 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Deep Learning for Structural Brain Imaging: A Unified Framework
Feb 23, 2025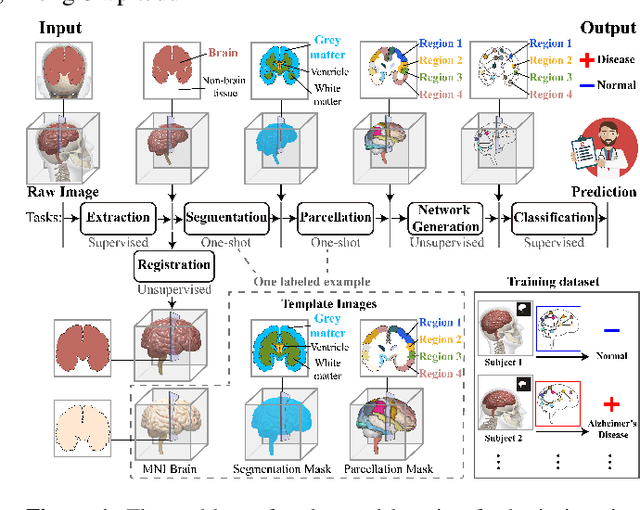
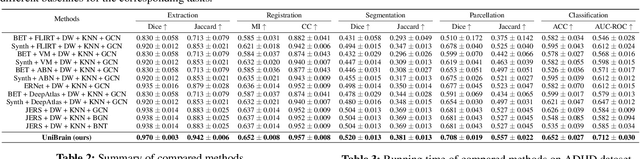
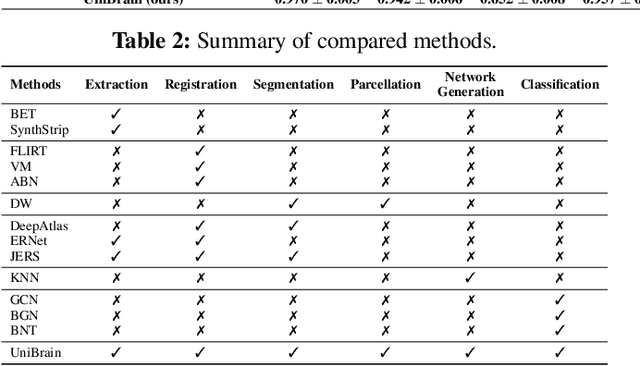
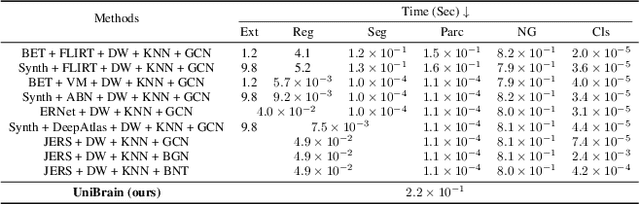
Brain imaging analysis is fundamental in neuroscience, providing valuable insights into brain structure and function. Traditional workflows follow a sequential pipeline-brain extraction, registration, segmentation, parcellation, network generation, and classification-treating each step as an independent task. These methods rely heavily on task-specific training data and expert intervention to correct intermediate errors, making them particularly burdensome for high-dimensional neuroimaging data, where annotations and quality control are costly and time-consuming. We introduce UniBrain, a unified end-to-end framework that integrates all processing steps into a single optimization process, allowing tasks to interact and refine each other. Unlike traditional approaches that require extensive task-specific annotations, UniBrain operates with minimal supervision, leveraging only low-cost labels (i.e., classification and extraction) and a single labeled atlas. By jointly optimizing extraction, registration, segmentation, parcellation, network generation, and classification, UniBrain enhances both accuracy and computational efficiency while significantly reducing annotation effort. Experimental results demonstrate its superiority over existing methods across multiple tasks, offering a more scalable and reliable solution for neuroimaging analysis. Our code and data can be found at https://github.com/Anonymous7852/UniBrain
