 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDensity-Guided Response Optimization: Community-Grounded Alignment via Implicit Acceptance Signals
Mar 03, 2026Language models deployed in online communities must adapt to norms that vary across social, cultural, and domain-specific contexts. Prior alignment approaches rely on explicit preference supervision or predefined principles, which are effective for well-resourced settings but exclude most online communities -- particularly those without institutional backing, annotation infrastructure, or organized around sensitive topics -- where preference elicitation is costly, ethically fraught, or culturally misaligned. We observe that communities already express preferences implicitly through what content they accept, engage with, and allow to persist. We show that this acceptance behavior induces measurable geometric structure in representation space: accepted responses occupy coherent, high-density regions that reflect community-specific norms, while rejected content falls in sparser or misaligned areas. We operationalize this structure as an implicit preference signal for alignment and introduce density-guided response optimization (DGRO), a method that aligns language models to community norms without requiring explicit preference labels. Using labeled preference data, we demonstrate that local density recovers pairwise community judgments, indicating that geometric structure encodes meaningful preference signal. We then apply DGRO in annotation-scarce settings across diverse communities spanning platform, topic, and language. DGRO-aligned models consistently produce responses preferred by human annotators, domain experts, and model-based judges over supervised and prompt-based baselines. We position DGRO as a practical alignment alternative for communities where explicit preference supervision is unavailable or misaligned with situated practices, and discuss the implications and risks of learning from emergent acceptance behavior.
SOTOPIA-S4: a user-friendly system for flexible, customizable, and large-scale social simulation
