 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Benefits of Domain-Pretraining of Generative Large Language Models for Chemistry
Nov 05, 2024
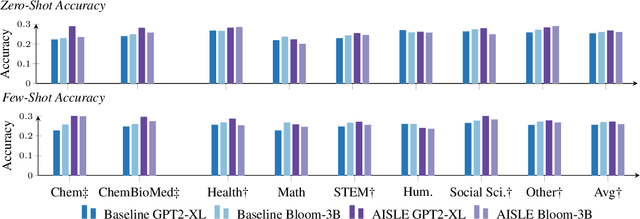
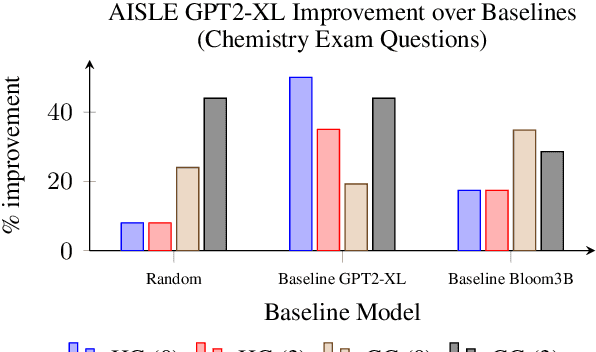
A proliferation of Large Language Models (the GPT series, BLOOM, LLaMA, and more) are driving forward novel development of multipurpose AI for a variety of tasks, particularly natural language processing (NLP) tasks. These models demonstrate strong performance on a range of tasks; however, there has been evidence of brittleness when applied to more niche or narrow domains where hallucinations or fluent but incorrect responses reduce performance. Given the complex nature of scientific domains, it is prudent to investigate the trade-offs of leveraging off-the-shelf versus more targeted foundation models for scientific domains. In this work, we examine the benefits of in-domain pre-training for a given scientific domain, chemistry, and compare these to open-source, off-the-shelf models with zero-shot and few-shot prompting. Our results show that not only do in-domain base models perform reasonably well on in-domain tasks in a zero-shot setting but that further adaptation using instruction fine-tuning yields impressive performance on chemistry-specific tasks such as named entity recognition and molecular formula generation.
EXPERT: Public Benchmarks for Dynamic Heterogeneous Academic Graphs
Apr 14, 2022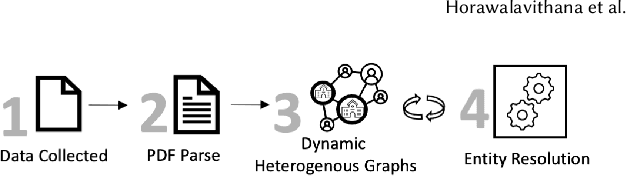
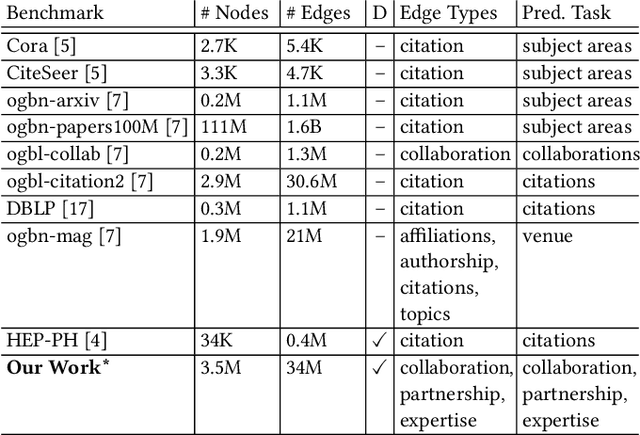

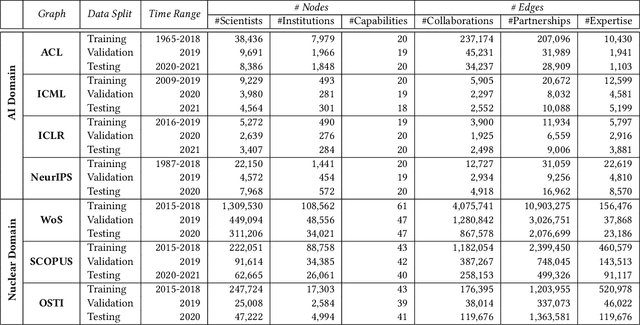
Machine learning models that learn from dynamic graphs face nontrivial challenges in learning and inference as both nodes and edges change over time. The existing large-scale graph benchmark datasets that are widely used by the community primarily focus on homogeneous node and edge attributes and are static. In this work, we present a variety of large scale, dynamic heterogeneous academic graphs to test the effectiveness of models developed for multi-step graph forecasting tasks. Our novel datasets cover both context and content information extracted from scientific publications across two communities: Artificial Intelligence (AI) and Nuclear Nonproliferation (NN). In addition, we propose a systematic approach to improve the existing evaluation procedures used in the graph forecasting models.
