 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Promise for Assurance of Differentiable Neurosymbolic Reasoning Paradigms
Feb 13, 2025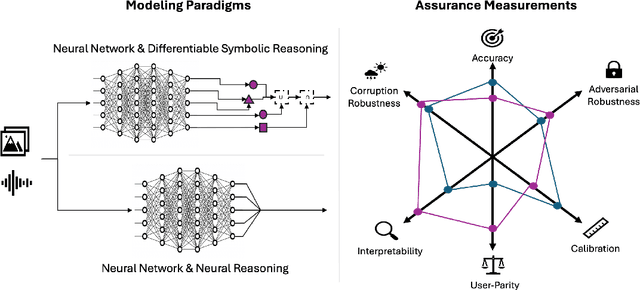
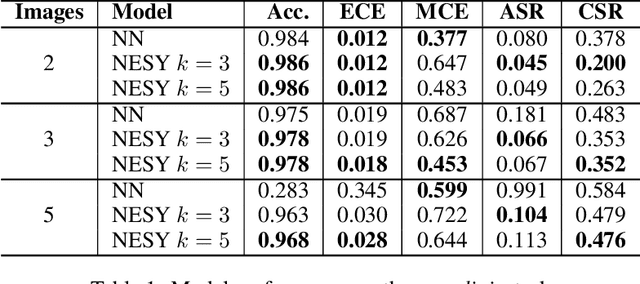
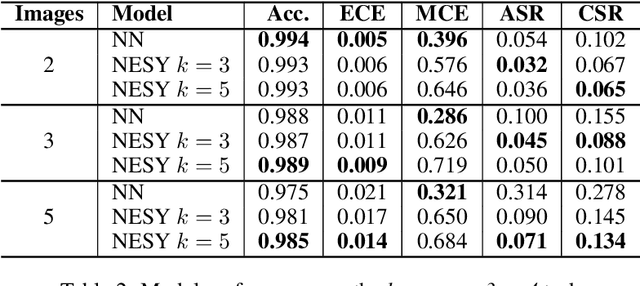
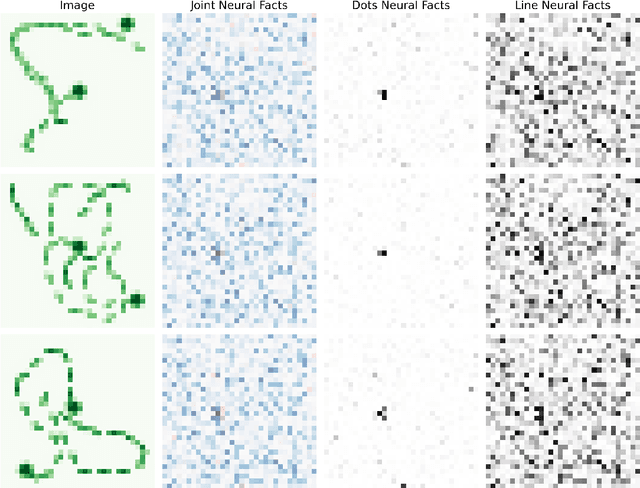
To create usable and deployable Artificial Intelligence (AI) systems, there requires a level of assurance in performance under many different conditions. Many times, deployed machine learning systems will require more classic logic and reasoning performed through neurosymbolic programs jointly with artificial neural network sensing. While many prior works have examined the assurance of a single component of the system solely with either the neural network alone or entire enterprise systems, very few works have examined the assurance of integrated neurosymbolic systems. Within this work, we assess the assurance of end-to-end fully differentiable neurosymbolic systems that are an emerging method to create data-efficient and more interpretable models. We perform this investigation using Scallop, an end-to-end neurosymbolic library, across classification and reasoning tasks in both the image and audio domains. We assess assurance across adversarial robustness, calibration, user performance parity, and interpretability of solutions for catching misaligned solutions. We find end-to-end neurosymbolic methods present unique opportunities for assurance beyond their data efficiency through our empirical results but not across the board. We find that this class of neurosymbolic models has higher assurance in cases where arithmetic operations are defined and where there is high dimensionality to the input space, where fully neural counterparts struggle to learn robust reasoning operations. We identify the relationship between neurosymbolic models' interpretability to catch shortcuts that later result in increased adversarial vulnerability despite performance parity. Finally, we find that the promise of data efficiency is typically only in the case of class imbalanced reasoning problems.
