 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMerging Beyond: Streaming LLM Updates via Activation-Guided Rotations
Feb 03, 2026The escalating scale of Large Language Models (LLMs) necessitates efficient adaptation techniques. Model merging has gained prominence for its efficiency and controllability. However, existing merging techniques typically serve as post-hoc refinements or focus on mitigating task interference, often failing to capture the dynamic optimization benefits of supervised fine-tuning (SFT). In this work, we propose Streaming Merging, an innovative model updating paradigm that conceptualizes merging as an iterative optimization process. Central to this paradigm is \textbf{ARM} (\textbf{A}ctivation-guided \textbf{R}otation-aware \textbf{M}erging), a strategy designed to approximate gradient descent dynamics. By treating merging coefficients as learning rates and deriving rotation vectors from activation subspaces, ARM effectively steers parameter updates along data-driven trajectories. Unlike conventional linear interpolation, ARM aligns semantic subspaces to preserve the geometric structure of high-dimensional parameter evolution. Remarkably, ARM requires only early SFT checkpoints and, through iterative merging, surpasses the fully converged SFT model. Experimental results across model scales (1.7B to 14B) and diverse domains (e.g., math, code) demonstrate that ARM can transcend converged checkpoints. Extensive experiments show that ARM provides a scalable and lightweight framework for efficient model adaptation.
DreamOn: Diffusion Language Models For Code Infilling Beyond Fixed-size Canvas
Feb 01, 2026Diffusion Language Models (DLMs) present a compelling alternative to autoregressive models, offering flexible, any-order infilling without specialized prompting design. However, their practical utility is blocked by a critical limitation: the requirement of a fixed-length masked sequence for generation. This constraint severely degrades code infilling performance when the predefined mask size mismatches the ideal completion length. To address this, we propose DreamOn, a novel diffusion framework that enables dynamic, variable-length generation. DreamOn augments the diffusion process with two length control states, allowing the model to autonomously expand or contract the output length based solely on its own predictions. We integrate this mechanism into existing DLMs with minimal modifications to the training objective and no architectural changes. Built upon Dream-Coder-7B and DiffuCoder-7B, DreamOn achieves infilling performance on par with state-of-the-art autoregressive models on HumanEval-Infilling and SantaCoder-FIM and matches oracle performance achieved with ground-truth length. Our work removes a fundamental barrier to the practical deployment of DLMs, significantly advancing their flexibility and applicability for variable-length generation. Our code is available at https://github.com/DreamLM/DreamOn.
Beyond Accuracy: Evaluating Grounded Visual Evidence in Thinking with Images
Jan 14, 2026Despite the remarkable progress of Vision-Language Models (VLMs) in adopting "Thinking-with-Images" capabilities, accurately evaluating the authenticity of their reasoning process remains a critical challenge. Existing benchmarks mainly rely on outcome-oriented accuracy, lacking the capability to assess whether models can accurately leverage fine-grained visual cues for multi-step reasoning. To address these limitations, we propose ViEBench, a process-verifiable benchmark designed to evaluate faithful visual reasoning. Comprising 200 multi-scenario high-resolution images with expert-annotated visual evidence, ViEBench uniquely categorizes tasks by difficulty into perception and reasoning dimensions, where reasoning tasks require utilizing localized visual details with prior knowledge. To establish comprehensive evaluation criteria, we introduce a dual-axis matrix that provides fine-grained metrics through four diagnostic quadrants, enabling transparent diagnosis of model behavior across varying task complexities. Our experiments yield several interesting observations: (1) VLMs can sometimes produce correct final answers despite grounding on irrelevant regions, and (2) they may successfully locate the correct evidence but still fail to utilize it to reach accurate conclusions. Our findings demonstrate that ViEBench can serve as a more explainable and practical benchmark for comprehensively evaluating the effectiveness agentic VLMs. The codes will be released at: https://github.com/Xuchen-Li/ViEBench.