Apr 19, 2025Social simulation through large language model (LLM) agents is a promising approach to explore and validate hypotheses related to social science questions and LLM agents behavior. We present SOTOPIA-S4, a fast, flexible, and scalable social simulation system that addresses the technical barriers of current frameworks while enabling practitioners to generate multi-turn and multi-party LLM-based interactions with customizable evaluation metrics for hypothesis testing. SOTOPIA-S4 comes as a pip package that contains a simulation engine, an API server with flexible RESTful APIs for simulation management, and a web interface that enables both technical and non-technical users to design, run, and analyze simulations without programming. We demonstrate the usefulness of SOTOPIA-S4 with two use cases involving dyadic hiring negotiation and multi-party planning scenarios.
Exploratory Models of Human-AI Teams: Leveraging Human Digital Twins to Investigate Trust Development
Nov 01, 2024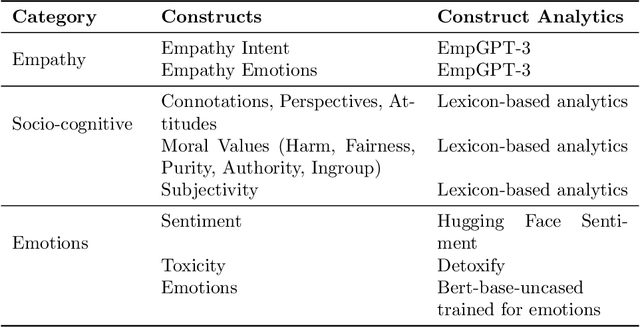
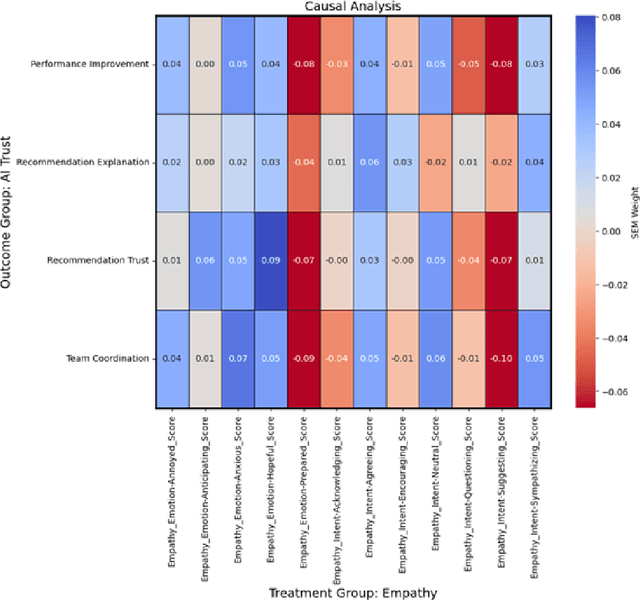
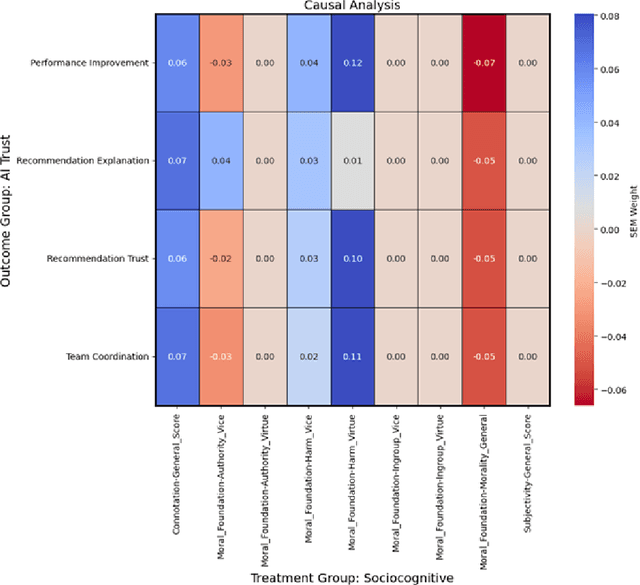
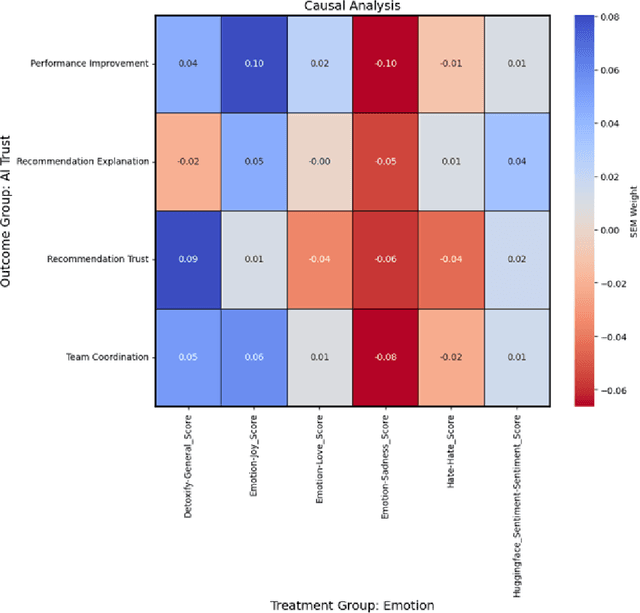
As human-agent teaming (HAT) research continues to grow, computational methods for modeling HAT behaviors and measuring HAT effectiveness also continue to develop. One rising method involves the use of human digital twins (HDT) to approximate human behaviors and socio-emotional-cognitive reactions to AI-driven agent team members. In this paper, we address three research questions relating to the use of digital twins for modeling trust in HATs. First, to address the question of how we can appropriately model and operationalize HAT trust through HDT HAT experiments, we conducted causal analytics of team communication data to understand the impact of empathy, socio-cognitive, and emotional constructs on trust formation. Additionally, we reflect on the current state of the HAT trust science to discuss characteristics of HAT trust that must be replicable by a HDT such as individual differences in trust tendencies, emergent trust patterns, and appropriate measurement of these characteristics over time. Second, to address the question of how valid measures of HDT trust are for approximating human trust in HATs, we discuss the properties of HDT trust: self-report measures, interaction-based measures, and compliance type behavioral measures. Additionally, we share results of preliminary simulations comparing different LLM models for generating HDT communications and analyze their ability to replicate human-like trust dynamics. Third, to address how HAT experimental manipulations will extend to human digital twin studies, we share experimental design focusing on propensity to trust for HDTs vs. transparency and competency-based trust for AI agents.
