 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynaAct: Large Language Model Reasoning with Dynamic Action Spaces
Nov 11, 2025In modern sequential decision-making systems, the construction of an optimal candidate action space is critical to efficient inference. However, existing approaches either rely on manually defined action spaces that lack scalability or utilize unstructured spaces that render exhaustive search computationally prohibitive. In this paper, we propose a novel framework named \textsc{DynaAct} for automatically constructing a compact action space to enhance sequential reasoning in complex problem-solving scenarios. Our method first estimates a proxy for the complete action space by extracting general sketches observed in a corpus covering diverse complex reasoning problems using large language models. We then formulate a submodular function that jointly evaluates candidate actions based on their utility to the current state and their diversity, and employ a greedy algorithm to select an optimal candidate set. Extensive experiments on six diverse standard benchmarks demonstrate that our approach significantly improves overall performance, while maintaining efficient inference without introducing substantial latency. The implementation is available at https://github.com/zhaoxlpku/DynaAct.
Scaling Reasoning without Attention
May 28, 2025Large language models (LLMs) have made significant advances in complex reasoning tasks, yet they remain bottlenecked by two core challenges: architectural inefficiency due to reliance on Transformers, and a lack of structured fine-tuning for high-difficulty domains. We introduce \ourmodel, an attention-free language model that addresses both issues through architectural and data-centric innovations. Built on the state space dual (SSD) layers of Mamba-2, our model eliminates the need for self-attention and key-value caching, enabling fixed-memory, constant-time inference. To train it for complex reasoning, we propose a two-phase curriculum fine-tuning strategy based on the \textsc{PromptCoT} synthesis paradigm, which generates pedagogically structured problems via abstract concept selection and rationale-guided generation. On benchmark evaluations, \ourmodel-7B outperforms strong Transformer and hybrid models of comparable scale, and even surpasses the much larger Gemma3-27B by 2.6\% on AIME 24, 0.6\% on AIME 25, and 3.0\% on Livecodebench. These results highlight the potential of state space models as efficient and scalable alternatives to attention-based architectures for high-capacity reasoning.
PromptCoT: Synthesizing Olympiad-level Problems for Mathematical Reasoning in Large Language Models
Mar 04, 2025



The ability of large language models to solve complex mathematical problems has progressed significantly, particularly for tasks requiring advanced reasoning. However, the scarcity of sufficiently challenging problems, particularly at the Olympiad level, hinders further advancements. In this work, we introduce PromptCoT, a novel approach for automatically generating high-quality Olympiad-level math problems. The proposed method synthesizes complex problems based on mathematical concepts and the rationale behind problem construction, emulating the thought processes of experienced problem designers. We provide a theoretical analysis demonstrating that an optimal rationale should maximize both the likelihood of rationale generation given the associated concepts and the likelihood of problem generation conditioned on both the rationale and the concepts. Our method is evaluated on standard benchmarks including GSM8K, MATH-500, and AIME2024, where it consistently outperforms existing problem generation methods. Furthermore, we demonstrate that PromptCoT exhibits superior data scalability, consistently maintaining high performance as the dataset size increases, outperforming the baselines. The implementation is available at https://github.com/zhaoxlpku/PromptCoT.