Dream-VL & Dream-VLA: Open Vision-Language and Vision-Language-Action Models with Diffusion Language Model Backbone
Dec 27, 2025While autoregressive Large Vision-Language Models (VLMs) have achieved remarkable success, their sequential generation often limits their efficacy in complex visual planning and dynamic robotic control. In this work, we investigate the potential of constructing Vision-Language Models upon diffusion-based large language models (dLLMs) to overcome these limitations. We introduce Dream-VL, an open diffusion-based VLM (dVLM) that achieves state-of-the-art performance among previous dVLMs. Dream-VL is comparable to top-tier AR-based VLMs trained on open data on various benchmarks but exhibits superior potential when applied to visual planning tasks. Building upon Dream-VL, we introduce Dream-VLA, a dLLM-based Vision-Language-Action model (dVLA) developed through continuous pre-training on open robotic datasets. We demonstrate that the natively bidirectional nature of this diffusion backbone serves as a superior foundation for VLA tasks, inherently suited for action chunking and parallel generation, leading to significantly faster convergence in downstream fine-tuning. Dream-VLA achieves top-tier performance of 97.2% average success rate on LIBERO, 71.4% overall average on SimplerEnv-Bridge, and 60.5% overall average on SimplerEnv-Fractal, surpassing leading models such as $π_0$ and GR00T-N1. We also validate that dVLMs surpass AR baselines on downstream tasks across different training objectives. We release both Dream-VL and Dream-VLA to facilitate further research in the community.
Look Less, Reason More: Rollout-Guided Adaptive Pixel-Space Reasoning
Oct 02, 2025Vision-Language Models (VLMs) excel at many multimodal tasks, yet they frequently struggle with tasks requiring precise understanding and handling of fine-grained visual elements. This is mainly due to information loss during image encoding or insufficient attention to critical regions. Recent work has shown promise by incorporating pixel-level visual information into the reasoning process, enabling VLMs to access high-resolution visual details during their thought process. However, this pixel-level information is often overused, leading to inefficiency and distraction from irrelevant visual details. To address these challenges, we propose the first framework for adaptive pixel reasoning that dynamically determines necessary pixel-level operations based on the input query. Specifically, we first apply operation-aware supervised fine-tuning to establish baseline competence in textual reasoning and visual operations, then design a novel rollout-guided reinforcement learning framework relying on feedback of the model's own responses, which enables the VLM to determine when pixel operations should be invoked based on query difficulty. Experiments on extensive multimodal reasoning benchmarks show that our model achieves superior performance while significantly reducing unnecessary visual operations. Impressively, our model achieves 73.4\% accuracy on HR-Bench 4K while maintaining a tool usage ratio of only 20.1\%, improving accuracy and simultaneously reducing tool usage by 66.5\% compared to the previous methods.
Pointing to a Llama and Call it a Camel: On the Sycophancy of Multimodal Large Language Models
Sep 19, 2025



Multimodal large language models (MLLMs) have demonstrated extraordinary capabilities in conducting conversations based on image inputs. However, we observe that MLLMs exhibit a pronounced form of visual sycophantic behavior. While similar behavior has also been noted in text-based large language models (LLMs), it becomes significantly more prominent when MLLMs process image inputs. We refer to this phenomenon as the "sycophantic modality gap." To better understand this issue, we further analyze the factors that contribute to the exacerbation of this gap. To mitigate the visual sycophantic behavior, we first experiment with naive supervised fine-tuning to help the MLLM resist misleading instructions from the user. However, we find that this approach also makes the MLLM overly resistant to corrective instructions (i.e., stubborn even if it is wrong). To alleviate this trade-off, we propose Sycophantic Reflective Tuning (SRT), which enables the MLLM to engage in reflective reasoning, allowing it to determine whether a user's instruction is misleading or corrective before drawing a conclusion. After applying SRT, we observe a significant reduction in sycophantic behavior toward misleading instructions, without resulting in excessive stubbornness when receiving corrective instructions.
