 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Benefits of Domain-Pretraining of Generative Large Language Models for Chemistry
Nov 05, 2024
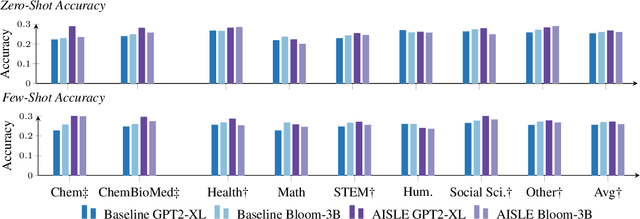
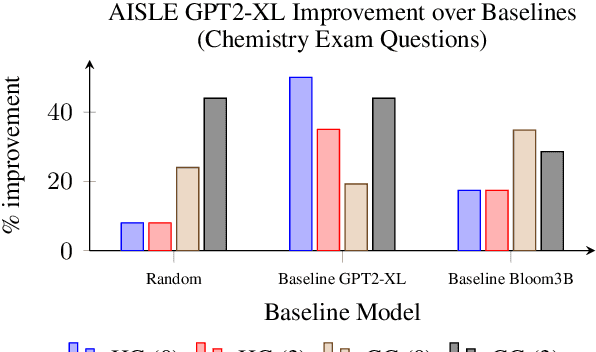
A proliferation of Large Language Models (the GPT series, BLOOM, LLaMA, and more) are driving forward novel development of multipurpose AI for a variety of tasks, particularly natural language processing (NLP) tasks. These models demonstrate strong performance on a range of tasks; however, there has been evidence of brittleness when applied to more niche or narrow domains where hallucinations or fluent but incorrect responses reduce performance. Given the complex nature of scientific domains, it is prudent to investigate the trade-offs of leveraging off-the-shelf versus more targeted foundation models for scientific domains. In this work, we examine the benefits of in-domain pre-training for a given scientific domain, chemistry, and compare these to open-source, off-the-shelf models with zero-shot and few-shot prompting. Our results show that not only do in-domain base models perform reasonably well on in-domain tasks in a zero-shot setting but that further adaptation using instruction fine-tuning yields impressive performance on chemistry-specific tasks such as named entity recognition and molecular formula generation.
TopTemp: Parsing Precipitate Structure from Temper Topology
Apr 01, 2022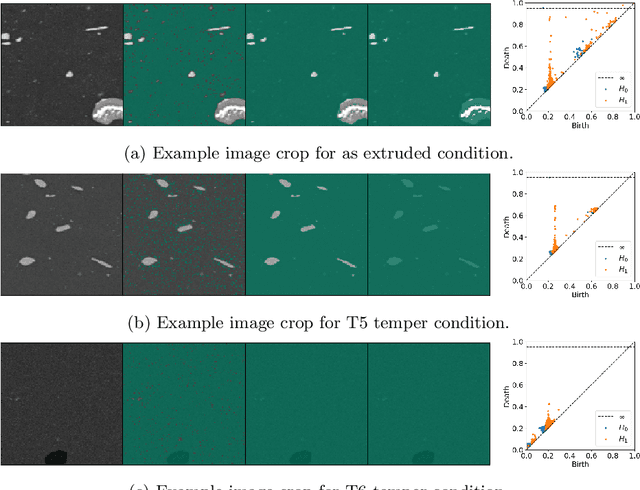
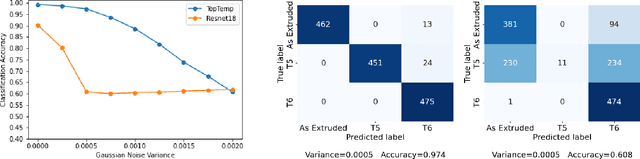

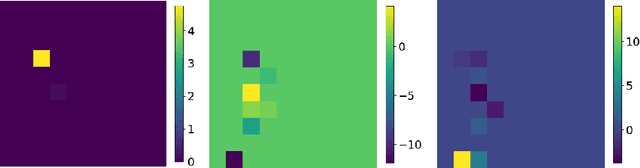
Technological advances are in part enabled by the development of novel manufacturing processes that give rise to new materials or material property improvements. Development and evaluation of new manufacturing methodologies is labor-, time-, and resource-intensive expensive due to complex, poorly defined relationships between advanced manufacturing process parameters and the resulting microstructures. In this work, we present a topological representation of temper (heat-treatment) dependent material micro-structure, as captured by scanning electron microscopy, called TopTemp. We show that this topological representation is able to support temper classification of microstructures in a data limited setting, generalizes well to previously unseen samples, is robust to image perturbations, and captures domain interpretable features. The presented work outperforms conventional deep learning baselines and is a first step towards improving understanding of process parameters and resulting material properties.