Exploring the Benefits of Domain-Pretraining of Generative Large Language Models for Chemistry
Nov 05, 2024
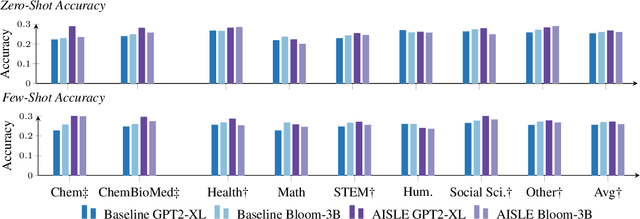
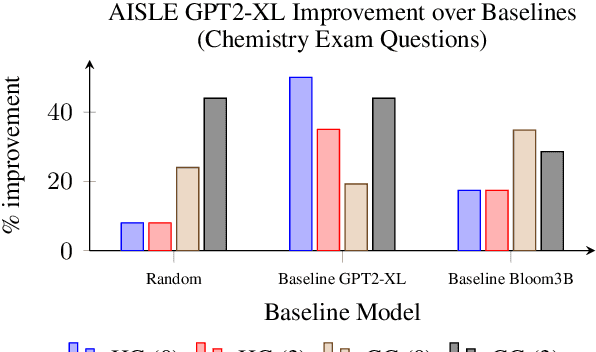
A proliferation of Large Language Models (the GPT series, BLOOM, LLaMA, and more) are driving forward novel development of multipurpose AI for a variety of tasks, particularly natural language processing (NLP) tasks. These models demonstrate strong performance on a range of tasks; however, there has been evidence of brittleness when applied to more niche or narrow domains where hallucinations or fluent but incorrect responses reduce performance. Given the complex nature of scientific domains, it is prudent to investigate the trade-offs of leveraging off-the-shelf versus more targeted foundation models for scientific domains. In this work, we examine the benefits of in-domain pre-training for a given scientific domain, chemistry, and compare these to open-source, off-the-shelf models with zero-shot and few-shot prompting. Our results show that not only do in-domain base models perform reasonably well on in-domain tasks in a zero-shot setting but that further adaptation using instruction fine-tuning yields impressive performance on chemistry-specific tasks such as named entity recognition and molecular formula generation.
Anticipating Technical Expertise and Capability Evolution in Research Communities using Dynamic Graph Transformers
Jul 18, 2023The ability to anticipate technical expertise and capability evolution trends globally is essential for national and global security, especially in safety-critical domains like nuclear nonproliferation (NN) and rapidly emerging fields like artificial intelligence (AI). In this work, we extend traditional statistical relational learning approaches (e.g., link prediction in collaboration networks) and formulate a problem of anticipating technical expertise and capability evolution using dynamic heterogeneous graph representations. We develop novel capabilities to forecast collaboration patterns, authorship behavior, and technical capability evolution at different granularities (e.g., scientist and institution levels) in two distinct research fields. We implement a dynamic graph transformer (DGT) neural architecture, which pushes the state-of-the-art graph neural network models by (a) forecasting heterogeneous (rather than homogeneous) nodes and edges, and (b) relying on both discrete -- and continuous -- time inputs. We demonstrate that our DGT models predict collaboration, partnership, and expertise patterns with 0.26, 0.73, and 0.53 mean reciprocal rank values for AI and 0.48, 0.93, and 0.22 for NN domains. DGT model performance exceeds the best-performing static graph baseline models by 30-80% across AI and NN domains. Our findings demonstrate that DGT models boost inductive task performance, when previously unseen nodes appear in the test data, for the domains with emerging collaboration patterns (e.g., AI). Specifically, models accurately predict which established scientists will collaborate with early career scientists and vice-versa in the AI domain.