Unsupervised Keyphrase Extraction via Interpretable Neural Networks
Mar 15, 2022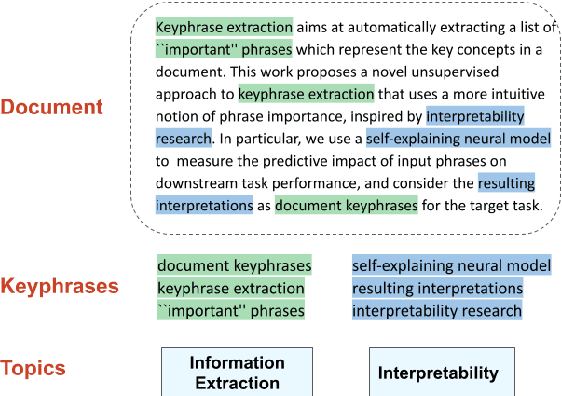
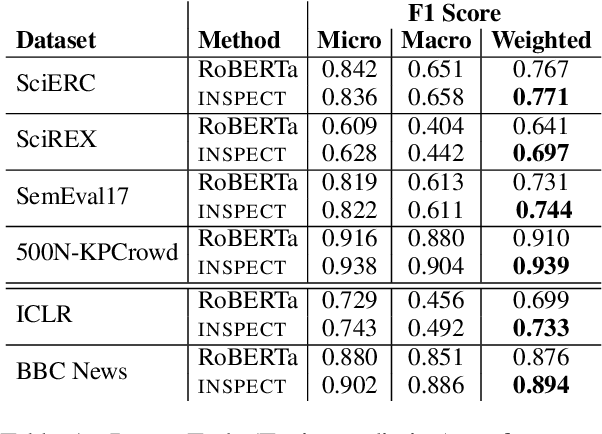
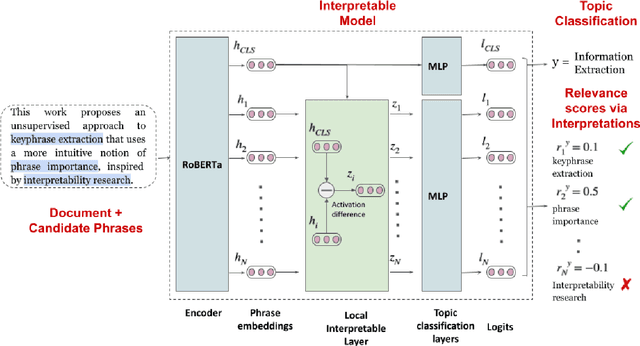
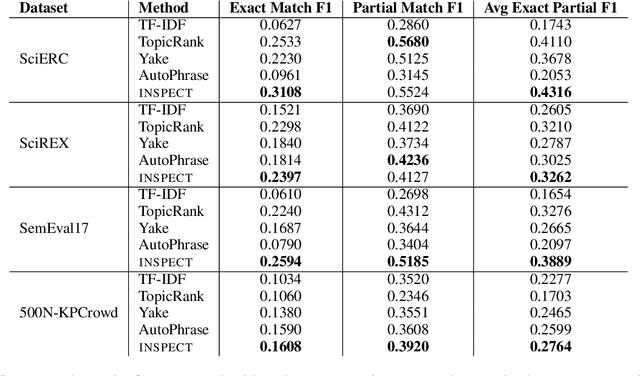
Keyphrase extraction aims at automatically extracting a list of "important" phrases which represent the key concepts in a document. Prior approaches for unsupervised keyphrase extraction resort to heuristic notions of phrase importance via embedding similarities or graph centrality, requiring extensive domain expertise to develop them. Our work proposes an alternative operational definition: phrases that are most useful for predicting the topic of a text are important keyphrases. To this end, we propose INSPECT -- a self-explaining neural framework for identifying influential keyphrases by measuring the predictive impact of input phrases on the downstream task of topic classification. We show that this novel approach not only alleviates the need for ad-hoc heuristics but also achieves state-of-the-art results in unsupervised keyphrase extraction across four diverse datasets in two domains: scientific publications and news articles. Ultimately, our study suggests a new usage of interpretable neural networks as an intrinsic component in NLP systems, and not only as a tool for explaining model predictions to humans.
