 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTreeSynth: Synthesizing Diverse Data from Scratch via Tree-Guided Subspace Partitioning
Mar 21, 2025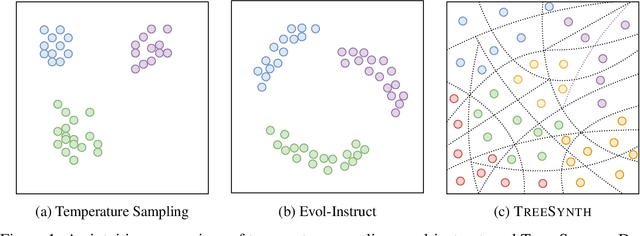
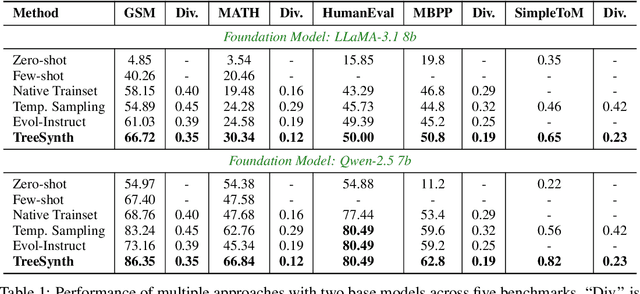
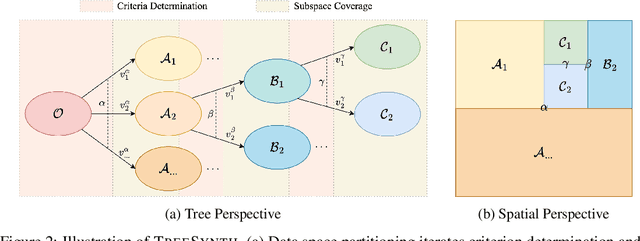
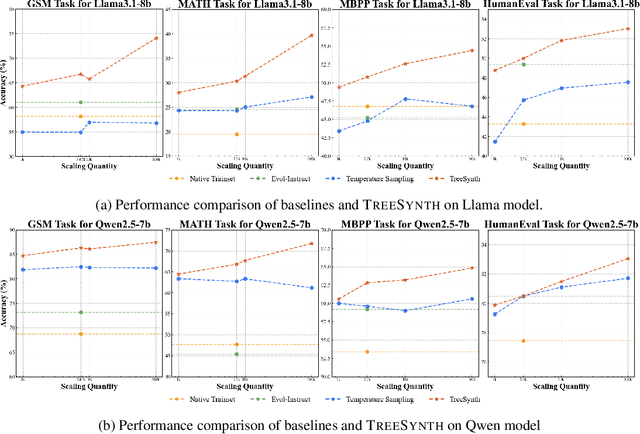
Model customization requires high-quality and diverse datasets, but acquiring such data remains challenging and costly. Although large language models (LLMs) can synthesize training data, current approaches are constrained by limited seed data, model bias and insufficient control over the generation process, resulting in limited diversity and biased distribution with the increase of data scales. To tackle this challenge, we present TreeSynth, a tree-guided subspace-based data synthesis framework that recursively partitions the entire data space into hierar-chical subspaces, enabling comprehensive and diverse scaling of data synthesis. Briefly, given a task-specific description, we construct a data space partitioning tree by iteratively executing criteria determination and subspace coverage steps. This hierarchically divides the whole space (i.e., root node) into mutually exclusive and complementary atomic subspaces (i.e., leaf nodes). By collecting synthesized data according to the attributes of each leaf node, we obtain a diverse dataset that fully covers the data space. Empirically, our extensive experiments demonstrate that TreeSynth surpasses both human-designed datasets and the state-of-the-art data synthesis baselines, achieving maximum improvements of 45.2% in data diversity and 17.6% in downstream task performance across various models and tasks. Hopefully, TreeSynth provides a scalable solution to synthesize diverse and comprehensive datasets from scratch without human intervention.
ProReason: Multi-Modal Proactive Reasoning with Decoupled Eyesight and Wisdom
Oct 18, 2024
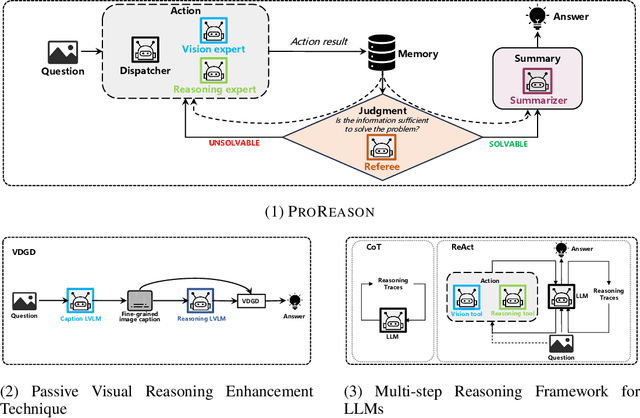
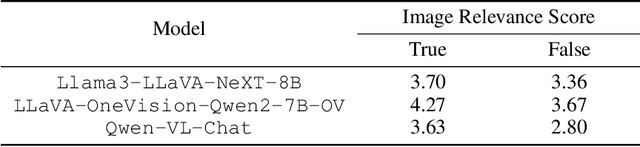
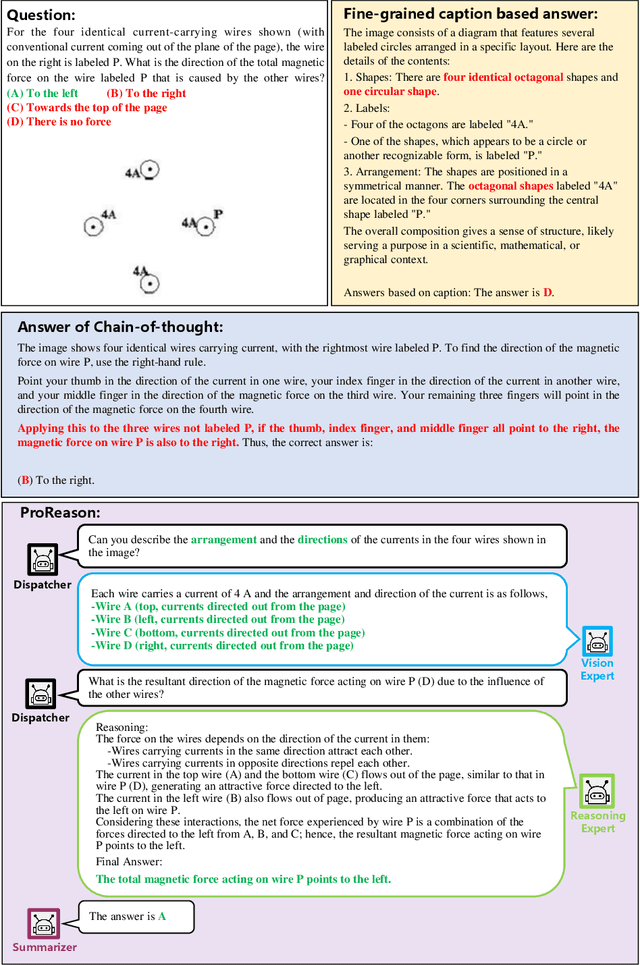
Large vision-language models (LVLMs) have witnessed significant progress on visual understanding tasks. However, they often prioritize language knowledge over image information on visual reasoning tasks, incurring performance degradation. To tackle this issue, we first identify the drawbacks of existing solutions (i.e., insufficient and irrelevant visual descriptions, and limited multi-modal capacities). We then decompose visual reasoning process into two stages: visual perception (i.e., eyesight) and textual reasoning (i.e., wisdom), and introduce a novel visual reasoning