ExeSQL: Self-Taught Text-to-SQL Models with Execution-Driven Bootstrapping for SQL Dialects
May 22, 2025Recent text-to-SQL models have achieved strong performance, but their effectiveness remains largely confined to SQLite due to dataset limitations. However, real-world applications require SQL generation across multiple dialects with varying syntax and specialized features, which remains a challenge for current models. The main obstacle in building a dialect-aware model lies in acquiring high-quality dialect-specific data. Data generated purely through static prompting - without validating SQLs via execution - tends to be noisy and unreliable. Moreover, the lack of real execution environments in the training loop prevents models from grounding their predictions in executable semantics, limiting generalization despite surface-level improvements from data filtering. This work introduces ExeSQL, a text-to-SQL framework with execution-driven, agentic bootstrapping. The method consists of iterative query generation, execution-based filtering (e.g., rejection sampling), and preference-based training, enabling the model to adapt to new SQL dialects through verifiable, feedback-guided learning. Experiments show that ExeSQL bridges the dialect gap in text-to-SQL, achieving average improvements of 15.2%, 10.38%, and 4.49% over GPT-4o on PostgreSQL, MySQL, and Oracle, respectively, across multiple datasets of varying difficulty.
TreeSynth: Synthesizing Diverse Data from Scratch via Tree-Guided Subspace Partitioning
Mar 21, 2025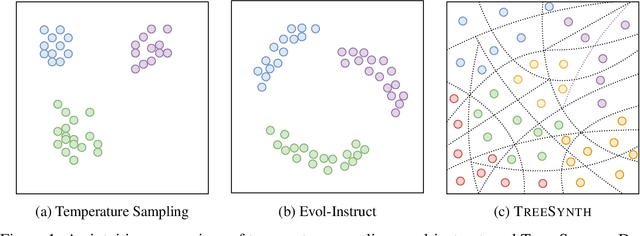
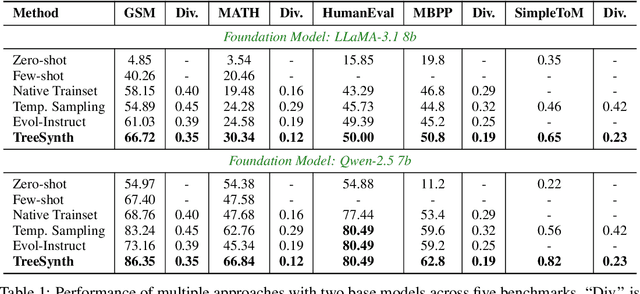
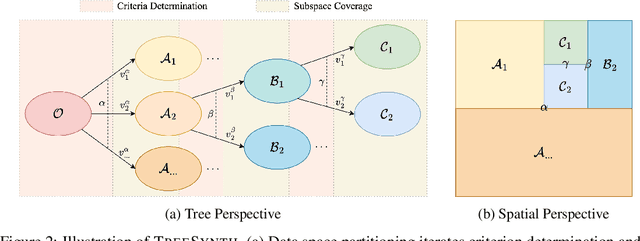
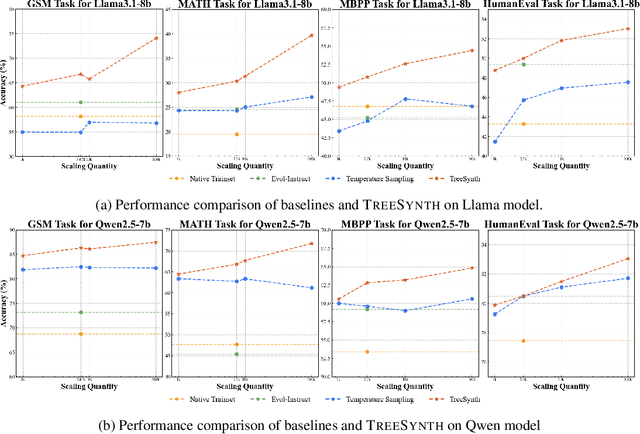
Model customization requires high-quality and diverse datasets, but acquiring such data remains challenging and costly. Although large language models (LLMs) can synthesize training data, current approaches are constrained by limited seed data, model bias and insufficient control over the generation process, resulting in limited diversity and biased distribution with the increase of data scales. To tackle this challenge, we present TreeSynth, a tree-guided subspace-based data synthesis framework that recursively partitions the entire data space into hierar-chical subspaces, enabling comprehensive and diverse scaling of data synthesis. Briefly, given a task-specific description, we construct a data space partitioning tree by iteratively executing criteria determination and subspace coverage steps. This hierarchically divides the whole space (i.e., root node) into mutually exclusive and complementary atomic subspaces (i.e., leaf nodes). By collecting synthesized data according to the attributes of each leaf node, we obtain a diverse dataset that fully covers the data space. Empirically, our extensive experiments demonstrate that TreeSynth surpasses both human-designed datasets and the state-of-the-art data synthesis baselines, achieving maximum improvements of 45.2% in data diversity and 17.6% in downstream task performance across various models and tasks. Hopefully, TreeSynth provides a scalable solution to synthesize diverse and comprehensive datasets from scratch without human intervention.