Identifying Causal Influences on Publication Trends and Behavior: A Case Study of the Computational Linguistics Community
Oct 15, 2021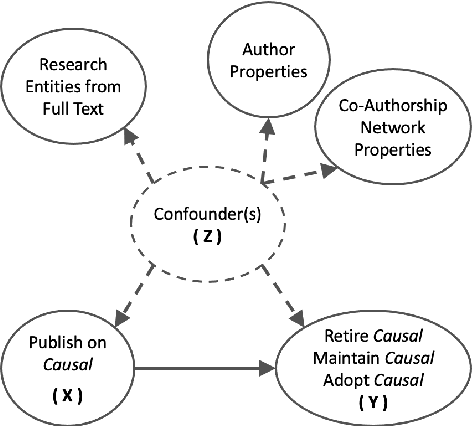

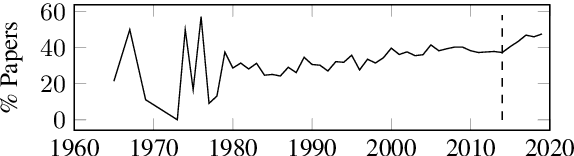
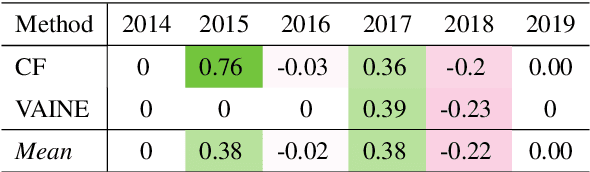
Drawing causal conclusions from observational real-world data is a very much desired but challenging task. In this paper we present mixed-method analyses to investigate causal influences of publication trends and behavior on the adoption, persistence, and retirement of certain research foci -- methodologies, materials, and tasks that are of interest to the computational linguistics (CL) community. Our key findings highlight evidence of the transition to rapidly emerging methodologies in the research community (e.g., adoption of bidirectional LSTMs influencing the retirement of LSTMs), the persistent engagement with trending tasks and techniques (e.g., deep learning, embeddings, generative, and language models), the effect of scientist location from outside the US, e.g., China on propensity of researching languages beyond English, and the potential impact of funding for large-scale research programs. We anticipate this work to provide useful insights about publication trends and behavior and raise the awareness about the potential for causal inference in the computational linguistics and a broader scientific community.
Towards Trustworthy Deception Detection: Benchmarking Model Robustness across Domains, Modalities, and Languages
Apr 23, 2021

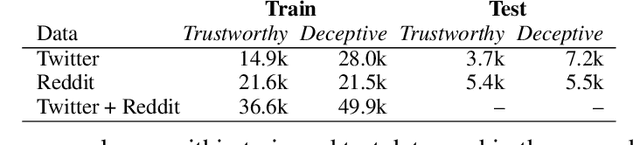
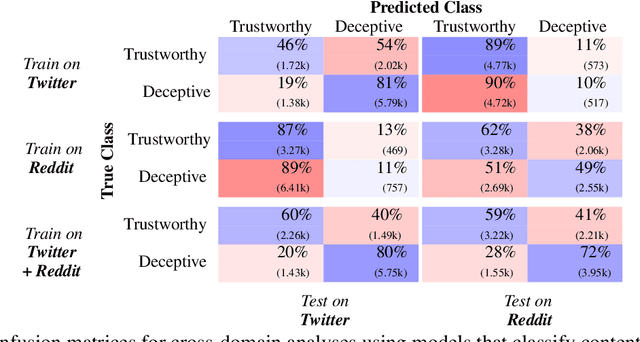
Evaluating model robustness is critical when developing trustworthy models not only to gain deeper understanding of model behavior, strengths, and weaknesses, but also to develop future models that are generalizable and robust across expected environments a model may encounter in deployment. In this paper we present a framework for measuring model robustness for an important but difficult text classification task - deceptive news detection. We evaluate model robustness to out-of-domain data, modality-specific features, and languages other than English. Our investigation focuses on three type of models: LSTM models trained on multiple datasets(Cross-Domain), several fusion LSTM models trained with images and text and evaluated with three state-of-the-art embeddings, BERT ELMo, and GloVe (Cross-Modality), and character-level CNN models trained on multiple languages (Cross-Language). Our analyses reveal a significant drop in performance when testing neural models on out-of-domain data and non-English languages that may be mitigated using diverse training data. We find that with additional image content as input, ELMo embeddings yield significantly fewer errors compared to BERT orGLoVe. Most importantly, this work not only carefully analyzes deception model robustness but also provides a framework of these analyses that can be applied to new models or extended datasets in the future.