Multi-State Brain Network Discovery
Nov 04, 2023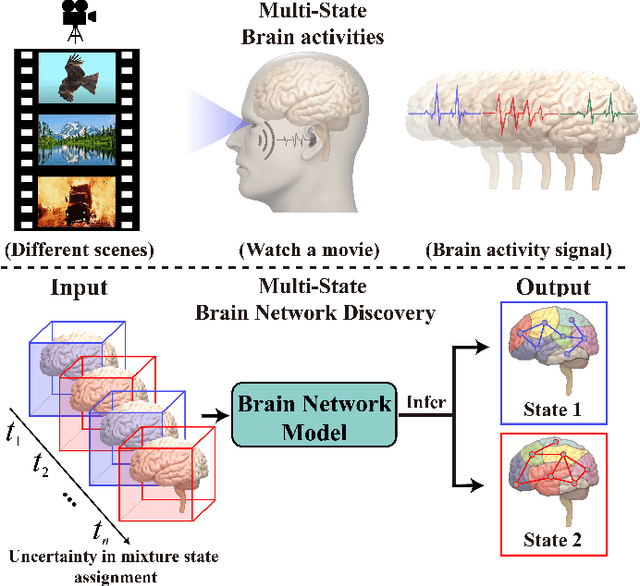
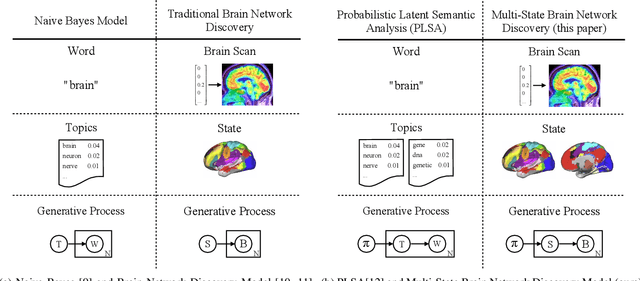
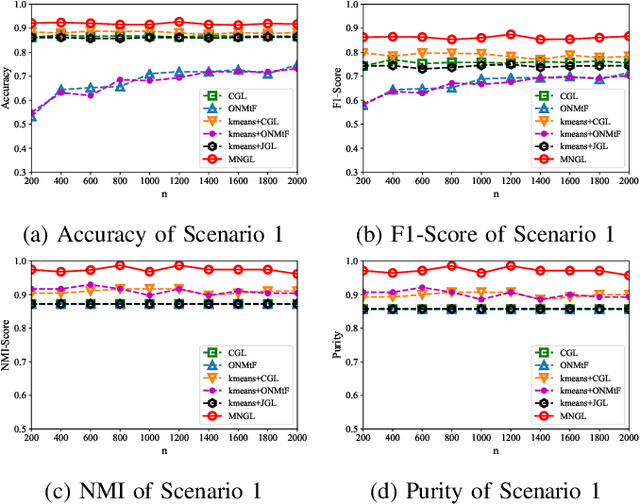
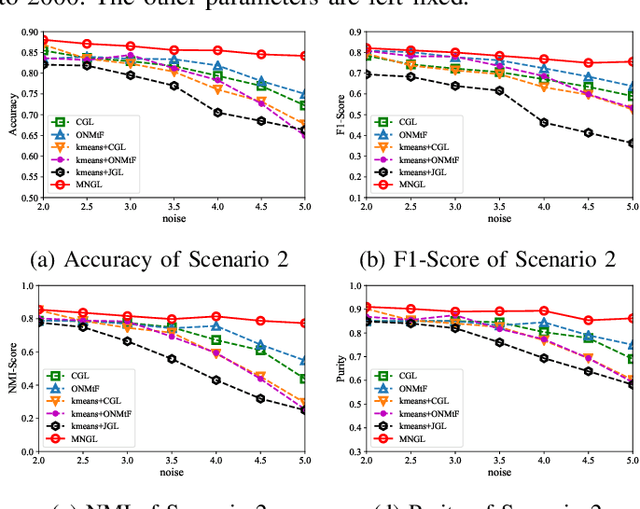
Brain network discovery aims to find nodes and edges from the spatio-temporal signals obtained by neuroimaging data, such as fMRI scans of human brains. Existing methods tend to derive representative or average brain networks, assuming observed signals are generated by only a single brain activity state. However, the human brain usually involves multiple activity states, which jointly determine the brain activities. The brain regions and their connectivity usually exhibit intricate patterns that are difficult to capture with only a single-state network. Recent studies find that brain parcellation and connectivity change according to the brain activity state. We refer to such brain networks as multi-state, and this mixture can help us understand human behavior. Thus, compared to a single-state network, a multi-state network can prevent us from losing crucial information of cognitive brain network. To achieve this, we propose a new model called MNGL (Multi-state Network Graphical Lasso), which successfully models multi-state brain networks by combining CGL (coherent graphical lasso) with GMM (Gaussian Mixture Model). Using both synthetic and real world ADHD 200 fMRI datasets, we demonstrate that MNGL outperforms recent state-of-the-art alternatives by discovering more explanatory and realistic results.