Forewarned is Forearmed: Leveraging LLMs for Data Synthesis through Failure-Inducing Exploration
Oct 22, 2024
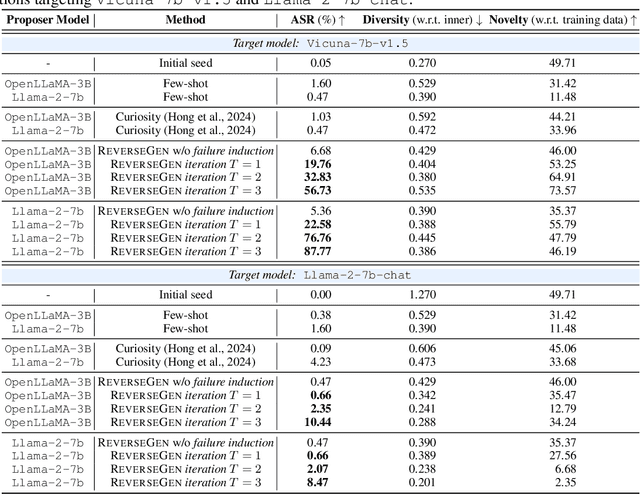

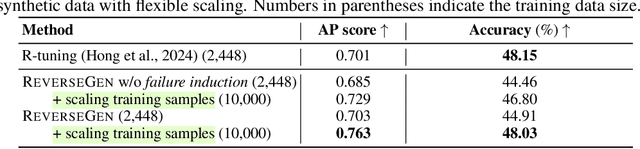
Large language models (LLMs) have significantly benefited from training on diverse, high-quality task-specific data, leading to impressive performance across a range of downstream applications. Current methods often rely on human-annotated data or predefined task templates to direct powerful LLMs in synthesizing task-relevant data for effective model training. However, this dependence on manually designed components may constrain the scope of generated data, potentially overlooking critical edge cases or novel scenarios that could challenge the model. In this paper, we present a novel approach, ReverseGen, designed to automatically generate effective training samples that expose the weaknesses of LLMs. Specifically, we introduce a dedicated proposer trained to produce queries that lead target models to generate unsatisfactory responses. These failure-inducing queries are then used to construct training data, helping to address the models' shortcomings and improve overall performance. Our approach is flexible and can be applied to models of various scales (3B, 7B, and 8B). We evaluate ReverseGen on three key applications (safety, honesty, and math), demonstrating that our generated data is both highly effective and diverse. Models fine-tuned with ReverseGen-generated data consistently outperform those trained on human-annotated or general model-generated data, offering a new perspective on data synthesis for task-specific LLM enhancement.
SubgoalXL: Subgoal-based Expert Learning for Theorem Proving
Aug 20, 2024



Formal theorem proving, a field at the intersection of mathematics and computer science, has seen renewed interest with advancements in large language models (LLMs). This paper introduces SubgoalXL, a novel approach that synergizes subgoal-based proofs with expert learning to enhance LLMs' capabilities in formal theorem proving within the Isabelle environment. SubgoalXL addresses two critical challenges: the scarcity of specialized mathematics and theorem-proving data, and the need for improved multi-step reasoning abilities in LLMs. By optimizing data efficiency and employing subgoal-level supervision, SubgoalXL extracts richer information from limited human-generated proofs. The framework integrates subgoal-oriented proof strategies with an expert learning system, iteratively refining formal statement, proof, and subgoal generators. Leveraging the Isabelle environment's advantages in subgoal-based proofs, SubgoalXL achieves a new state-of-the-art performance of 56.1\% in Isabelle on the standard miniF2F dataset, marking an absolute improvement of 4.9\%. Notably, SubgoalXL successfully solves 41 AMC12, 9 AIME, and 3 IMO problems from miniF2F. These results underscore the effectiveness of maximizing limited data utility and employing targeted guidance for complex reasoning in formal theorem proving, contributing to the ongoing advancement of AI reasoning capabilities. The implementation is available at \url{https://github.com/zhaoxlpku/SubgoalXL}.
GSM-Plus: A Comprehensive Benchmark for Evaluating the Robustness of LLMs as Mathematical Problem Solvers
Feb 29, 2024



Large language models (LLMs) have achieved impressive performance across various mathematical reasoning benchmarks. However, there are increasing debates regarding whether these models truly understand and apply mathematical knowledge or merely rely on shortcuts for mathematical reasoning. One essential and frequently occurring evidence is that when the math questions are slightly changed, LLMs can behave incorrectly. This motivates us to evaluate the robustness of LLMs' math reasoning capability by testing a wide range of question variations. We introduce the adversarial grade school math (\datasetname) dataset, an extension of GSM8K augmented with various mathematical perturbations. Our experiments on 25 LLMs and 4 prompting techniques show that while LLMs exhibit different levels of math reasoning abilities, their performances are far from robust. In particular, even for problems that have been solved in GSM8K, LLMs can make mistakes when new statements are added or the question targets are altered. We also explore whether more robust performance can be achieved by composing existing prompting methods, in which we try an iterative method that generates and verifies each intermediate thought based on its reasoning goal and calculation result. Code and data are available at \url{https://github.com/qtli/GSM-Plus}.