Evaluating Deception Detection Model Robustness To Linguistic Variation
Apr 23, 2021
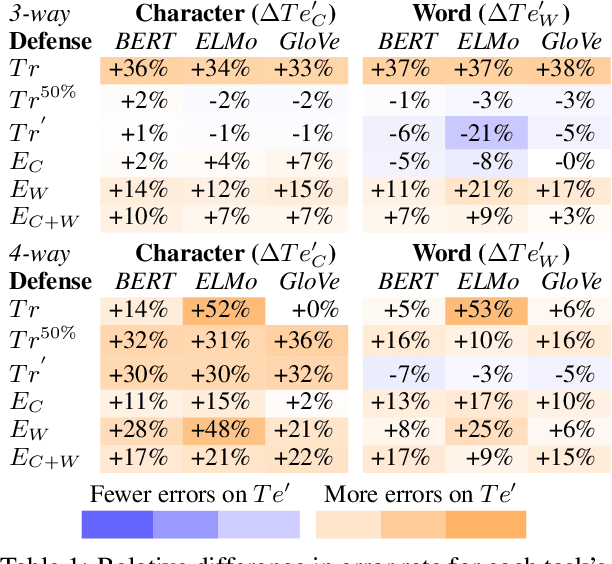

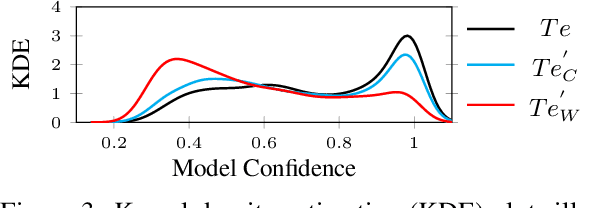
With the increasing use of machine-learning driven algorithmic judgements, it is critical to develop models that are robust to evolving or manipulated inputs. We propose an extensive analysis of model robustness against linguistic variation in the setting of deceptive news detection, an important task in the context of misinformation spread online. We consider two prediction tasks and compare three state-of-the-art embeddings to highlight consistent trends in model performance, high confidence misclassifications, and high impact failures. By measuring the effectiveness of adversarial defense strategies and evaluating model susceptibility to adversarial attacks using character- and word-perturbed text, we find that character or mixed ensemble models are the most effective defenses and that character perturbation-based attack tactics are more successful.
Measure Utility, Gain Trust: Practical Advice for XAI Researcher
Sep 27, 2020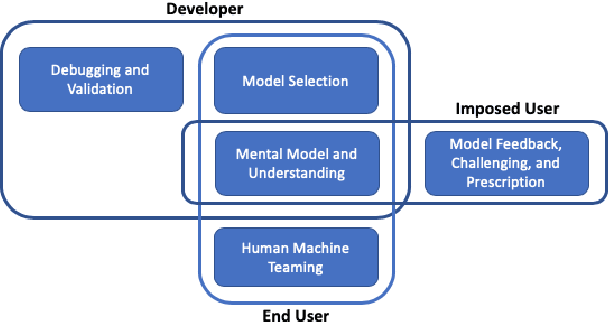
Research into the explanation of machine learning models, i.e., explainable AI (XAI), has seen a commensurate exponential growth alongside deep artificial neural networks throughout the past decade. For historical reasons, explanation and trust have been intertwined. However, the focus on trust is too narrow, and has led the research community astray from tried and true empirical methods that produced more defensible scientific knowledge about people and explanations. To address this, we contribute a practical path forward for researchers in the XAI field. We recommend researchers focus on the utility of machine learning explanations instead of trust. We outline five broad use cases where explanations are useful and, for each, we describe pseudo-experiments that rely on objective empirical measurements and falsifiable hypotheses. We believe that this experimental rigor is necessary to contribute to scientific knowledge in the field of XAI.
