 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForewarned is Forearmed: Leveraging LLMs for Data Synthesis through Failure-Inducing Exploration
Paper and Code
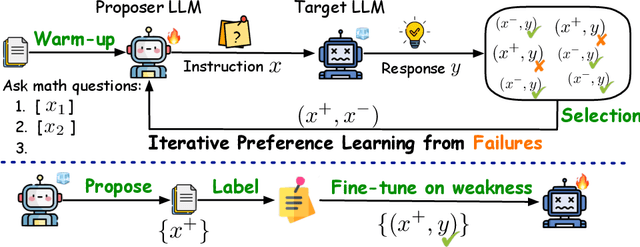
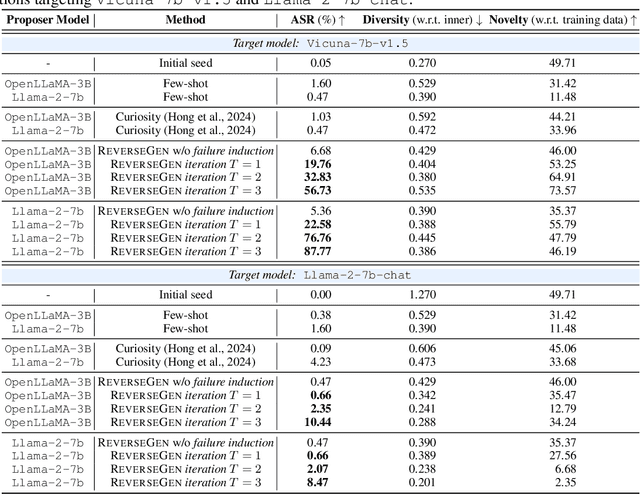

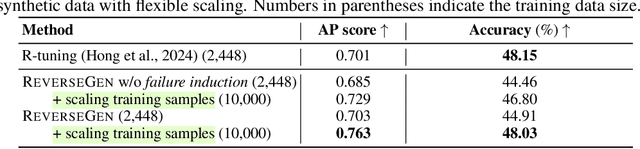
Large language models (LLMs) have significantly benefited from training on diverse, high-quality task-specific data, leading to impressive performance across a range of downstream applications. Current methods often rely on human-annotated data or predefined task templates to direct powerful LLMs in synthesizing task-relevant data for effective model training. However, this dependence on manually designed components may constrain the scope of generated data, potentially overlooking critical edge cases or novel scenarios that could challenge the model. In this paper, we present a novel approach, ReverseGen, designed to automatically generate effective training samples that expose the weaknesses of LLMs. Specifically, we introduce a dedicated proposer trained to produce queries that lead target models to generate unsatisfactory responses. These failure-inducing queries are then used to construct training data, helping to address the models' shortcomings and improve overall performance. Our approach is flexible and can be applied to models of various scales (3B, 7B, and 8B). We evaluate ReverseGen on three key applications (safety, honesty, and math), demonstrating that our generated data is both highly effective and diverse. Models fine-tuned with ReverseGen-generated data consistently outperform those trained on human-annotated or general model-generated data, offering a new perspective on data synthesis for task-specific LLM enhancement.