One-shot Joint Extraction, Registration and Segmentation of Neuroimaging Data
Jul 27, 2023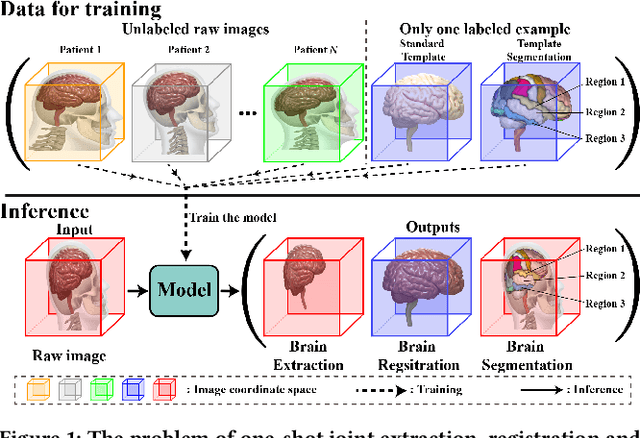
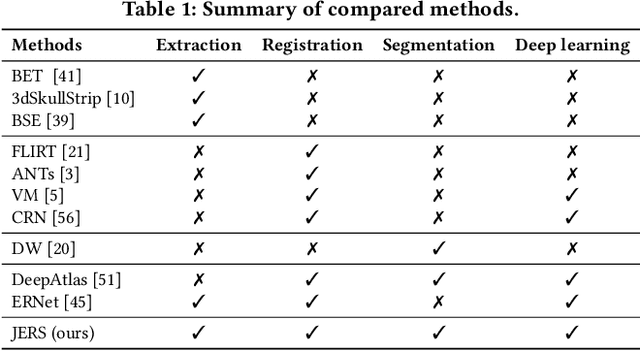
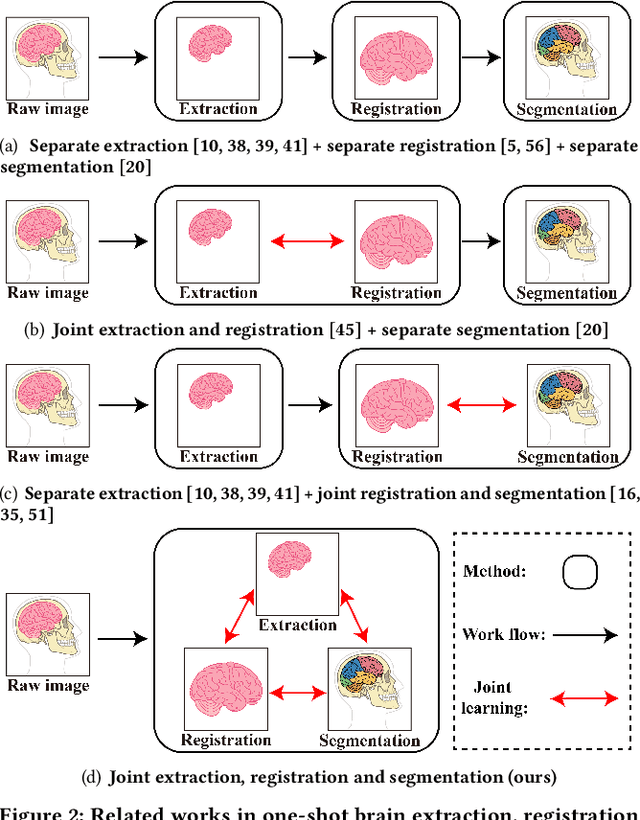
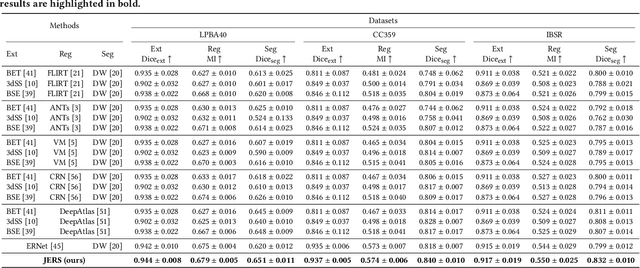
Brain extraction, registration and segmentation are indispensable preprocessing steps in neuroimaging studies. The aim is to extract the brain from raw imaging scans (i.e., extraction step), align it with a target brain image (i.e., registration step) and label the anatomical brain regions (i.e., segmentation step). Conventional studies typically focus on developing separate methods for the extraction, registration and segmentation tasks in a supervised setting. The performance of these methods is largely contingent on the quantity of training samples and the extent of visual inspections carried out by experts for error correction. Nevertheless, collecting voxel-level labels and performing manual quality control on high-dimensional neuroimages (e.g., 3D MRI) are expensive and time-consuming in many medical studies. In this paper, we study the problem of one-shot joint extraction, registration and segmentation in neuroimaging data, which exploits only one labeled template image (a.k.a. atlas) and a few unlabeled raw images for training. We propose a unified end-to-end framework, called JERS, to jointly optimize the extraction, registration and segmentation tasks, allowing feedback among them. Specifically, we use a group of extraction, registration and segmentation modules to learn the extraction mask, transformation and segmentation mask, where modules are interconnected and mutually reinforced by self-supervision. Empirical results on real-world datasets demonstrate that our proposed method performs exceptionally in the extraction, registration and segmentation tasks. Our code and data can be found at https://github.com/Anonymous4545/JERS
Finding Short Signals in Long Irregular Time Series with Continuous-Time Attention Policy Networks
Feb 08, 2023Irregularly-sampled time series (ITS) are native to high-impact domains like healthcare, where measurements are collected over time at uneven intervals. However, for many classification problems, only small portions of long time series are often relevant to the class label. In this case, existing ITS models often fail to classify long series since they rely on careful imputation, which easily over- or under-samples the relevant regions. Using this insight, we then propose CAT, a model that classifies multivariate ITS by explicitly seeking highly-relevant portions of an input series' timeline. CAT achieves this by integrating three components: (1) A Moment Network learns to seek relevant moments in an ITS's continuous timeline using reinforcement learning. (2) A Receptor Network models the temporal dynamics of both observations and their timing localized around predicted moments. (3) A recurrent Transition Model models the sequence of transitions between these moments, cultivating a representation with which the series is classified. Using synthetic and real data, we find that CAT outperforms ten state-of-the-art methods by finding short signals in long irregular time series.