Adjusting for Confounders with Text: Challenges and an Empirical Evaluation Framework for Causal Inference
Sep 21, 2020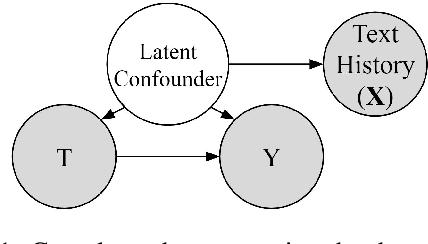
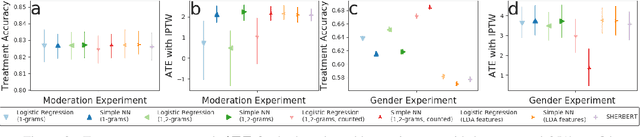
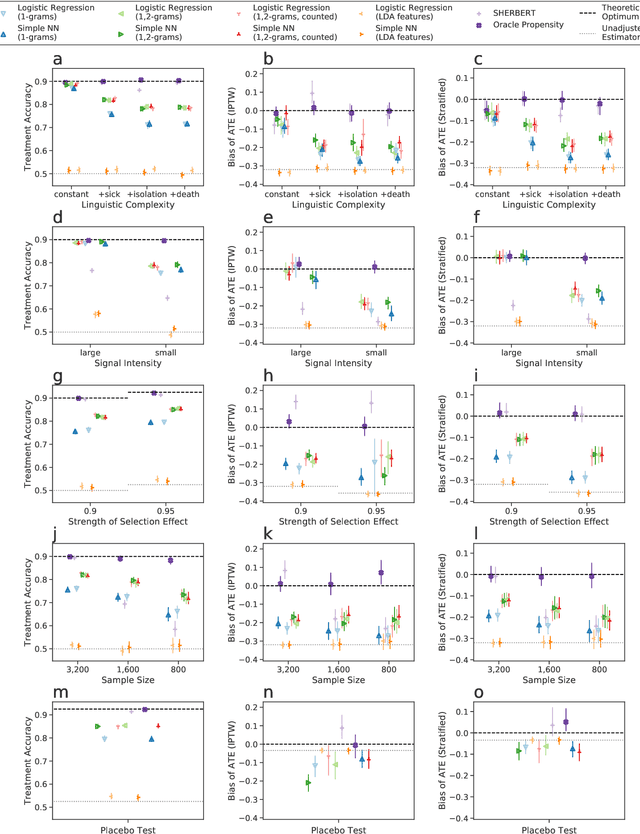
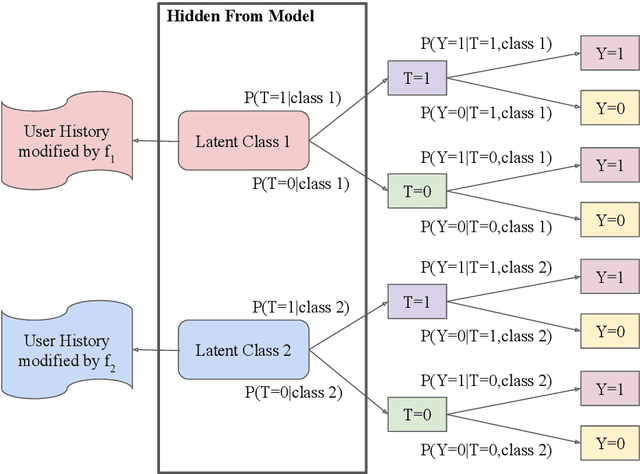
Leveraging text, such as social media posts, for causal inferences requires the use of NLP models to 'learn' and adjust for confounders, which could otherwise impart bias. However, evaluating such models is challenging, as ground truth is almost never available. We demonstrate the need for empirical evaluation frameworks for causal inference in natural language by showing that existing, commonly used models regularly disagree with one another on real world tasks. We contribute the first such framework, generalizing several challenges across these real world tasks. Using this framework, we evaluate a large set of commonly used causal inference models based on propensity scores and identify their strengths and weaknesses to inform future improvements. We make all tasks, data, and models public to inform applications and encourage additional research.
