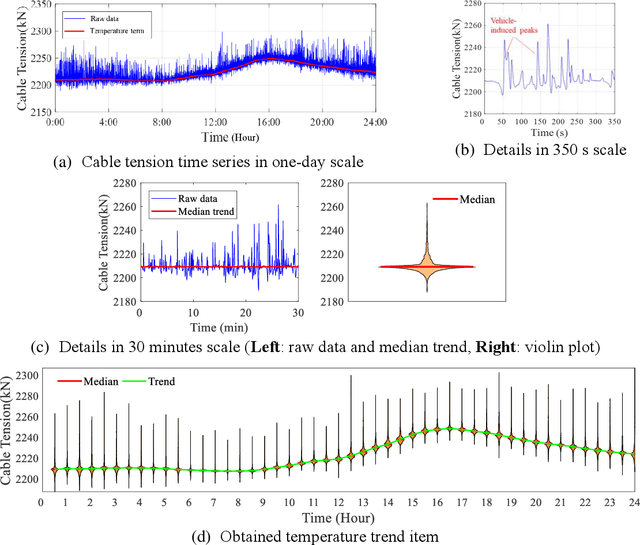
Data-driven method for Structural Health Monitoring (SHM), that mine the hidden structural performance from the correlations among monitored time series data, has received widely concerns recently. However, missing data significantly impacts the conduction of this method. Missing data is a frequently encountered issue in time series data in SHM and many other real-world applications, that harms to the standardized data mining and downstream tasks, such as condition assessment. Imputation approaches based on spatiotemporal relations among monitoring data are developed to handle this issue, however, no additional information is added during imputation. This paper thus develops a robust method for damage identification that considers the missing data occasions, based on long-short term memory (LSTM) model and dropout mechanism in the autoencoder (AE) framework. Inputs channels are randomly dropped to simulate the missing data in training, and reconstruction errors are used as the loss function and the damage indicator. Quasi-static response (cable tension) of a cable-stayed bridge released in 1st IPC-SHM is employed to verify this proposed method, and results show that the missing data imputation and damage identification can be implemented together in a unified way.
RobustFusion: Robust Volumetric Performance Reconstruction under Human-object Interactions from Monocular RGBD Stream
Apr 30, 2021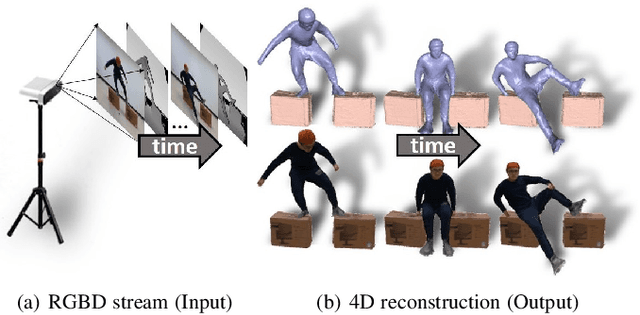
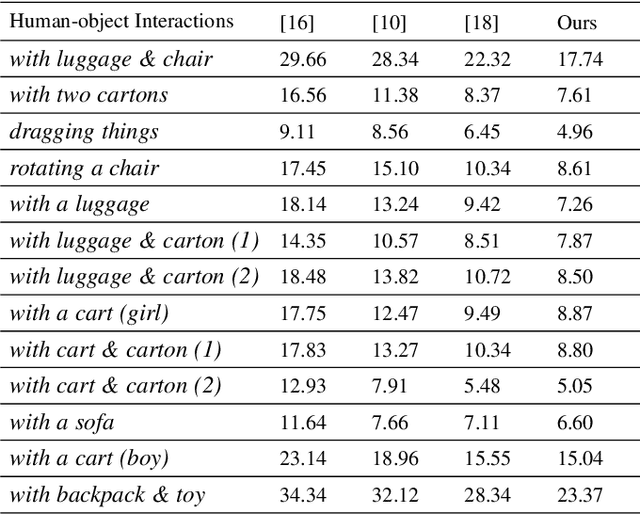
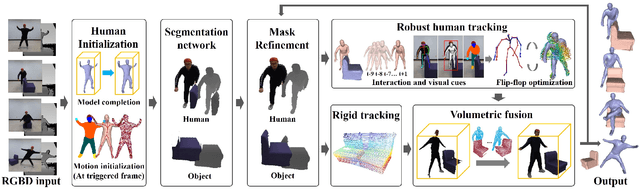

High-quality 4D reconstruction of human performance with complex interactions to various objects is essential in real-world scenarios, which enables numerous immersive VR/AR applications. However, recent advances still fail to provide reliable performance reconstruction, suffering from challenging interaction patterns and severe occlusions, especially for the monocular setting. To fill this gap, in this paper, we propose RobustFusion, a robust volumetric performance reconstruction system for human-object interaction scenarios using only a single RGBD sensor, which combines various data-driven visual and interaction cues to handle the complex interaction patterns and severe occlusions. We propose a semantic-aware scene decoupling scheme to model the occlusions explicitly, with a segmentation refinement and robust object tracking to prevent disentanglement uncertainty and maintain temporal consistency. We further introduce a robust performance capture scheme with the aid of various data-driven cues, which not only enables re-initialization ability, but also models the complex human-object interaction patterns in a data-driven manner. To this end, we introduce a spatial relation prior to prevent implausible intersections, as well as data-driven interaction cues to maintain natural motions, especially for those regions under severe human-object occlusions. We also adopt an adaptive fusion scheme for temporally coherent human-object reconstruction with occlusion analysis and human parsing cue. Extensive experiments demonstrate the effectiveness of our approach to achieve high-quality 4D human performance reconstruction under complex human-object interactions whilst still maintaining the lightweight monocular setting.