ABN: Anti-Blur Neural Networks for Multi-Stage Deformable Image Registration
Dec 06, 2022



Deformable image registration, i.e., the task of aligning multiple images into one coordinate system by non-linear transformation, serves as an essential preprocessing step for neuroimaging data. Recent research on deformable image registration is mainly focused on improving the registration accuracy using multi-stage alignment methods, where the source image is repeatedly deformed in stages by a same neural network until it is well-aligned with the target image. Conventional methods for multi-stage registration can often blur the source image as the pixel/voxel values are repeatedly interpolated from the image generated by the previous stage. However, maintaining image quality such as sharpness during image registration is crucial to medical data analysis. In this paper, we study the problem of anti-blur deformable image registration and propose a novel solution, called Anti-Blur Network (ABN), for multi-stage image registration. Specifically, we use a pair of short-term registration and long-term memory networks to learn the nonlinear deformations at each stage, where the short-term registration network learns how to improve the registration accuracy incrementally and the long-term memory network combines all the previous deformations to allow an interpolation to perform on the raw image directly and preserve image sharpness. Extensive experiments on both natural and medical image datasets demonstrated that ABN can accurately register images while preserving their sharpness. Our code and data can be found at https://github.com/anonymous3214/ABN
ERNet: Unsupervised Collective Extraction and Registration in Neuroimaging Data
Dec 06, 2022



Brain extraction and registration are important preprocessing steps in neuroimaging data analysis, where the goal is to extract the brain regions from MRI scans (i.e., extraction step) and align them with a target brain image (i.e., registration step). Conventional research mainly focuses on developing methods for the extraction and registration tasks separately under supervised settings. The performance of these methods highly depends on the amount of training samples and visual inspections performed by experts for error correction. However, in many medical studies, collecting voxel-level labels and conducting manual quality control in high-dimensional neuroimages (e.g., 