Improved Forecasting of Cryptocurrency Price using Social Signals
Jul 01, 2019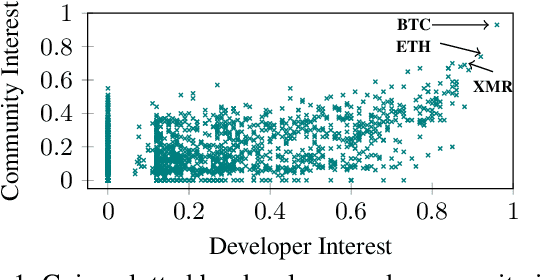
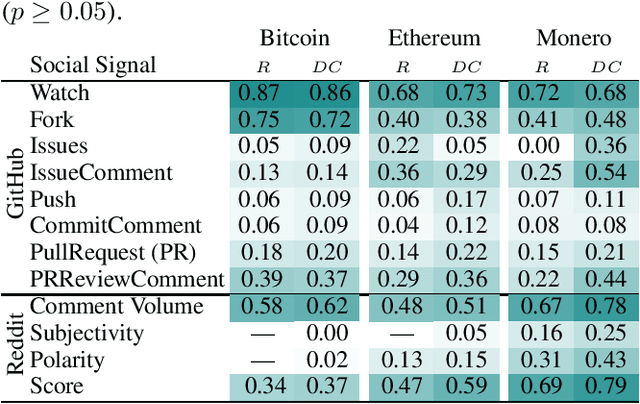
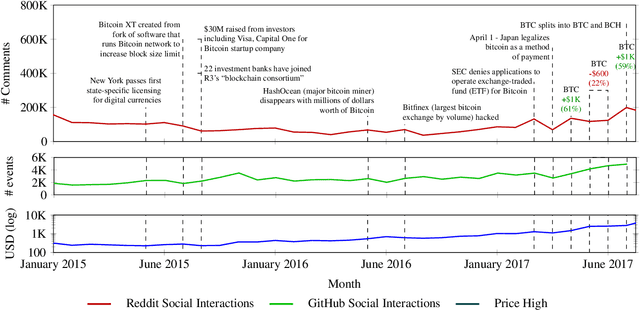
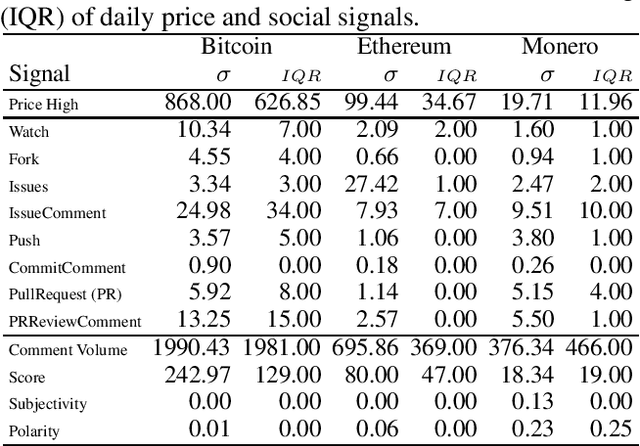
Social media signals have been successfully used to develop large-scale predictive and anticipatory analytics. For example, forecasting stock market prices and influenza outbreaks. Recently, social data has been explored to forecast price fluctuations of cryptocurrencies, which are a novel disruptive technology with significant political and economic implications. In this paper we leverage and contrast the predictive power of social signals, specifically user behavior and communication patterns, from multiple social platforms GitHub and Reddit to forecast prices for three cyptocurrencies with high developer and community interest - Bitcoin, Ethereum, and Monero. We evaluate the performance of neural network models that rely on long short-term memory units (LSTMs) trained on historical price data and social data against price only LSTMs and baseline autoregressive integrated moving average (ARIMA) models, commonly used to predict stock prices. Our results not only demonstrate that social signals reduce error when forecasting daily coin price, but also show that the language used in comments within the official communities on Reddit (r/Bitcoin, r/Ethereum, and r/Monero) are the best predictors overall. We observe that models are more accurate in forecasting price one day ahead for Bitcoin (4% root mean squared percent error) compared to Ethereum (7%) and Monero (8%).