Recursive Decoding: A Situated Cognition Approach to Compositional Generation in Grounded Language Understanding
Jan 27, 2022



Compositional generalization is a troubling blind spot for neural language models. Recent efforts have presented techniques for improving a model's ability to encode novel combinations of known inputs, but less work has focused on generating novel combinations of known outputs. Here we focus on this latter "decode-side" form of generalization in the context of gSCAN, a synthetic benchmark for compositional generalization in grounded language understanding. We present Recursive Decoding (RD), a novel procedure for training and using seq2seq models, targeted towards decode-side generalization. Rather than generating an entire output sequence in one pass, models are trained to predict one token at a time. Inputs (i.e., the external gSCAN environment) are then incrementally updated based on predicted tokens, and re-encoded for the next decoder time step. RD thus decomposes a complex, out-of-distribution sequence generation task into a series of incremental predictions that each resemble what the model has already seen during training. RD yields dramatic improvement on two previously neglected generalization tasks in gSCAN. We provide analyses to elucidate these gains over failure of a baseline, and then discuss implications for generalization in naturalistic grounded language understanding, and seq2seq more generally.
Adaptive Transfer Learning: a simple but effective transfer learning
Nov 22, 2021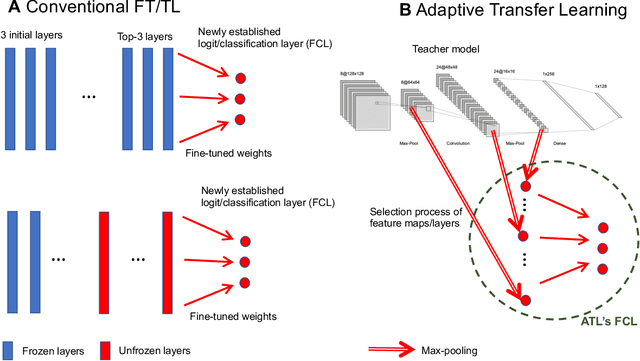
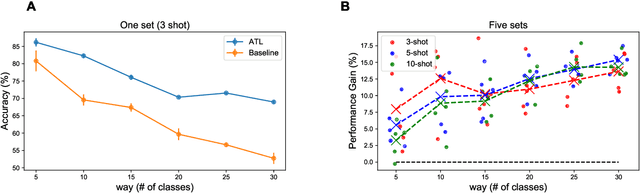
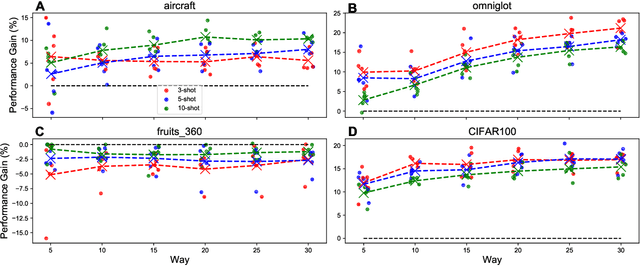
Transfer learning (TL) leverages previously obtained knowledge to learn new tasks efficiently and has been used to train deep learning (DL) models with limited amount of data. When TL is applied to DL, pretrained (teacher) models are fine-tuned to build domain specific (student) models. This fine-tuning relies on the fact that DL model can be decomposed to classifiers and feature extractors, and a line of studies showed that the same feature extractors can be used to train classifiers on multiple tasks. Furthermore, recent studies proposed multiple algorithms that can fine-tune teacher models' feature extractors to train student models more efficiently. We note that regardless of the fine-tuning of feature extractors, the classifiers of student models are trained with final outputs of feature extractors (i.e., the outputs of penultimate layers). However, a recent study suggested that feature maps in ResNets across layers could be functionally equivalent, raising the possibility that feature maps inside the feature extractors can also be used to train student models' classifiers. Inspired by this study, we tested if feature maps in the hidden layers of the teacher models can be used to improve the student models' accuracy (i.e., TL's efficiency). Specifically, we developed 'adaptive transfer learning (ATL)', which can choose an optimal set of feature maps for TL, and tested it in the few-shot learning setting. Our empirical evaluations suggest that ATL can help DL models learn more efficiently, especially when available examples are limited.
A Topological-Framework to Improve Analysis of Machine Learning Model Performance
Jul 09, 2021

As both machine learning models and the datasets on which they are evaluated have grown in size and complexity, the practice of using a few summary statistics to understand model performance has become increasingly problematic. This is particularly true in real-world scenarios where understanding model failure on certain subpopulations of the data is of critical importance. In this paper we propose a topological framework for evaluating machine learning models in which a dataset is treated as a "space" on which a model operates. This provides us with a principled way to organize information about model performance at both the global level (over the entire test set) and also the local level (on specific subpopulations). Finally, we describe a topological data structure, presheaves, which offer a convenient way to store and analyze model performance between different subpopulations.