BBA: Bi-Modal Behavioral Alignment for Reasoning with Large Vision-Language Models
Feb 21, 2024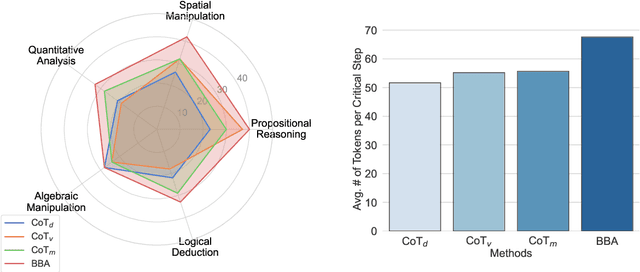
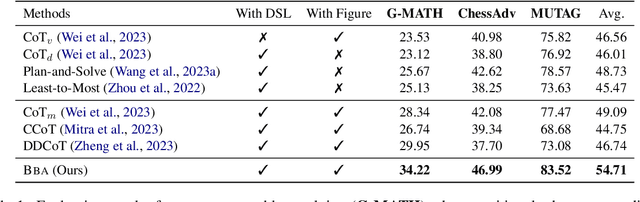
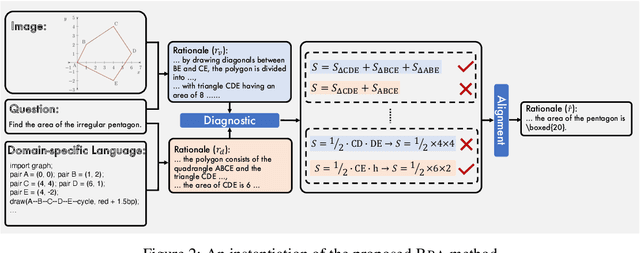
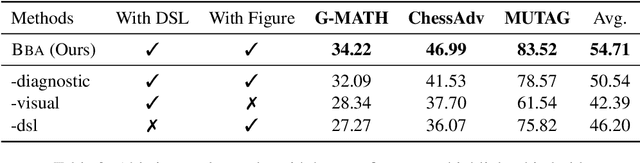
Multimodal reasoning stands as a pivotal capability for large vision-language models (LVLMs). The integration with Domain-Specific Languages (DSL), offering precise visual representations, equips these models with the opportunity to execute more accurate reasoning in complex and professional domains. However, the vanilla Chain-of-Thought (CoT) prompting method faces challenges in effectively leveraging the unique strengths of visual and DSL representations, primarily due to their differing reasoning mechanisms. Additionally, it often falls short in addressing critical steps in multi-step reasoning tasks. To mitigate these challenges, we introduce the \underline{B}i-Modal \underline{B}ehavioral \underline{A}lignment (BBA) prompting method, designed to maximize the potential of DSL in augmenting complex multi-modal reasoning tasks. This method initiates by guiding LVLMs to create separate reasoning chains for visual and DSL representations. Subsequently, it aligns these chains by addressing any inconsistencies, thus achieving a cohesive integration of behaviors from different modalities. Our experiments demonstrate that BBA substantially improves the performance of GPT-4V(ision) on geometry problem solving ($28.34\% \to 34.22\%$), chess positional advantage prediction ($42.08\% \to 46.99\%$) and molecular property prediction ($77.47\% \to 83.52\%$).