Identifying and Understanding User Reactions to Deceptive and Trusted Social News Sources
May 30, 2018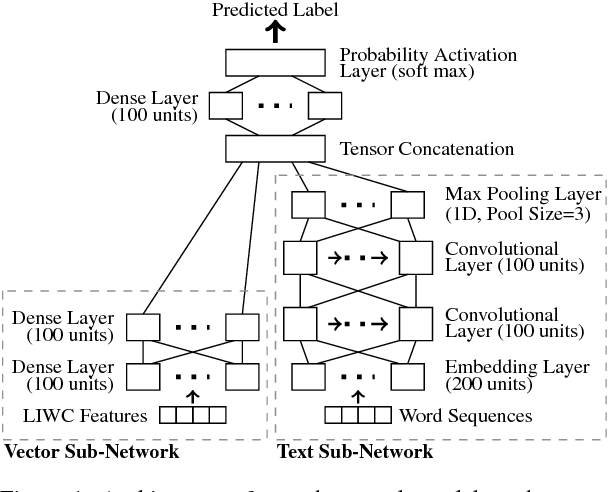
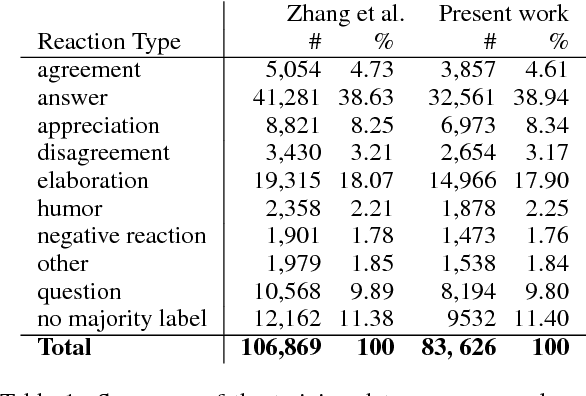
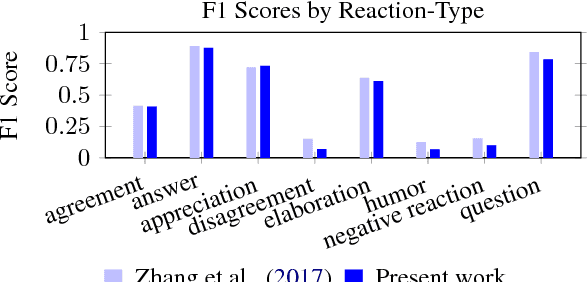
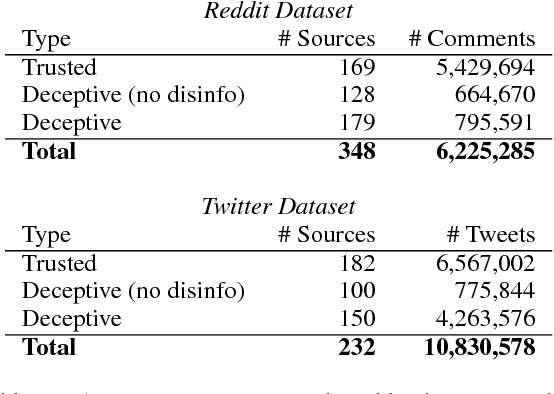
In the age of social news, it is important to understand the types of reactions that are evoked from news sources with various levels of credibility. In the present work we seek to better understand how users react to trusted and deceptive news sources across two popular, and very different, social media platforms. To that end, (1) we develop a model to classify user reactions into one of nine types, such as answer, elaboration, and question, etc, and (2) we measure the speed and the type of reaction for trusted and deceptive news sources for 10.8M Twitter posts and 6.2M Reddit comments. We show that there are significant differences in the speed and the type of reactions between trusted and deceptive news sources on Twitter, but far smaller differences on Reddit.