Modeling Information Narrative Detection and Evolution on Telegram during the Russia-Ukraine War
Sep 12, 2024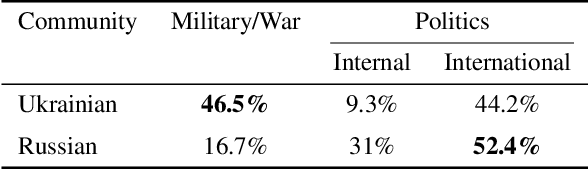
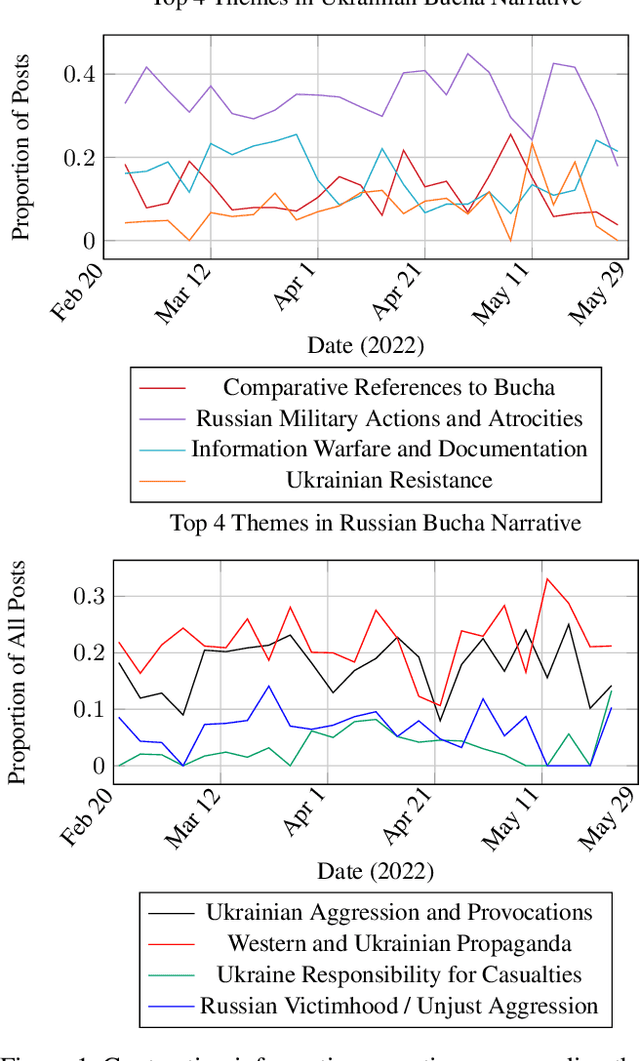
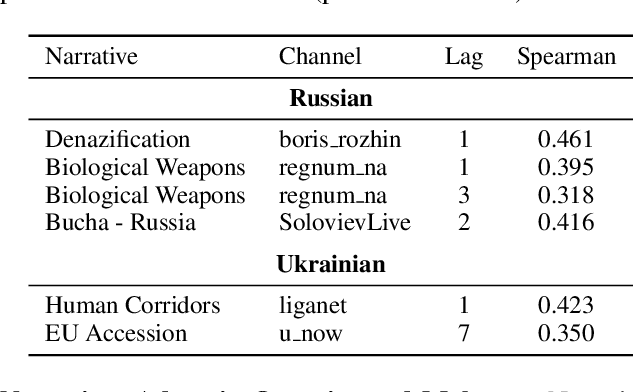
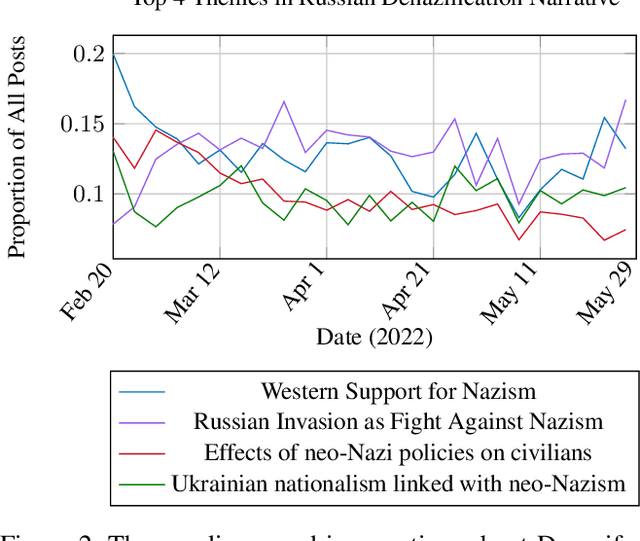
Following the Russian Federation's full-scale invasion of Ukraine in February 2022, a multitude of information narratives emerged within both pro-Russian and pro-Ukrainian communities online. As the conflict progresses, so too do the information narratives, constantly adapting and influencing local and global community perceptions and attitudes. This dynamic nature of the evolving information environment (IE) underscores a critical need to fully discern how narratives evolve and affect online communities. Existing research, however, often fails to capture information narrative evolution, overlooking both the fluid nature of narratives and the internal mechanisms that drive their evolution. Recognizing this, we introduce a novel approach designed to both model narrative evolution and uncover the underlying mechanisms driving them. In this work we perform a comparative discourse analysis across communities on Telegram covering the initial three months following the invasion. First, we uncover substantial disparities in narratives and perceptions between pro-Russian and pro-Ukrainian communities. Then, we probe deeper into prevalent narratives of each group, identifying key themes and examining the underlying mechanisms fueling their evolution. Finally, we explore influences and factors that may shape the development and spread of narratives.
