 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Interpretable Measure for Quantifying Predictive Dependence between Continuous Random Variables -- Extended Version
Jan 18, 2025
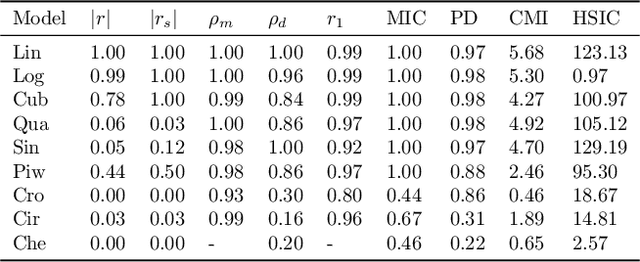


A fundamental task in statistical learning is quantifying the joint dependence or association between two continuous random variables. We introduce a novel, fully non-parametric measure that assesses the degree of association between continuous variables $X$ and $Y$, capable of capturing a wide range of relationships, including non-functional ones. A key advantage of this measure is its interpretability: it quantifies the expected relative loss in predictive accuracy when the distribution of $X$ is ignored in predicting $Y$. This measure is bounded within the interval [0,1] and is equal to zero if and only if $X$ and $Y$ are independent. We evaluate the performance of our measure on over 90,000 real and synthetic datasets, benchmarking it against leading alternatives. Our results demonstrate that the proposed measure provides valuable insights into underlying relationships, particularly in cases where existing methods fail to capture important dependencies.
Top-Down Deep Clustering with Multi-generator GANs
Dec 24, 2021
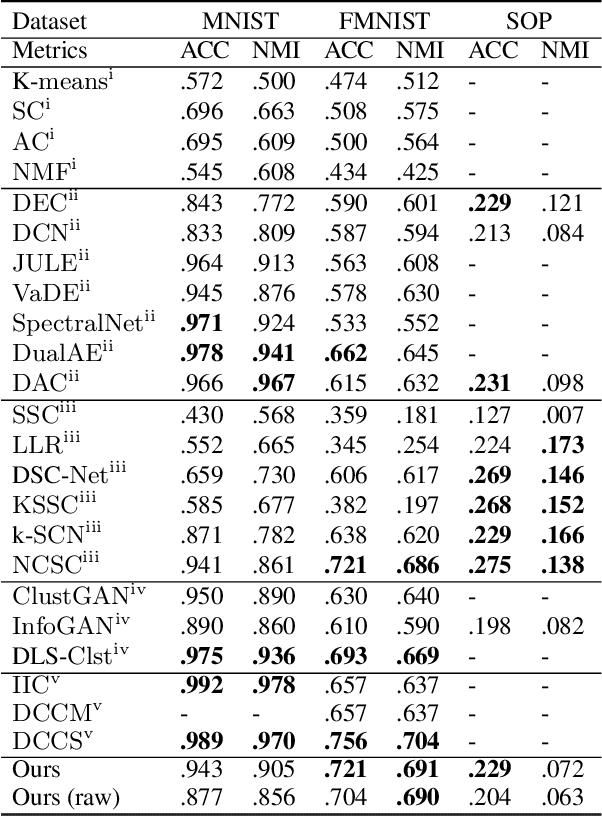
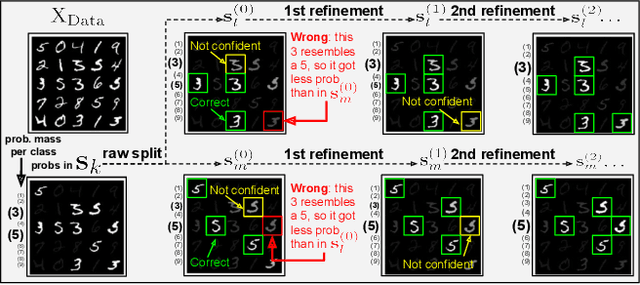

Deep clustering (DC) leverages the representation power of deep architectures to learn embedding spaces that are optimal for cluster analysis. This approach filters out low-level information irrelevant for clustering and has proven remarkably successful for high dimensional data spaces. Some DC methods employ Generative Adversarial Networks (GANs), motivated by the powerful latent representations these models are able to learn implicitly. In this work, we propose HC-MGAN, a new technique based on GANs with multiple generators (MGANs), which have not been explored for clustering. Our method is inspired by the observation that each generator of a MGAN tends to generate data that correlates with a sub-region of the real data distribution. We use this clustered generation to train a classifier for inferring from which generator a given image came from, thus providing a semantically meaningful clustering for the real distribution. Additionally, we design our method so that it is performed in a top-down hierarchical clustering tree, thus proposing the first hierarchical DC method, to the best of our knowledge. We conduct several experiments to evaluate the proposed method against recent DC methods, obtaining competitive results. Last, we perform an exploratory analysis of the hierarchical clustering tree that highlights how accurately it organizes the data in a hierarchy of semantically coherent patterns.
Stop the Clock: Are Timeout Effects Real?
Sep 14, 2020