One Representation to Rule Them All: Identifying Out-of-Support Examples in Few-shot Learning with Generic Representations
Jun 02, 2021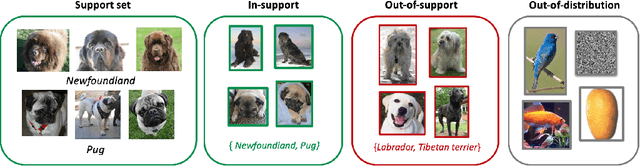
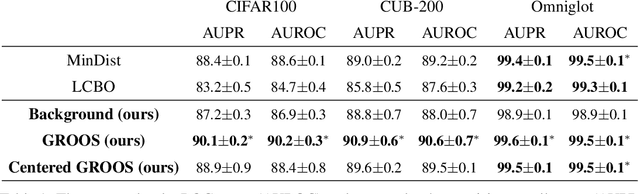
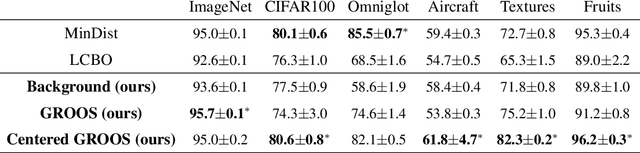
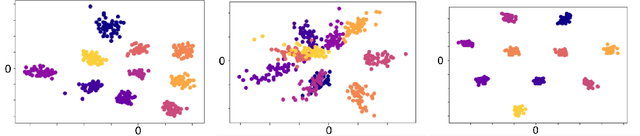
The field of few-shot learning has made remarkable strides in developing powerful models that can operate in the small data regime. Nearly all of these methods assume every unlabeled instance encountered will belong to a handful of known classes for which one has examples. This can be problematic for real-world use cases where one routinely finds 'none-of-the-above' examples. In this paper we describe this challenge of identifying what we term 'out-of-support' (OOS) examples. We describe how this problem is subtly different from out-of-distribution detection and describe a new method of identifying OOS examples within the Prototypical Networks framework using a fixed point which we call the generic representation. We show that our method outperforms other existing approaches in the literature as well as other approaches that we propose in this paper. Finally, we investigate how the use of such a generic point affects the geometry of a model's feature space.
Few-Shot Learning with Metric-Agnostic Conditional Embeddings
Feb 12, 2018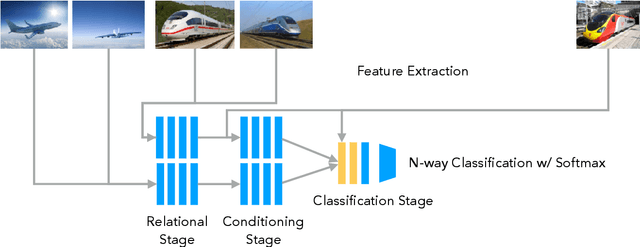
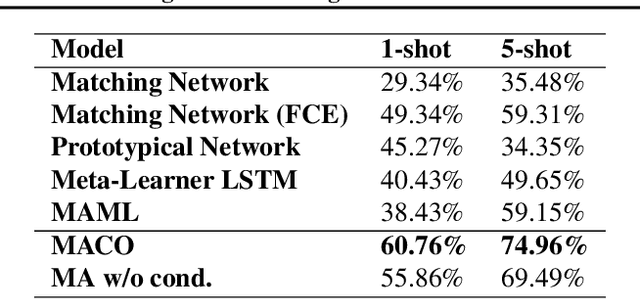
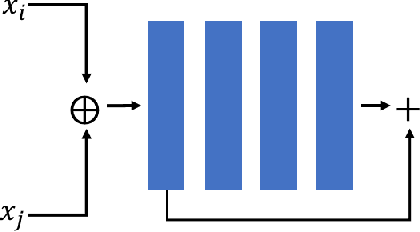
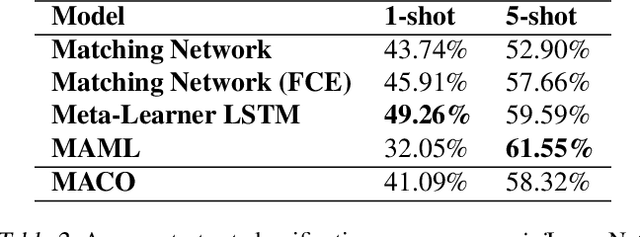
Learning high quality class representations from few examples is a key problem in metric-learning approaches to few-shot learning. To accomplish this, we introduce a novel architecture where class representations are conditioned for each few-shot trial based on a target image. We also deviate from traditional metric-learning approaches by training a network to perform comparisons between classes rather than relying on a static metric comparison. This allows the network to decide what aspects of each class are important for the comparison at hand. We find that this flexible architecture works well in practice, achieving state-of-the-art performance on the Caltech-UCSD birds fine-grained classification task.