EXPERT: Public Benchmarks for Dynamic Heterogeneous Academic Graphs
Apr 14, 2022
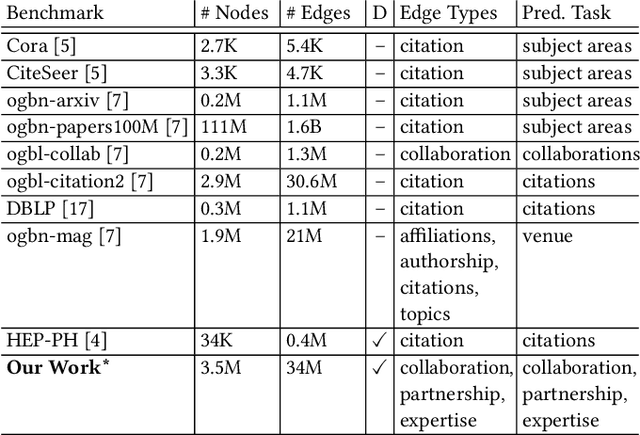

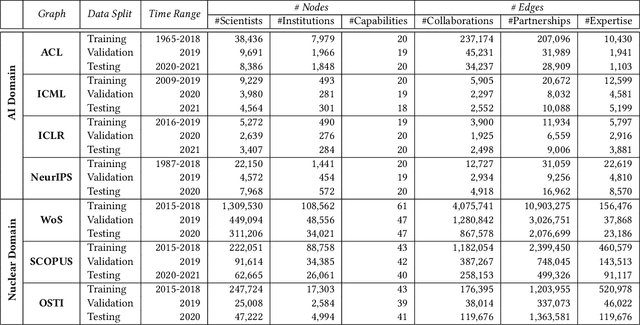
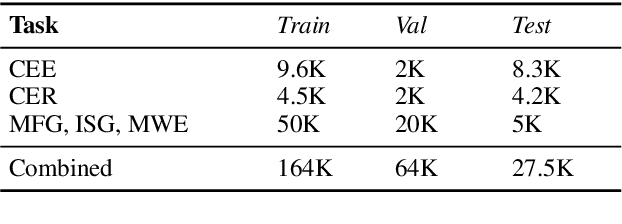
Machine learning models that learn from dynamic graphs face nontrivial challenges in learning and inference as both nodes and edges change over time. The existing large-scale graph benchmark datasets that are widely used by the community primarily focus on homogeneous node and edge attributes and are static. In this work, we present a variety of large scale, dynamic heterogeneous academic graphs to test the effectiveness of models developed for multi-step graph forecasting tasks. Our novel datasets cover both context and content information extracted from scientific publications across two communities: Artificial Intelligence (AI) and Nuclear Nonproliferation (NN). In addition, we propose a systematic approach to improve the existing evaluation procedures used in the graph forecasting models.
