 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnticipating Technical Expertise and Capability Evolution in Research Communities using Dynamic Graph Transformers
Jul 18, 2023The ability to anticipate technical expertise and capability evolution trends globally is essential for national and global security, especially in safety-critical domains like nuclear nonproliferation (NN) and rapidly emerging fields like artificial intelligence (AI). In this work, we extend traditional statistical relational learning approaches (e.g., link prediction in collaboration networks) and formulate a problem of anticipating technical expertise and capability evolution using dynamic heterogeneous graph representations. We develop novel capabilities to forecast collaboration patterns, authorship behavior, and technical capability evolution at different granularities (e.g., scientist and institution levels) in two distinct research fields. We implement a dynamic graph transformer (DGT) neural architecture, which pushes the state-of-the-art graph neural network models by (a) forecasting heterogeneous (rather than homogeneous) nodes and edges, and (b) relying on both discrete -- and continuous -- time inputs. We demonstrate that our DGT models predict collaboration, partnership, and expertise patterns with 0.26, 0.73, and 0.53 mean reciprocal rank values for AI and 0.48, 0.93, and 0.22 for NN domains. DGT model performance exceeds the best-performing static graph baseline models by 30-80% across AI and NN domains. Our findings demonstrate that DGT models boost inductive task performance, when previously unseen nodes appear in the test data, for the domains with emerging collaboration patterns (e.g., AI). Specifically, models accurately predict which established scientists will collaborate with early career scientists and vice-versa in the AI domain.
EXPERT: Public Benchmarks for Dynamic Heterogeneous Academic Graphs
Apr 14, 2022
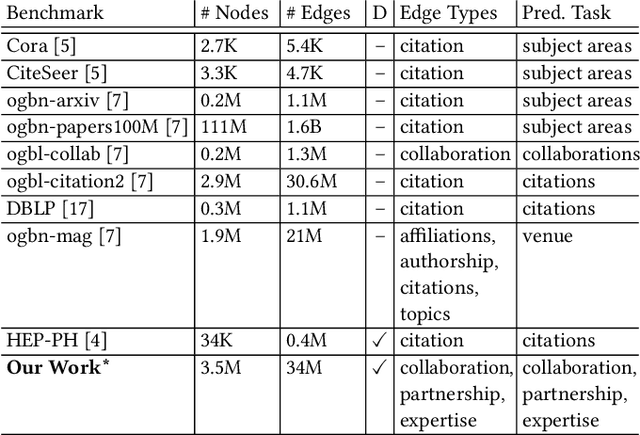

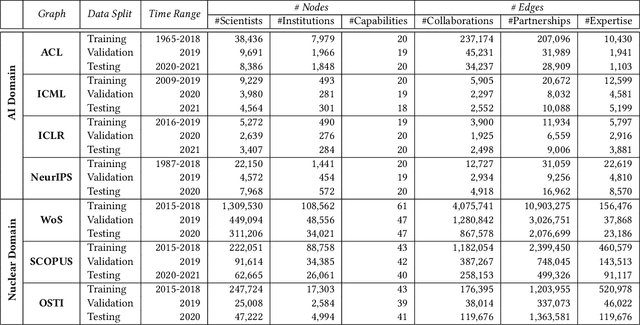
Machine learning models that learn from dynamic graphs face nontrivial challenges in learning and inference as both nodes and edges change over time. The existing large-scale graph benchmark datasets that are widely used by the community primarily focus on homogeneous node and edge attributes and are static. In this work, we present a variety of large scale, dynamic heterogeneous academic graphs to test the effectiveness of models developed for multi-step graph forecasting tasks. Our novel datasets cover both context and content information extracted from scientific publications across two communities: Artificial Intelligence (AI) and Nuclear Nonproliferation (NN). In addition, we propose a systematic approach to improve the existing evaluation procedures used in the graph forecasting models.
Towards Trustworthy Deception Detection: Benchmarking Model Robustness across Domains, Modalities, and Languages
Apr 23, 2021