SEGO: Sequential Subgoal Optimization for Mathematical Problem-Solving
Oct 19, 2023Large Language Models (LLMs) have driven substantial progress in artificial intelligence in recent years, exhibiting impressive capabilities across a wide range of tasks, including mathematical problem-solving. Inspired by the success of subgoal-based methods, we propose a novel framework called \textbf{SE}quential sub\textbf{G}oal \textbf{O}ptimization (SEGO) to enhance LLMs' ability to solve mathematical problems. By establishing a connection between the subgoal breakdown process and the probability of solving problems, SEGO aims to identify better subgoals with theoretical guarantees. Addressing the challenge of identifying suitable subgoals in a large solution space, our framework generates problem-specific subgoals and adjusts them according to carefully designed criteria. Incorporating these optimized subgoals into the policy model training leads to significant improvements in problem-solving performance. We validate SEGO's efficacy through experiments on two benchmarks, GSM8K and MATH, where our approach outperforms existing methods, highlighting the potential of SEGO in AI-driven mathematical problem-solving. Data and code associated with this paper will be available at https://github.com/zhaoxlpku/SEGO
VSTAR: A Video-grounded Dialogue Dataset for Situated Semantic Understanding with Scene and Topic Transitions
May 30, 2023


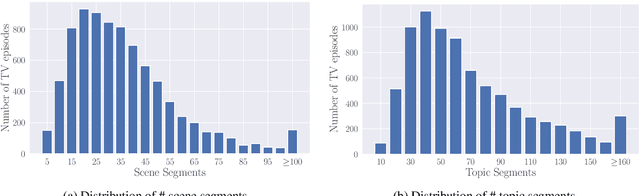
Video-grounded dialogue understanding is a challenging problem that requires machine to perceive, parse and reason over situated semantics extracted from weakly aligned video and dialogues. Most existing benchmarks treat both modalities the same as a frame-independent visual understanding task, while neglecting the intrinsic attributes in multimodal dialogues, such as scene and topic transitions. In this paper, we present Video-grounded Scene&Topic AwaRe dialogue (VSTAR) dataset, a large scale video-grounded dialogue understanding dataset based on 395 TV series. Based on VSTAR, we propose two benchmarks for video-grounded dialogue understanding: scene segmentation and topic segmentation, and one benchmark for video-grounded dialogue generation. Comprehensive experiments are performed on these benchmarks to demonstrate the importance of multimodal information and segments in video-grounded dialogue understanding and generation.
Decomposing the Enigma: Subgoal-based Demonstration Learning for Formal Theorem Proving
May 25, 2023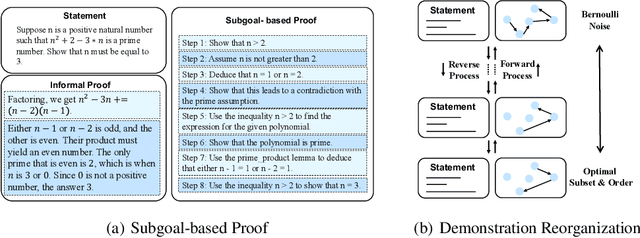



Large language models~(LLMs) present an intriguing avenue of exploration in the domain of formal theorem proving. Nonetheless, the full utilization of these models, particularly in terms of demonstration formatting and organization, remains an underexplored area. In an endeavor to enhance the efficacy of LLMs, we introduce a subgoal-based demonstration learning framework, consisting of two primary elements: Firstly, drawing upon the insights of subgoal learning from the domains of reinforcement learning and robotics, we propose the construction of distinct subgoals for each demonstration example and refine these subgoals in accordance with the pertinent theories of subgoal learning. Secondly, we build upon recent advances in diffusion models to predict the optimal organization, simultaneously addressing two intricate issues that persist within the domain of demonstration organization: subset selection and order determination. Through the integration of subgoal-based learning methodologies, we have successfully increased the prevailing proof accuracy from 38.9\% to 44.3\% on the miniF2F benchmark. Furthermore, the adoption of diffusion models for demonstration organization can lead to an additional enhancement in accuracy to 45.5\%, or a $5\times$ improvement in sampling efficiency compared with the long-standing state-of-the-art method. Our code is available at \url{https://github.com/HKUNLP/subgoal-theorem-prover}.