Towards Safer Online Spaces: Simulating and Assessing Intervention Strategies for Eating Disorder Discussions
Sep 06, 2024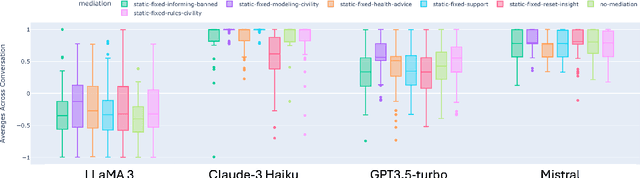

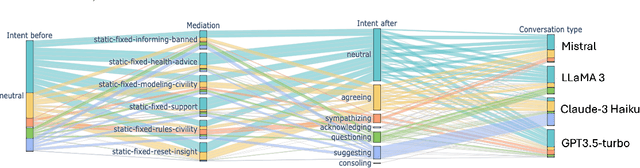
Eating disorders are complex mental health conditions that affect millions of people around the world. Effective interventions on social media platforms are crucial, yet testing strategies in situ can be risky. We present a novel LLM-driven experimental testbed for simulating and assessing intervention strategies in ED-related discussions. Our framework generates synthetic conversations across multiple platforms, models, and ED-related topics, allowing for controlled experimentation with diverse intervention approaches. We analyze the impact of various intervention strategies on conversation dynamics across four dimensions: intervention type, generative model, social media platform, and ED-related community/topic. We employ cognitive domain analysis metrics, including sentiment, emotions, etc., to evaluate the effectiveness of interventions. Our findings reveal that civility-focused interventions consistently improve positive sentiment and emotional tone across all dimensions, while insight-resetting approaches tend to increase negative emotions. We also uncover significant biases in LLM-generated conversations, with cognitive metrics varying notably between models (Claude-3 Haiku $>$ Mistral $>$ GPT-3.5-turbo $>$ LLaMA3) and even between versions of the same model. These variations highlight the importance of model selection in simulating realistic discussions related to ED. Our work provides valuable information on the complex dynamics of ED-related discussions and the effectiveness of various intervention strategies.