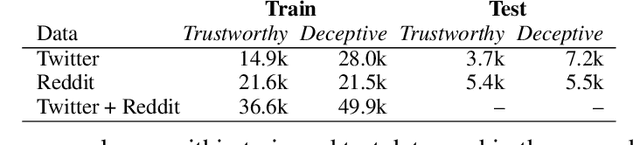
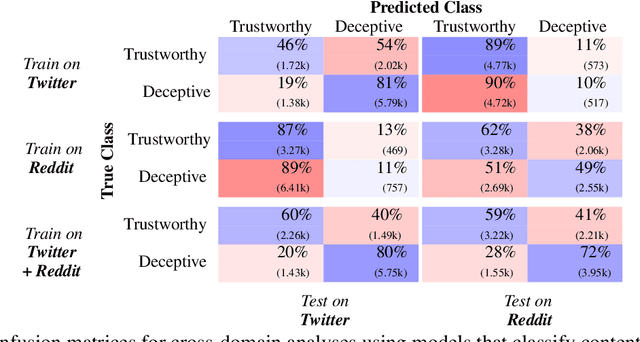
Evaluating model robustness is critical when developing trustworthy models not only to gain deeper understanding of model behavior, strengths, and weaknesses, but also to develop future models that are generalizable and robust across expected environments a model may encounter in deployment. In this paper we present a framework for measuring model robustness for an important but difficult text classification task - deceptive news detection. We evaluate model robustness to out-of-domain data, modality-specific features, and languages other than English. Our investigation focuses on three type of models: LSTM models trained on multiple datasets(Cross-Domain), several fusion LSTM models trained with images and text and evaluated with three state-of-the-art embeddings, BERT ELMo, and GloVe (Cross-Modality), and character-level CNN models trained on multiple languages (Cross-Language). Our analyses reveal a significant drop in performance when testing neural models on out-of-domain data and non-English languages that may be mitigated using diverse training data. We find that with additional image content as input, ELMo embeddings yield significantly fewer errors compared to BERT orGLoVe. Most importantly, this work not only carefully analyzes deception model robustness but also provides a framework of these analyses that can be applied to new models or extended datasets in the future.
Evaluating Deception Detection Model Robustness To Linguistic Variation
Apr 23, 2021
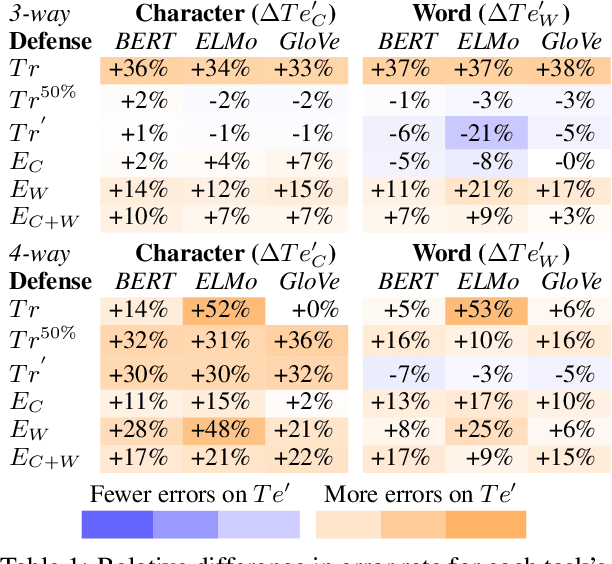

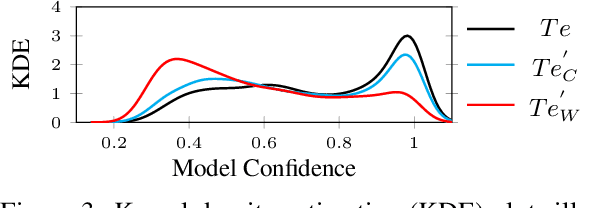
With the increasing use of machine-learning driven algorithmic judgements, it is critical to develop models that are robust to evolving or manipulated inputs. We propose an extensive analysis of model robustness against linguistic variation in the setting of deceptive news detection, an important task in the context of misinformation spread online. We consider two prediction tasks and compare three state-of-the-art embeddings to highlight consistent trends in model performance, high confidence misclassifications, and high impact failures. By measuring the effectiveness of adversarial defense strategies and evaluating model susceptibility to adversarial attacks using character- and word-perturbed text, we find that character or mixed ensemble models are the most effective defenses and that character perturbation-based attack tactics are more successful.
Fishing for Clickbaits in Social Images and Texts with Linguistically-Infused Neural Network Models
Oct 17, 2017

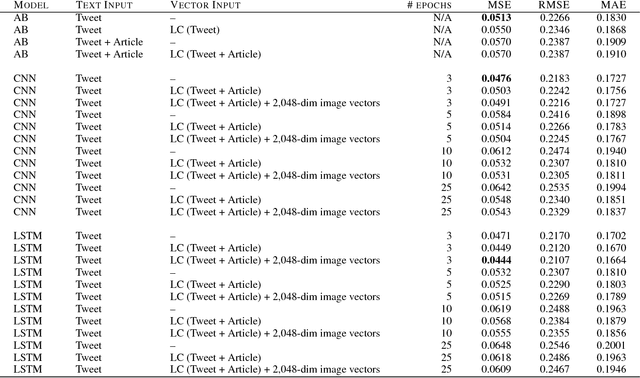

This paper presents the results and conclusions of our participation in the Clickbait Challenge 2017 on automatic clickbait detection in social media. We first describe linguistically-infused neural network models and identify informative representations to predict the level of clickbaiting present in Twitter posts. Our models allow to answer the question not only whether a post is a clickbait or not, but to what extent it is a clickbait post e.g., not at all, slightly, considerably, or heavily clickbaity using a score ranging from 0 to 1. We evaluate the predictive power of models trained on varied text and image representations extracted from tweets. Our best performing model that relies on the tweet text and linguistic markers of biased language extracted from the tweet and the corresponding page yields mean squared error (MSE) of 0.04, mean absolute error (MAE) of 0.16 and R2 of 0.43 on the held-out test data. For the binary classification setup (clickbait vs. non-clickbait), our model achieved F1 score of 0.69. We have not found that image representations combined with text yield significant performance improvement yet. Nevertheless, this work is the first to present preliminary analysis of objects extracted using Google Tensorflow object detection API from images in clickbait vs. non-clickbait Twitter posts. Finally, we outline several steps to improve model performance as a part of the future work.