Timeout is a short interruption during games used to communicate a change in strategy, to give the players a rest or to stop a negative flow in the game. Whatever the reason, coaches expect an improvement in their team's performance after a timeout. But how effective are these timeouts in doing so? The simple average of the differences between the scores before and after the timeouts has been used as evidence that there is an effect and that it is substantial. We claim that these statistical averages are not proper evidence and a more sound approach is needed. We applied a formal causal framework using a large dataset of official NBA play-by-play tables and drew our assumptions about the data generation process in a causal graph. Using different matching techniques to estimate the causal effect of timeouts, we concluded that timeouts have no effect on teams' performances. Actually, since most timeouts are called when the opposing team is scoring more frequently, the moments that follow resemble an improvement in the team's performance but are just the natural game tendency to return to its average state. This is another example of what statisticians call the regression to the mean phenomenon.
Burstiness Scale: a highly parsimonious model for characterizing random series of events
Feb 20, 2016
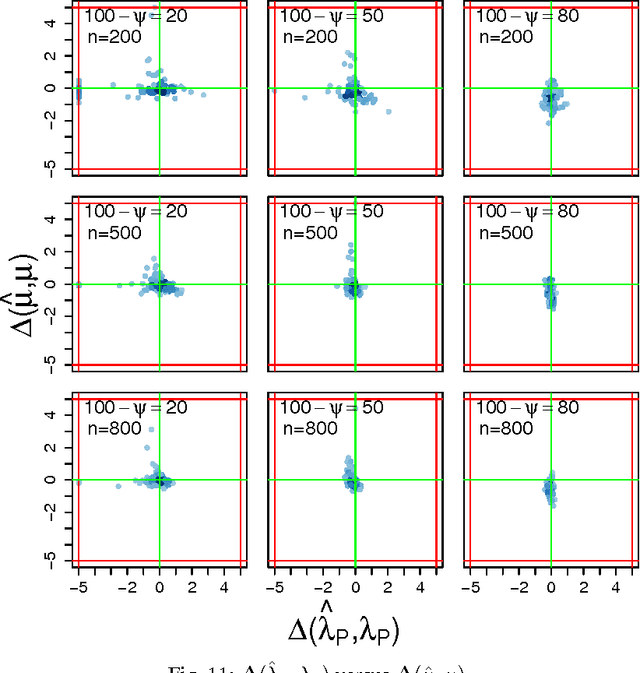
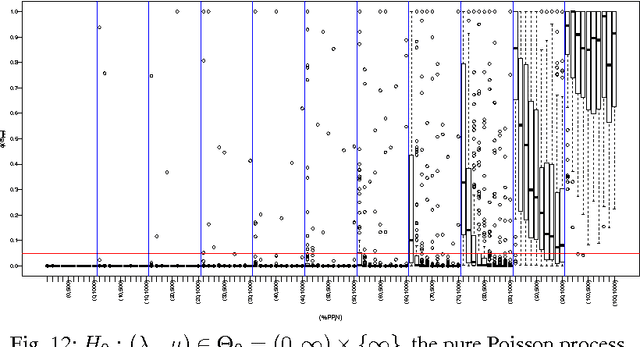
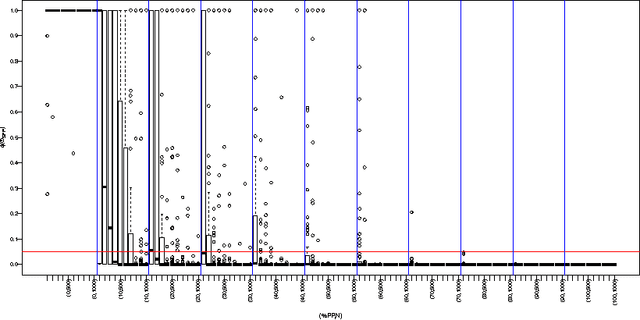
The problem to accurately and parsimoniously characterize random series of events (RSEs) present in the Web, such as e-mail conversations or Twitter hashtags, is not trivial. Reports found in the literature reveal two apparent conflicting visions of how RSEs should be modeled. From one side, the Poissonian processes, of which consecutive events follow each other at a relatively regular time and should not be correlated. On the other side, the self-exciting processes, which are able to generate bursts of correlated events and periods of inactivities. The existence of many and sometimes conflicting approaches to model RSEs is a consequence of the unpredictability of the aggregated dynamics of our individual and routine activities, which sometimes show simple patterns, but sometimes results in irregular rising and falling trends. In this paper we propose a highly parsimonious way to characterize general RSEs, namely the Burstiness Scale (BuSca) model. BuSca views each RSE as a mix of two independent process: a Poissonian and a self-exciting one. Here we describe a fast method to extract the two parameters of BuSca that, together, gives the burstyness scale, which represents how much of the RSE is due to bursty and viral effects. We validated our method in eight diverse and large datasets containing real random series of events seen in Twitter, Yelp, e-mail conversations, Digg, and online forums. Results showed that, even using only two parameters, BuSca is able to accurately describe RSEs seen in these diverse systems, what can leverage many applications.