ValueScope: Unveiling Implicit Norms and Values via Return Potential Model of Social Interactions
Jul 02, 2024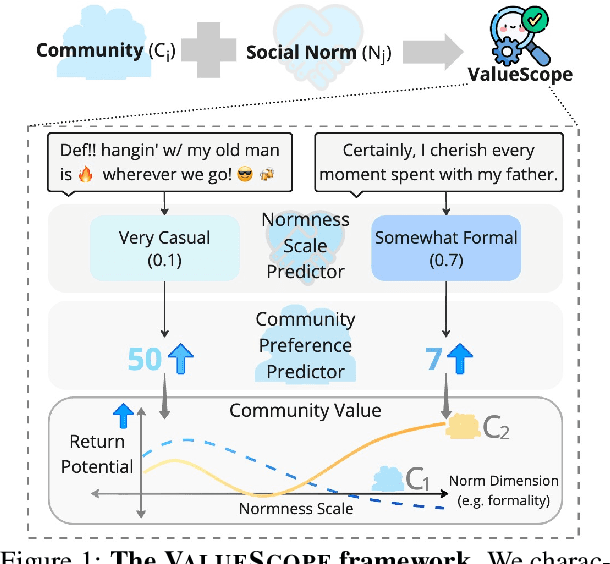
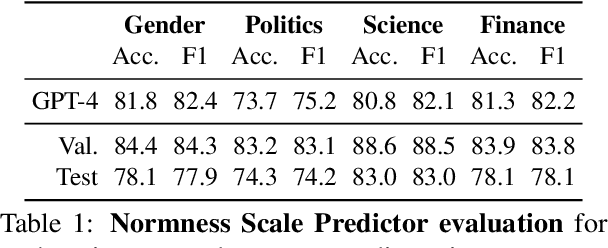
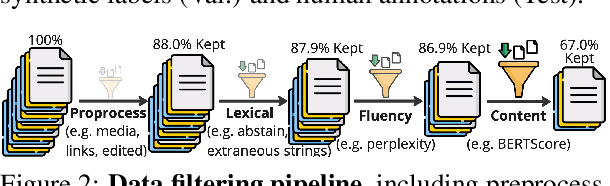

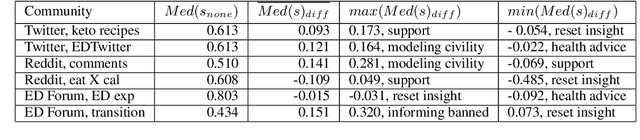
This study introduces ValueScope, a framework leveraging language models to quantify social norms and values within online communities, grounded in social science perspectives on normative structures. We employ ValueScope to dissect and analyze linguistic and stylistic expressions across 13 Reddit communities categorized under gender, politics, science, and finance. Our analysis provides a quantitative foundation showing that even closely related communities exhibit remarkably diverse norms. This diversity supports existing theories and adds a new dimension--community preference--to understanding community interactions. ValueScope not only delineates differing social norms among communities but also effectively traces their evolution and the influence of significant external events like the U.S. presidential elections and the emergence of new sub-communities. The framework thus highlights the pivotal role of social norms in shaping online interactions, presenting a substantial advance in both the theory and application of social norm studies in digital spaces.
Anticipating Technical Expertise and Capability Evolution in Research Communities using Dynamic Graph Transformers
Jul 18, 2023The ability to anticipate technical expertise and capability evolution trends globally is essential for national and global security, especially in safety-critical domains like nuclear nonproliferation (NN) and rapidly emerging fields like artificial intelligence (AI). In this work, we extend traditional statistical relational learning approaches (e.g., link prediction in collaboration networks) and formulate a problem of anticipating technical expertise and capability evolution using dynamic heterogeneous graph representations. We develop novel capabilities to forecast collaboration patterns, authorship behavior, and technical capability evolution at different granularities (e.g., scientist and institution levels) in two distinct research fields. We implement a dynamic graph transformer (DGT) neural architecture, which pushes the state-of-the-art graph neural network models by (a) forecasting heterogeneous (rather than homogeneous) nodes and edges, and (b) relying on both discrete -- and continuous -- time inputs. We demonstrate that our DGT models predict collaboration, partnership, and expertise patterns with 0.26, 0.73, and 0.53 mean reciprocal rank values for AI and 0.48, 0.93, and 0.22 for NN domains. DGT model performance exceeds the best-performing static graph baseline models by 30-80% across AI and NN domains. Our findings demonstrate that DGT models boost inductive task performance, when previously unseen nodes appear in the test data, for the domains with emerging collaboration patterns (e.g., AI). Specifically, models accurately predict which established scientists will collaborate with early career scientists and vice-versa in the AI domain.