3D MRI) are very expensive and time-consuming. Moreover, brain extraction and registration are highly related tasks in neuroimaging data and should be solved collectively. In this paper, we study the problem of unsupervised collective extraction and registration in neuroimaging data. We propose a unified end-to-end framework, called ERNet (Extraction-Registration Network), to jointly optimize the extraction and registration tasks, allowing feedback between them. Specifically, we use a pair of multi-stage extraction and registration modules to learn the extraction mask and transformation, where the extraction network improves the extraction accuracy incrementally and the registration network successively warps the extracted image until it is well-aligned with the target image. Experiment results on real-world datasets show that our proposed method can effectively improve the performance on extraction and registration tasks in neuroimaging data. Our code and data can be found at https://github.com/ERNetERNet/ERNet
Stop&Hop: Early Classification of Irregular Time Series
Aug 21, 2022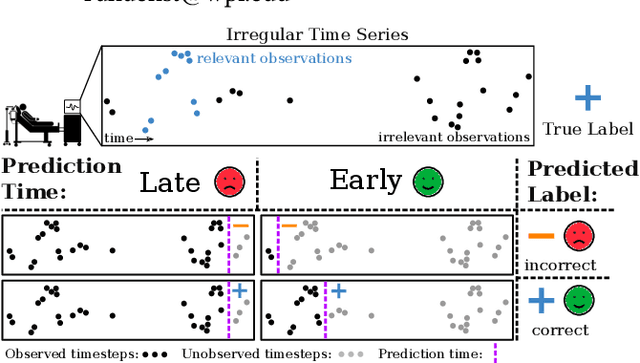
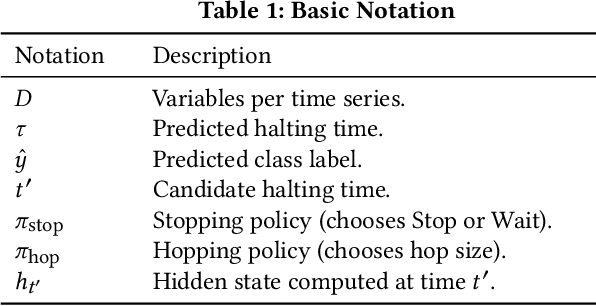
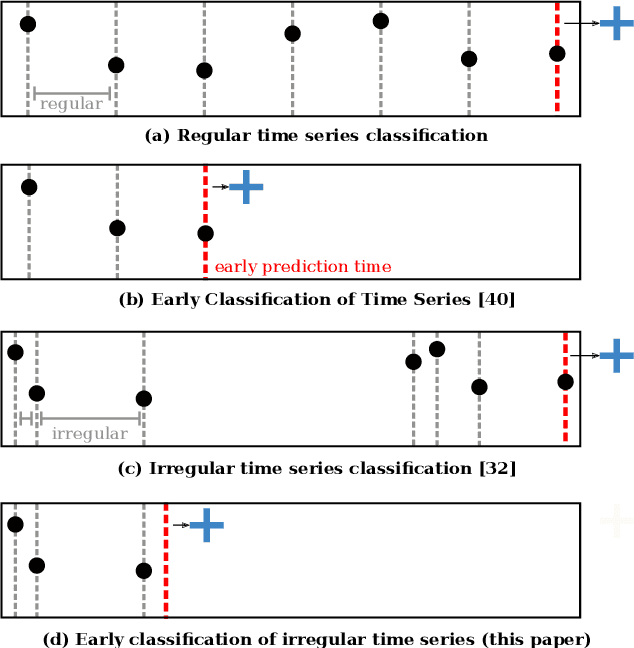
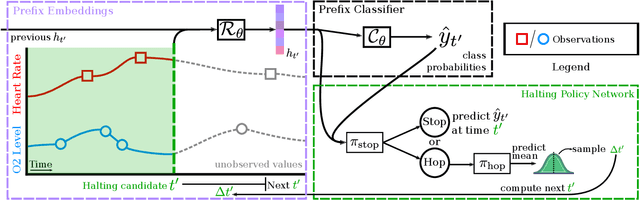
Early classification algorithms help users react faster to their machine learning model's predictions. Early warning systems in hospitals, for example, let clinicians improve their patients' outcomes by accurately predicting infections. While early classification systems are advancing rapidly, a major gap remains: existing systems do not consider irregular time series, which have uneven and often-long gaps between their observations. Such series are notoriously pervasive in impactful domains like healthcare. We bridge this gap and study early classification of irregular time series, a new setting for early classifiers that opens doors to more real-world problems. Our solution, Stop&Hop, uses a continuous-time recurrent network to model ongoing irregular time series in real time, while an irregularity-aware halting policy, trained with reinforcement learning, predicts when to stop and classify the streaming series. By taking real-valued step sizes, the halting policy flexibly decides exactly when to stop ongoing series in real time. This way, Stop&Hop seamlessly integrates information contained in the timing of observations, a new and vital source for early classification in this setting, with the time series values to provide early classifications for irregular time series. Using four synthetic and three real-world datasets, we demonstrate that Stop&Hop consistently makes earlier and more-accurate predictions than state-of-the-art alternatives adapted to this new problem. Our code is publicly available at https://github.com/thartvigsen/StopAndHop.
