 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Meaningfulness of Nearest Neighbor Search in High-Dimensional Space
Oct 08, 2024Dense high dimensional vectors are becoming increasingly vital in fields such as computer vision, machine learning, and large language models (LLMs), serving as standard representations for multimodal data. Now the dimensionality of these vector can exceed several thousands easily. Despite the nearest neighbor search (NNS) over these dense high dimensional vectors have been widely used for retrieval augmented generation (RAG) and many other applications, the effectiveness of NNS in such a high-dimensional space remains uncertain, given the possible challenge caused by the "curse of dimensionality." To address above question, in this paper, we conduct extensive NNS studies with different distance functions, such as $L_1$ distance, $L_2$ distance and angular-distance, across diverse embedding datasets, of varied types, dimensionality and modality. Our aim is to investigate factors influencing the meaningfulness of NNS. Our experiments reveal that high-dimensional text embeddings exhibit increased resilience as dimensionality rises to higher levels when compared to random vectors. This resilience suggests that text embeddings are less affected to the "curse of dimensionality," resulting in more meaningful NNS outcomes for practical use. Additionally, the choice of distance function has minimal impact on the relevance of NNS. Our study shows the effectiveness of the embedding-based data representation method and can offer opportunity for further optimization of dense vector-related applications.
Efficient Registration of Forest Point Clouds by Global Matching of Relative Stem Positions
Dec 23, 2021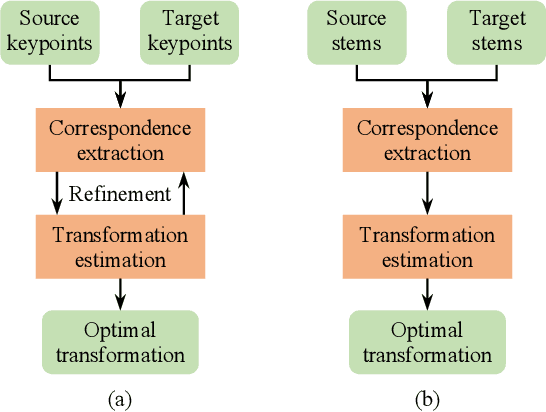

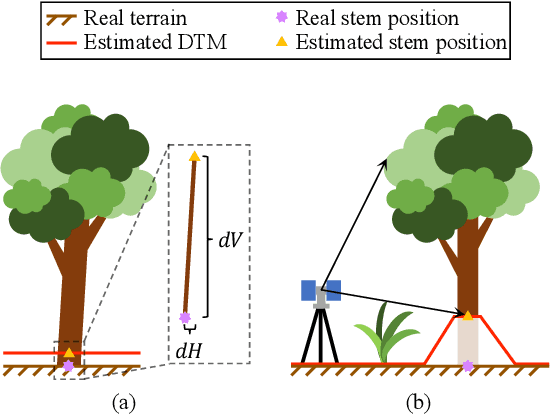
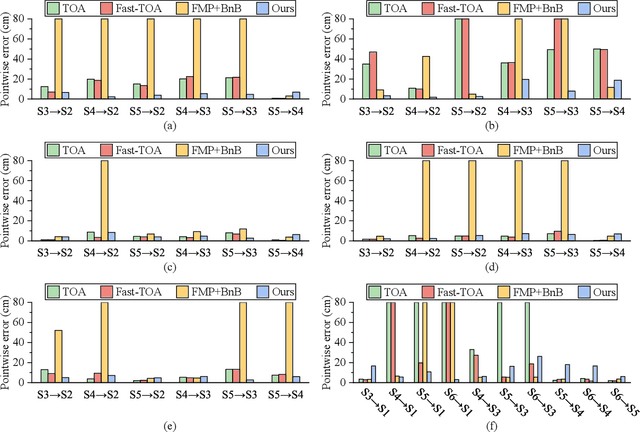
Registering point clouds of forest environments is an essential prerequisite for LiDAR applications in precision forestry. State-of-the-art methods for forest point cloud registration require the extraction of individual tree attributes, and they have an efficiency bottleneck when dealing with point clouds of real-world forests with dense trees. We propose an automatic, robust, and efficient method for the registration of forest point clouds. Our approach first locates tree stems from raw point clouds and then matches the stems based on their relative spatial relationship to determine the registration transformation. In contrast to existing methods, our algorithm requires no extra individual tree attributes and has linear complexity to the number of trees in the environment, allowing it to align point clouds of large forest environments. Extensive experiments have revealed that our method is superior to the state-of-the-art methods regarding registration accuracy and robustness, and it significantly outperforms existing techniques in terms of efficiency. Besides, we introduce a new benchmark dataset that complements the very few existing open datasets for the development and evaluation of registration methods for forest point clouds. The source code of our method and the dataset are available at https://github.com/zexinyang/AlignTree.