 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiplines to Combat Misinformation on Encrypted Platforms: A Case Study of the 2019 Indian Election on WhatsApp
Jun 08, 2021


WhatsApp is a popular chat application used by over 2 billion users worldwide. However, due to end-to-end encryption, there is currently no easy way to fact-check content on WhatsApp at scale. In this paper, we analyze the usefulness of a crowd-sourced system on WhatsApp through which users can submit "tips" containing messages they want fact-checked. We compare the tips sent to a WhatsApp tipline run during the 2019 Indian national elections with the messages circulating in large, public groups on WhatsApp and other social media platforms during the same period. We find that tiplines are a very useful lens into WhatsApp conversations: a significant fraction of messages and images sent to the tipline match with the content being shared on public WhatsApp groups and other social media. Our analysis also shows that tiplines cover the most popular content well, and a majority of such content is often shared to the tipline before appearing in large, public WhatsApp groups. Overall, the analysis suggests tiplines can be an effective source for discovering content to fact-check.
Claim Matching Beyond English to Scale Global Fact-Checking
Jun 01, 2021
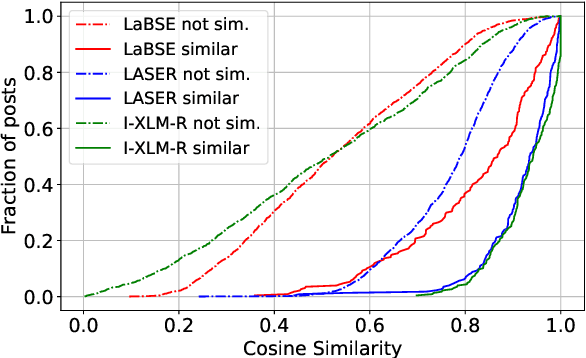
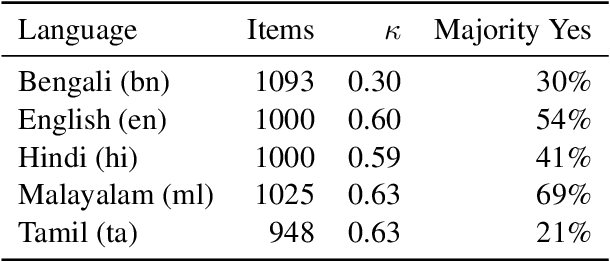
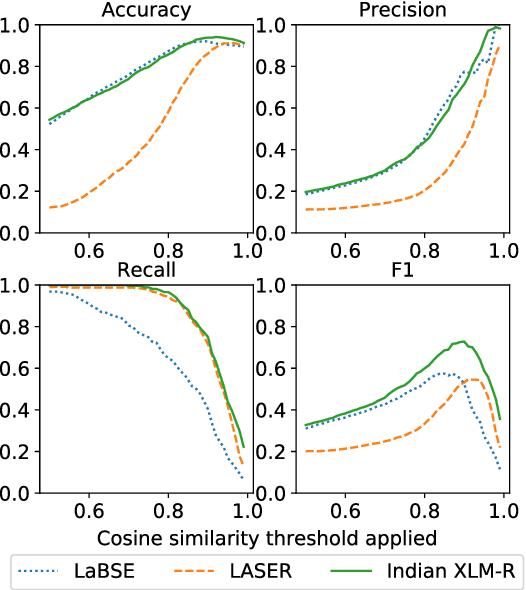
Manual fact-checking does not scale well to serve the needs of the internet. This issue is further compounded in non-English contexts. In this paper, we discuss claim matching as a possible solution to scale fact-checking. We define claim matching as the task of identifying pairs of textual messages containing claims that can be served with one fact-check. We construct a novel dataset of WhatsApp tipline and public group messages alongside fact-checked claims that are first annotated for containing "claim-like statements" and then matched with potentially similar items and annotated for claim matching. Our dataset contains content in high-resource (English, Hindi) and lower-resource (Bengali, Malayalam, Tamil) languages. We train our own embedding model using knowledge distillation and a high-quality "teacher" model in order to address the imbalance in embedding quality between the low- and high-resource languages in our dataset. We provide evaluations on the performance of our solution and compare with baselines and existing state-of-the-art multilingual embedding models, namely LASER and LaBSE. We demonstrate that our performance exceeds LASER and LaBSE in all settings. We release our annotated datasets, codebooks, and trained embedding model to allow for further research.