One-Shot Learning on Attributed Sequences
Jan 23, 2022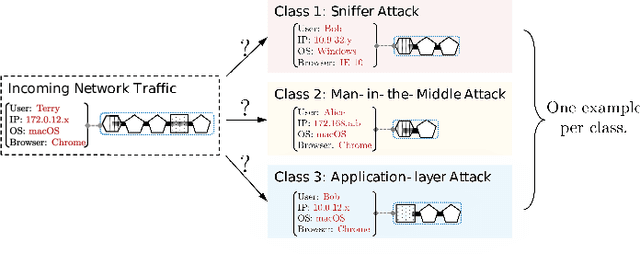
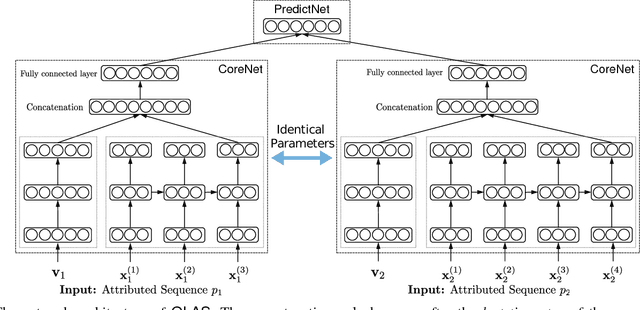
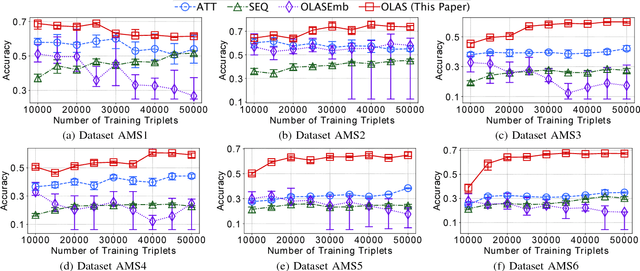
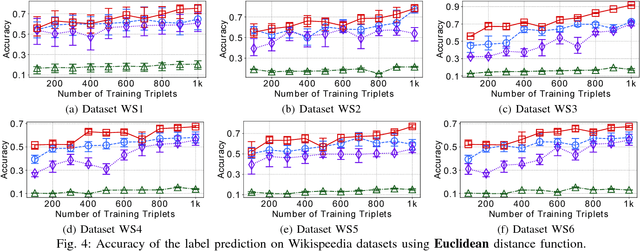
One-shot learning has become an important research topic in the last decade with many real-world applications. The goal of one-shot learning is to classify unlabeled instances when there is only one labeled example per class. Conventional problem setting of one-shot learning mainly focuses on the data that is already in feature space (such as images). However, the data instances in real-world applications are often more complex and feature vectors may not be available. In this paper, we study the problem of one-shot learning on attributed sequences, where each instance is composed of a set of attributes (e.g., user profile) and a sequence of categorical items (e.g., clickstream). This problem is important for a variety of real-world applications ranging from fraud prevention to network intrusion detection. This problem is more challenging than conventional one-shot learning since there are dependencies between attributes and sequences. We design a deep learning framework OLAS to tackle this problem. The proposed OLAS utilizes a twin network to generalize the features from pairwise attributed sequence examples. Empirical results on real-world datasets demonstrate the proposed OLAS can outperform the state-of-the-art methods under a rich variety of parameter settings.
