 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFishing for Clickbaits in Social Images and Texts with Linguistically-Infused Neural Network Models
Paper and Code


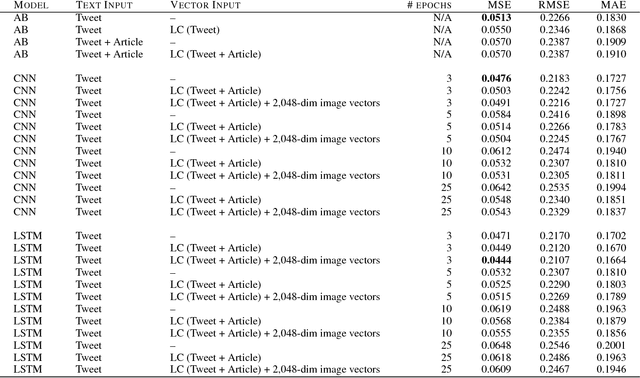

This paper presents the results and conclusions of our participation in the Clickbait Challenge 2017 on automatic clickbait detection in social media. We first describe linguistically-infused neural network models and identify informative representations to predict the level of clickbaiting present in Twitter posts. Our models allow to answer the question not only whether a post is a clickbait or not, but to what extent it is a clickbait post e.g., not at all, slightly, considerably, or heavily clickbaity using a score ranging from 0 to 1. We evaluate the predictive power of models trained on varied text and image representations extracted from tweets. Our best performing model that relies on the tweet text and linguistic markers of biased language extracted from the tweet and the corresponding page yields mean squared error (MSE) of 0.04, mean absolute error (MAE) of 0.16 and R2 of 0.43 on the held-out test data. For the binary classification setup (clickbait vs. non-clickbait), our model achieved F1 score of 0.69. We have not found that image representations combined with text yield significant performance improvement yet. Nevertheless, this work is the first to present preliminary analysis of objects extracted using Google Tensorflow object detection API from images in clickbait vs. non-clickbait Twitter posts. Finally, we outline several steps to improve model performance as a part of the future work.