Implicit Search via Discrete Diffusion: A Study on Chess
Feb 27, 2025In the post-AlphaGo era, there has been a renewed interest in search techniques such as Monte Carlo Tree Search (MCTS), particularly in their application to Large Language Models (LLMs). This renewed attention is driven by the recognition that current next-token prediction models often lack the ability for long-term planning. Is it possible to instill search-like abilities within the models to enhance their planning abilities without relying on explicit search? We propose DiffuSearch , a model that does \textit{implicit search} by looking into the future world via discrete diffusion modeling. We instantiate DiffuSearch on a classical board game, Chess, where explicit search is known to be essential. Through extensive controlled experiments, we show DiffuSearch outperforms both the searchless and explicit search-enhanced policies. Specifically, DiffuSearch outperforms the one-step policy by 19.2% and the MCTS-enhanced policy by 14% on action accuracy. Furthermore, DiffuSearch demonstrates a notable 30% enhancement in puzzle-solving abilities compared to explicit search-based policies, along with a significant 540 Elo increase in game-playing strength assessment. These results indicate that implicit search via discrete diffusion is a viable alternative to explicit search over a one-step policy. All codes are publicly available at \href{https://github.com/HKUNLP/DiffuSearch}{https://github.com/HKUNLP/DiffuSearch}.
Contrast Similarity-Aware Dual-Pathway Mamba for Multivariate Time Series Node Classification
Nov 19, 2024Multivariate time series (MTS) data is generated through multiple sensors across various domains such as engineering application, health monitoring, and the internet of things, characterized by its temporal changes and high dimensional characteristics. Over the past few years, many studies have explored the long-range dependencies and similarities in MTS. However, long-range dependencies are difficult to model due to their temporal changes and high dimensionality makes it difficult to obtain similarities effectively and efficiently. Thus, to address these issues, we propose contrast similarity-aware dual-pathway Mamba for MTS node classification (CS-DPMamba). Firstly, to obtain the dynamic similarity of each sample, we initially use temporal contrast learning module to acquire MTS representations. And then we construct a similarity matrix between MTS representations using Fast Dynamic Time Warping (FastDTW). Secondly, we apply the DPMamba to consider the bidirectional nature of MTS, allowing us to better capture long-range and short-range dependencies within the data. Finally, we utilize the Kolmogorov-Arnold Network enhanced Graph Isomorphism Network to complete the information interaction in the matrix and MTS node classification task. By comprehensively considering the long-range dependencies and dynamic similarity features, we achieved precise MTS node classification. We conducted experiments on multiple University of East Anglia (UEA) MTS datasets, which encompass diverse application scenarios. Our results demonstrate the superiority of our method through both supervised and semi-supervised experiments on the MTS classification task.