Self-learn to Explain Siamese Networks Robustly
Sep 15, 2021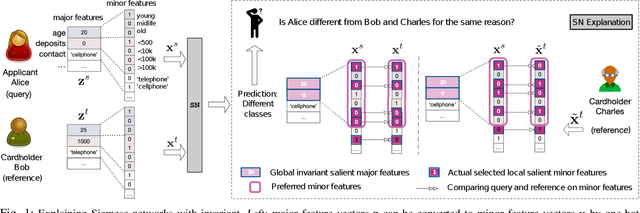
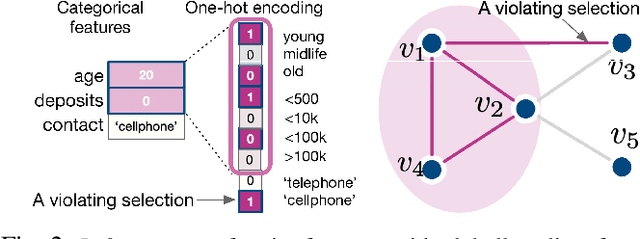
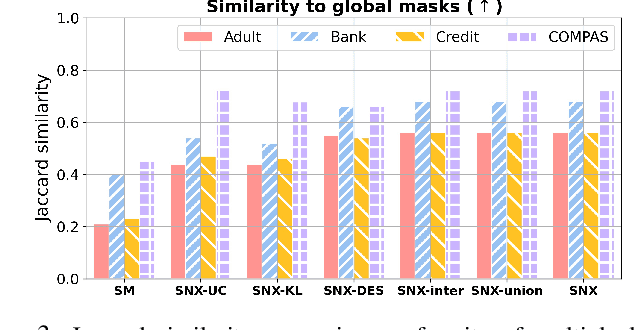
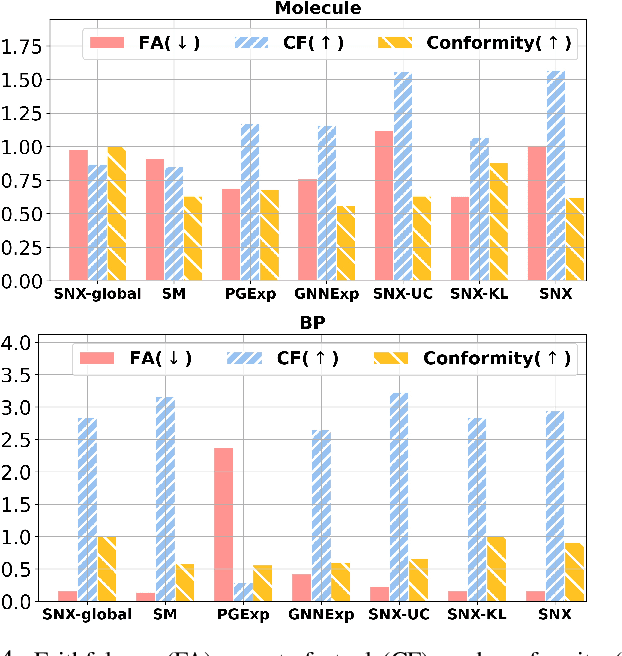
Learning to compare two objects are essential in applications, such as digital forensics, face recognition, and brain network analysis, especially when labeled data is scarce and imbalanced. As these applications make high-stake decisions and involve societal values like fairness and transparency, it is critical to explain the learned models. We aim to study post-hoc explanations of Siamese networks (SN) widely used in learning to compare. We characterize the instability of gradient-based explanations due to the additional compared object in SN, in contrast to architectures with a single input instance. We propose an optimization framework that derives global invariance from unlabeled data using self-learning to promote the stability of local explanations tailored for specific query-reference pairs. The optimization problems can be solved using gradient descent-ascent (GDA) for constrained optimization, or SGD for KL-divergence regularized unconstrained optimization, with convergence proofs, especially when the objective functions are nonconvex due to the Siamese architecture. Quantitative results and case studies on tabular and graph data from neuroscience and chemical engineering show that the framework respects the self-learned invariance while robustly optimizing the faithfulness and simplicity of the explanation. We further demonstrate the convergence of GDA experimentally.
