 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSports and Women's Sports: Gender Bias in Text Generation with Olympic Data
Feb 06, 2025



Large Language Models (LLMs) have been shown to be biased in prior work, as they generate text that is in line with stereotypical views of the world or that is not representative of the viewpoints and values of historically marginalized demographic groups. In this work, we propose using data from parallel men's and women's events at the Olympic Games to investigate different forms of gender bias in language models. We define three metrics to measure bias, and find that models are consistently biased against women when the gender is ambiguous in the prompt. In this case, the model frequently retrieves only the results of the men's event with or without acknowledging them as such, revealing pervasive gender bias in LLMs in the context of athletics.
A PhD Student's Perspective on Research in NLP in the Era of Very Large Language Models
May 21, 2023Recent progress in large language models has enabled the deployment of many generative NLP applications. At the same time, it has also led to a misleading public discourse that ``it's all been solved.'' Not surprisingly, this has in turn made many NLP researchers -- especially those at the beginning of their career -- wonder about what NLP research area they should focus on. This document is a compilation of NLP research directions that are rich for exploration, reflecting the views of a diverse group of PhD students in an academic research lab. While we identify many research areas, many others exist; we do not cover those areas that are currently addressed by LLMs but where LLMs lag behind in performance, or those focused on LLM development. We welcome suggestions for other research directions to include: https://bit.ly/nlp-era-llm
We Are in This Together: Quantifying Community Subjective Wellbeing and Resilience
Aug 23, 2022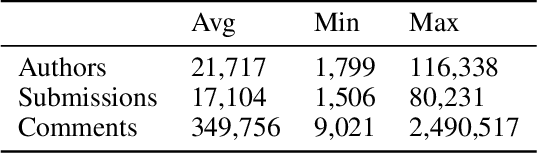
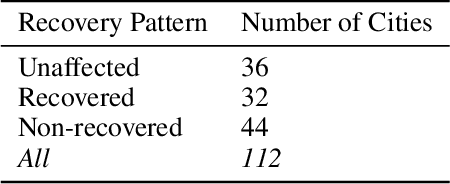
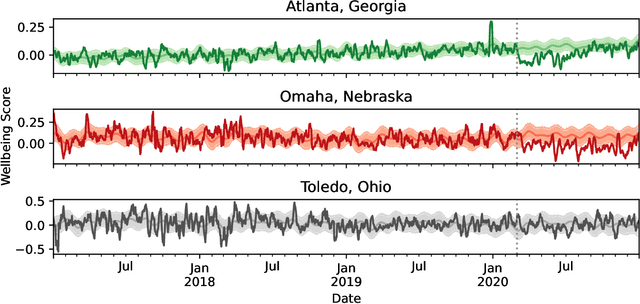
The COVID-19 pandemic disrupted everyone's life across the world. In this work, we characterize the subjective wellbeing patterns of 112 cities across the United States during the pandemic prior to vaccine availability, as exhibited in subreddits corresponding to the cities. We quantify subjective wellbeing using positive and negative affect. We then measure the pandemic's impact by comparing a community's observed wellbeing with its expected wellbeing, as forecasted by time series models derived from prior to the pandemic.We show that general community traits reflected in language can be predictive of community resilience. We predict how the pandemic would impact the wellbeing of each community based on linguistic and interaction features from normal times \textit{before} the pandemic. We find that communities with interaction characteristics corresponding to more closely connected users and higher engagement were less likely to be significantly impacted. Notably, we find that communities that talked more about social ties normally experienced in-person, such as friends, family, and affiliations, were actually more likely to be impacted. Additionally, we use the same features to also predict how quickly each community would recover after the initial onset of the pandemic. We similarly find that communities that talked more about family, affiliations, and identifying as part of a group had a slower recovery.
Quantifying the Effects of COVID-19 on Mental Health Support Forums
Sep 08, 2020
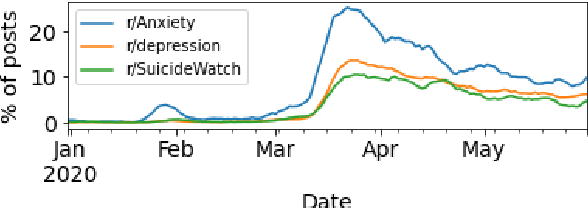


The COVID-19 pandemic, like many of the disease outbreaks that have preceded it, is likely to have a profound effect on mental health. Understanding its impact can inform strategies for mitigating negative consequences. In this work, we seek to better understand the effects of COVID-19 on mental health by examining discussions within mental health support communities on Reddit. First, we quantify the rate at which COVID-19 is discussed in each community, or subreddit, in order to understand levels of preoccupation with the pandemic. Next, we examine the volume of activity in order to determine whether the quantity of people seeking online mental health support has risen. Finally, we analyze how COVID-19 has influenced language use and topics of discussion within each subreddit.