framework named ProReason. This framework features multi-run proactive perception and decoupled vision-reasoning capabilities. Briefly, given a multi-modal question, ProReason iterates proactive information collection and reasoning until the answer can be concluded with necessary and sufficient visual descriptions. Notably, the disassociation of capabilities allows seamless integration of existing large language models (LLMs) to compensate for the reasoning deficits of LVLMs. Our extensive experiments demonstrate that ProReason outperforms both existing multi-step reasoning frameworks and passive peer methods on a wide range of benchmarks for both open-source and closed-source models. In addition, with the assistance of LLMs, ProReason achieves a performance improvement of up to 15% on MMMU benchmark. Our insights into existing solutions and the decoupled perspective for feasible integration of LLMs illuminate future research on visual reasoning techniques, especially LLM-assisted ones.
MoS: Unleashing Parameter Efficiency of Low-Rank Adaptation with Mixture of Shards
Oct 01, 2024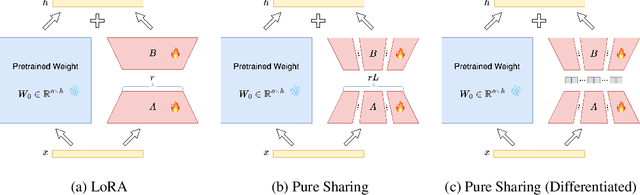

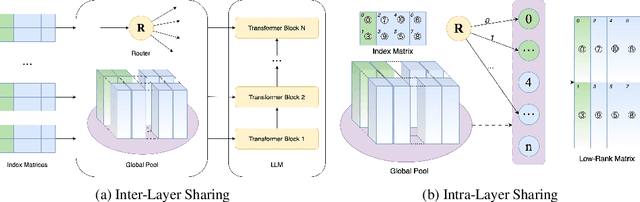
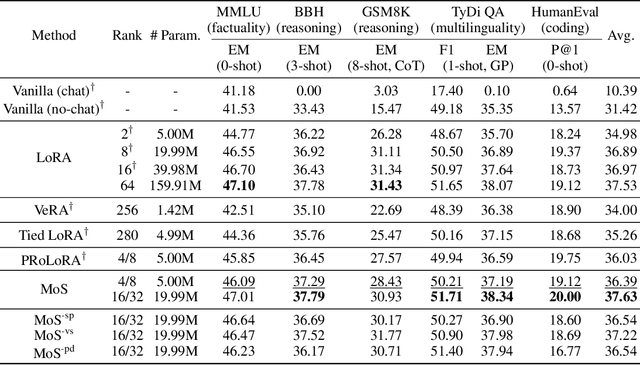
The rapid scaling of large language models necessitates more lightweight finetuning methods to reduce the explosive GPU memory overhead when numerous customized models are served simultaneously. Targeting more parameter-efficient low-rank adaptation (LoRA), parameter sharing presents a promising solution. Empirically, our research into high-level sharing principles highlights the indispensable role of differentiation in reversing the detrimental effects of pure sharing. Guided by this finding, we propose Mixture of Shards (MoS), incorporating both inter-layer and intra-layer sharing schemes, and integrating four nearly cost-free differentiation strategies, namely subset selection, pair dissociation, vector sharding, and shard privatization. Briefly, it selects a designated number of shards from global pools with a Mixture-of-Experts (MoE)-like routing mechanism before sequentially concatenating them to low-rank matrices. Hence, it retains all the advantages of LoRA while offering enhanced parameter efficiency, and effectively circumvents the drawbacks of peer parameter-sharing methods. Our empirical experiments demonstrate approximately 8x parameter savings in a standard LoRA setting. The ablation study confirms the significance of each component. Our insights into parameter sharing and MoS method may illuminate future developments of more parameter-efficient finetuning methods.