Gaussian Mixture Graphical Lasso with Application to Edge Detection in Brain Networks
Jan 13, 2021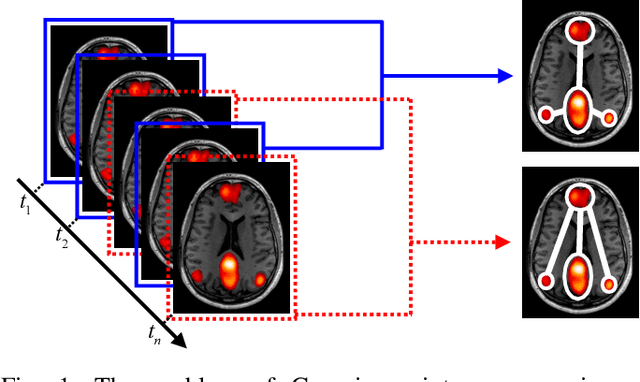
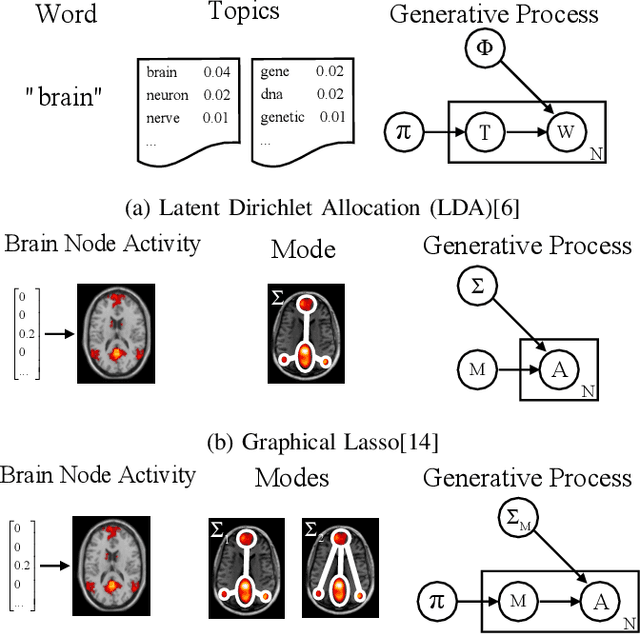
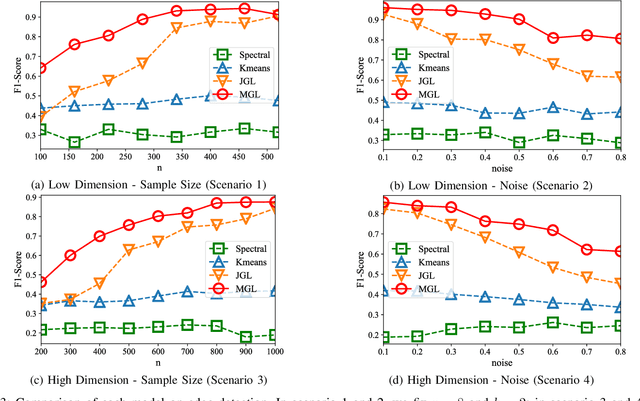
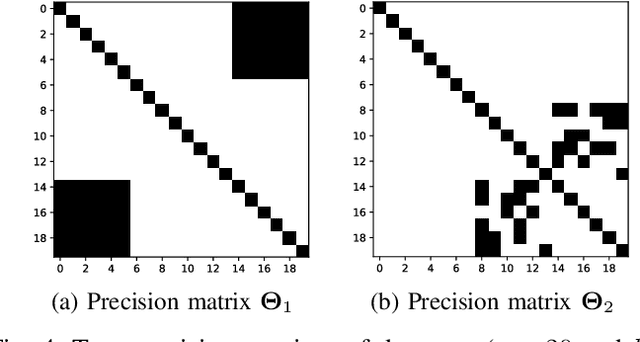
Sparse inverse covariance estimation (i.e., edge de-tection) is an important research problem in recent years, wherethe goal is to discover the direct connections between a set ofnodes in a networked system based upon the observed nodeactivities. Existing works mainly focus on unimodal distributions,where it is usually assumed that the observed activities aregenerated from asingleGaussian distribution (i.e., one graph).However, this assumption is too strong for many real-worldapplications. In many real-world applications (e.g., brain net-works), the node activities usually exhibit much more complexpatterns that are difficult to be captured by one single Gaussiandistribution. In this work, we are inspired by Latent DirichletAllocation (LDA) [4] and consider modeling the edge detectionproblem as estimating a mixture ofmultipleGaussian distribu-tions, where each corresponds to a separate sub-network. Toaddress this problem, we propose a novel model called GaussianMixture Graphical Lasso (MGL). It learns the proportionsof signals generated by each mixture component and theirparameters iteratively via an EM framework. To obtain moreinterpretable networks, MGL imposes a special regularization,called Mutual Exclusivity Regularization (MER), to minimize theoverlap between different sub-networks. MER also addresses thecommon issues in read-world data sets,i.e., noisy observationsand small sample size. Through the extensive experiments onsynthetic and real brain data sets, the results demonstrate thatMGL can effectively discover multiple connectivity structuresfrom the observed node activities