Towards Trustworthy Deception Detection: Benchmarking Model Robustness across Domains, Modalities, and Languages
Apr 23, 2021

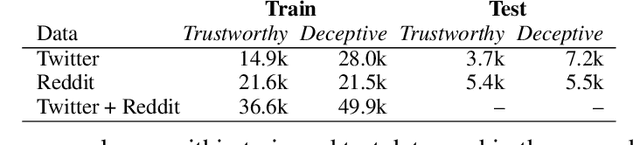
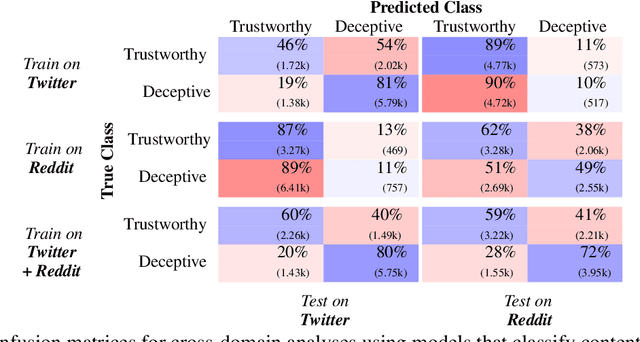
Evaluating model robustness is critical when developing trustworthy models not only to gain deeper understanding of model behavior, strengths, and weaknesses, but also to develop future models that are generalizable and robust across expected environments a model may encounter in deployment. In this paper we present a framework for measuring model robustness for an important but difficult text classification task - deceptive news detection. We evaluate model robustness to out-of-domain data, modality-specific features, and languages other than English. Our investigation focuses on three type of models: LSTM models trained on multiple datasets(Cross-Domain), several fusion LSTM models trained with images and text and evaluated with three state-of-the-art embeddings, BERT ELMo, and GloVe (Cross-Modality), and character-level CNN models trained on multiple languages (Cross-Language). Our analyses reveal a significant drop in performance when testing neural models on out-of-domain data and non-English languages that may be mitigated using diverse training data. We find that with additional image content as input, ELMo embeddings yield significantly fewer errors compared to BERT orGLoVe. Most importantly, this work not only carefully analyzes deception model robustness but also provides a framework of these analyses that can be applied to new models or extended datasets in the future.
Evaluating Deception Detection Model Robustness To Linguistic Variation
Apr 23, 2021
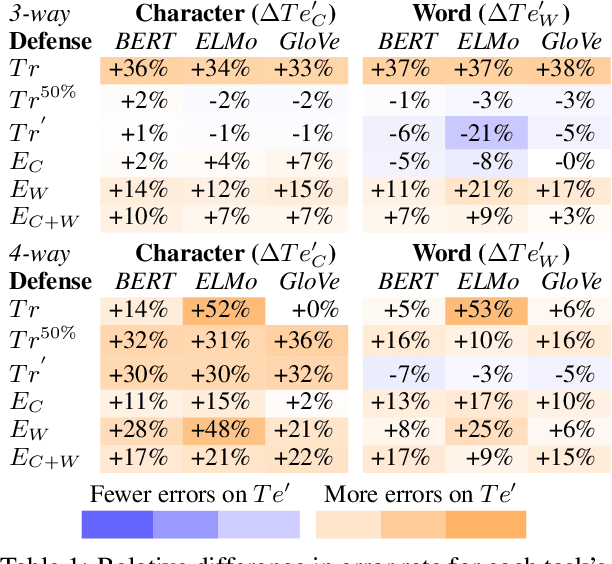

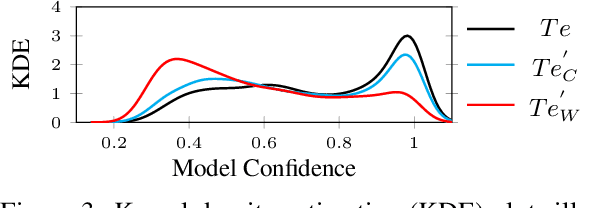
With the increasing use of machine-learning driven algorithmic judgements, it is critical to develop models that are robust to evolving or manipulated inputs. We propose an extensive analysis of model robustness against linguistic variation in the setting of deceptive news detection, an important task in the context of misinformation spread online. We consider two prediction tasks and compare three state-of-the-art embeddings to highlight consistent trends in model performance, high confidence misclassifications, and high impact failures. By measuring the effectiveness of adversarial defense strategies and evaluating model susceptibility to adversarial attacks using character- and word-perturbed text, we find that character or mixed ensemble models are the most effective defenses and that character perturbation-based attack tactics are more successful.