 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTreeSynth: Synthesizing Diverse Data from Scratch via Tree-Guided Subspace Partitioning
Paper and Code
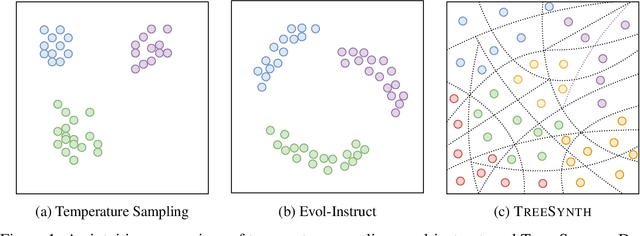
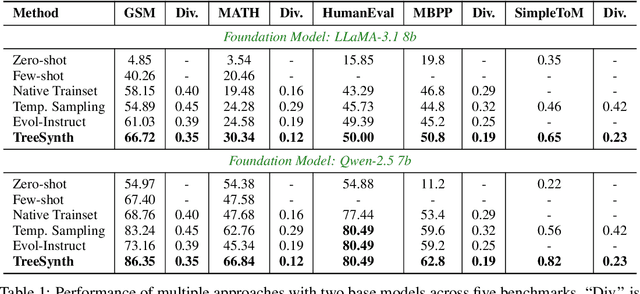
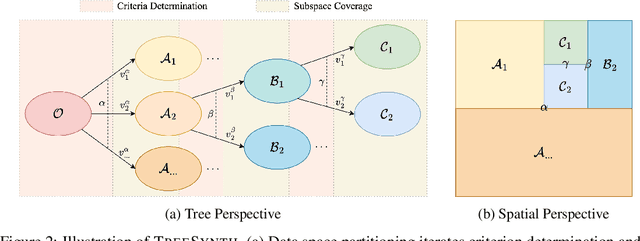
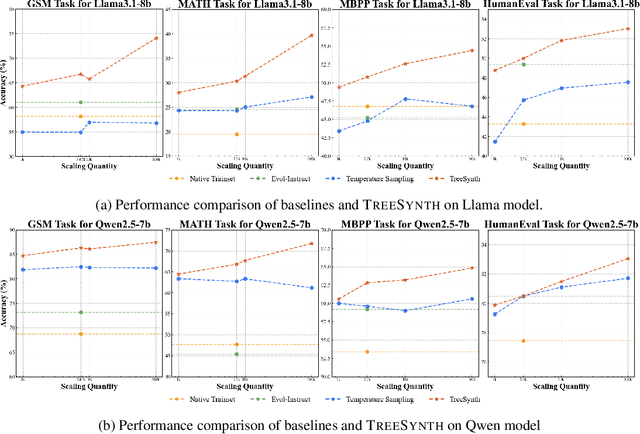
Model customization requires high-quality and diverse datasets, but acquiring such data remains challenging and costly. Although large language models (LLMs) can synthesize training data, current approaches are constrained by limited seed data, model bias and insufficient control over the generation process, resulting in limited diversity and biased distribution with the increase of data scales. To tackle this challenge, we present TreeSynth, a tree-guided subspace-based data synthesis framework that recursively partitions the entire data space into hierar-chical subspaces, enabling comprehensive and diverse scaling of data synthesis. Briefly, given a task-specific description, we construct a data space partitioning tree by iteratively executing criteria determination and subspace coverage steps. This hierarchically divides the whole space (i.e., root node) into mutually exclusive and complementary atomic subspaces (i.e., leaf nodes). By collecting synthesized data according to the attributes of each leaf node, we obtain a diverse dataset that fully covers the data space. Empirically, our extensive experiments demonstrate that TreeSynth surpasses both human-designed datasets and the state-of-the-art data synthesis baselines, achieving maximum improvements of 45.2% in data diversity and 17.6% in downstream task performance across various models and tasks. Hopefully, TreeSynth provides a scalable solution to synthesize diverse and comprehensive datasets from scratch without human intervention.