EXPERT: Public Benchmarks for Dynamic Heterogeneous Academic Graphs
Apr 14, 2022
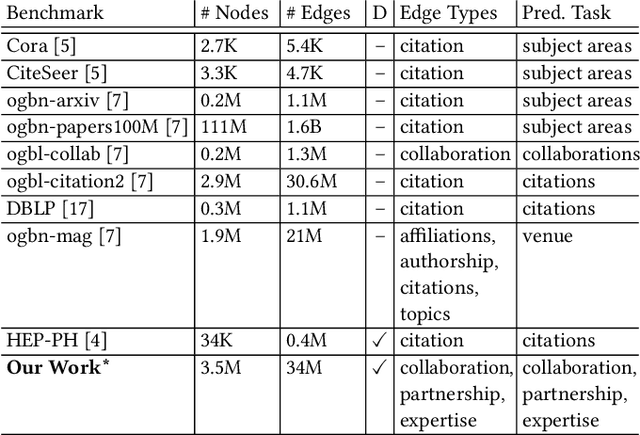

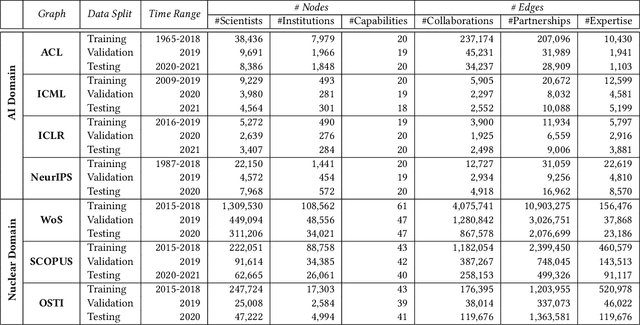
Machine learning models that learn from dynamic graphs face nontrivial challenges in learning and inference as both nodes and edges change over time. The existing large-scale graph benchmark datasets that are widely used by the community primarily focus on homogeneous node and edge attributes and are static. In this work, we present a variety of large scale, dynamic heterogeneous academic graphs to test the effectiveness of models developed for multi-step graph forecasting tasks. Our novel datasets cover both context and content information extracted from scientific publications across two communities: Artificial Intelligence (AI) and Nuclear Nonproliferation (NN). In addition, we propose a systematic approach to improve the existing evaluation procedures used in the graph forecasting models.
Unsupervised Keyphrase Extraction via Interpretable Neural Networks
Mar 15, 2022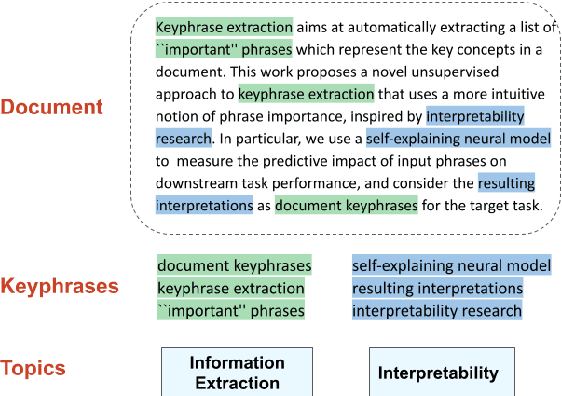
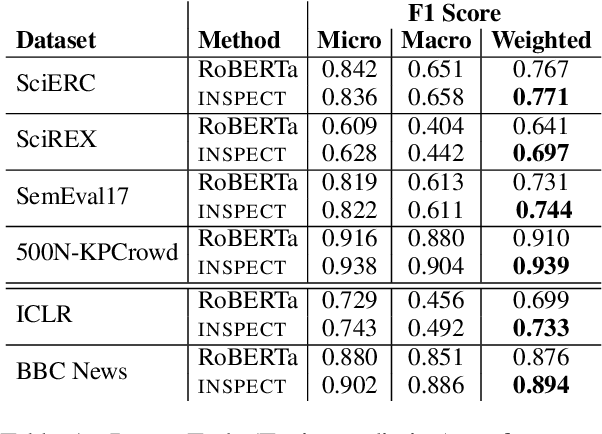
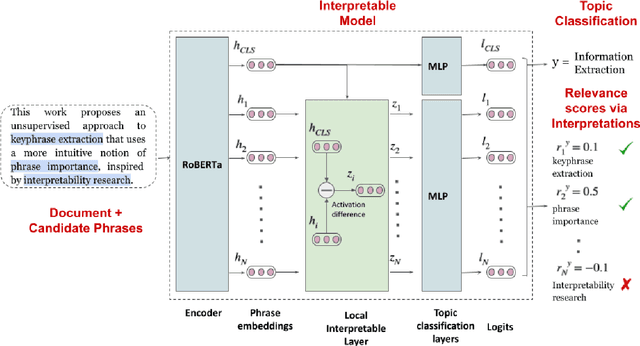
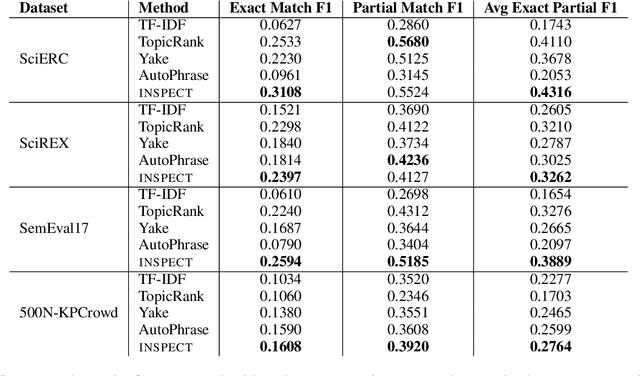
Keyphrase extraction aims at automatically extracting a list of "important" phrases which represent the key concepts in a document. Prior approaches for unsupervised keyphrase extraction resort to heuristic notions of phrase importance via embedding similarities or graph centrality, requiring extensive domain expertise to develop them. Our work proposes an alternative operational definition: phrases that are most useful for predicting the topic of a text are important keyphrases. To this end, we propose INSPECT -- a self-explaining neural framework for identifying influential keyphrases by measuring the predictive impact of input phrases on the downstream task of topic classification. We show that this novel approach not only alleviates the need for ad-hoc heuristics but also achieves state-of-the-art results in unsupervised keyphrase extraction across four diverse datasets in two domains: scientific publications and news articles. Ultimately, our study suggests a new usage of interpretable neural networks as an intrinsic component in NLP systems, and not only as a tool for explaining model predictions to humans.
Identifying Causal Influences on Publication Trends and Behavior: A Case Study of the Computational Linguistics Community
Oct 15, 2021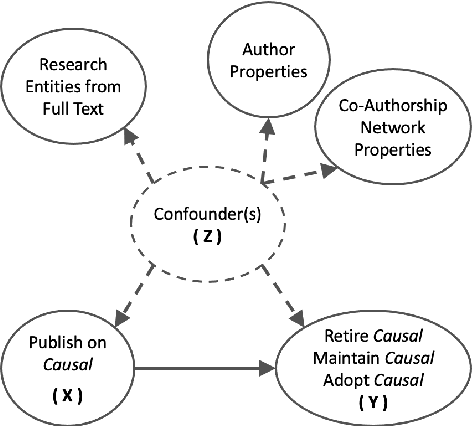

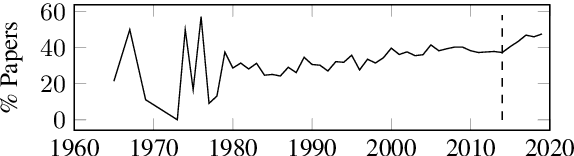
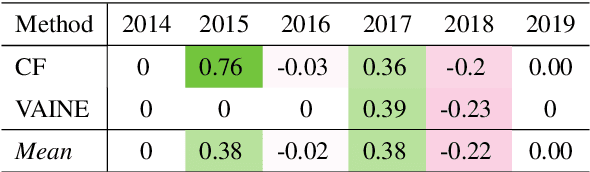
Drawing causal conclusions from observational real-world data is a very much desired but challenging task. In this paper we present mixed-method analyses to investigate causal influences of publication trends and behavior on the adoption, persistence, and retirement of certain research foci -- methodologies, materials, and tasks that are of interest to the computational linguistics (CL) community. Our key findings highlight evidence of the transition to rapidly emerging methodologies in the research community (e.g., adoption of bidirectional LSTMs influencing the retirement of LSTMs), the persistent engagement with trending tasks and techniques (e.g., deep learning, embeddings, generative, and language models), the effect of scientist location from outside the US, e.g., China on propensity of researching languages beyond English, and the potential impact of funding for large-scale research programs. We anticipate this work to provide useful insights about publication trends and behavior and raise the awareness about the potential for causal inference in the computational linguistics and a broader scientific community.