 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Transfer Learning: a simple but effective transfer learning
Nov 22, 2021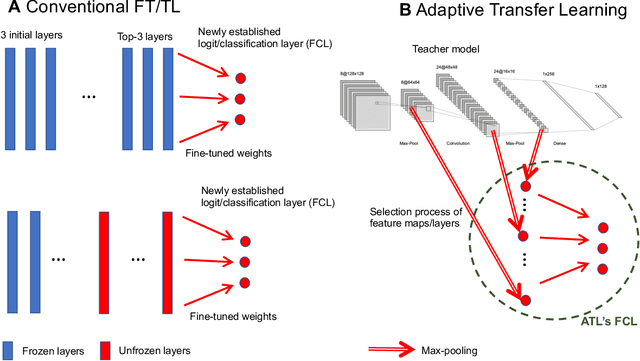
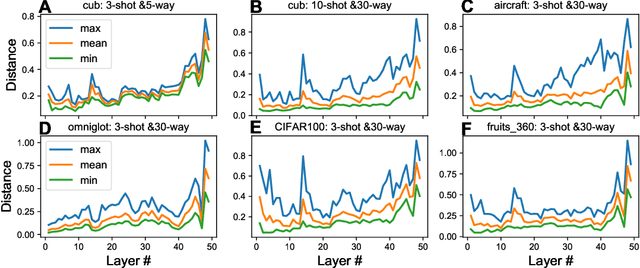
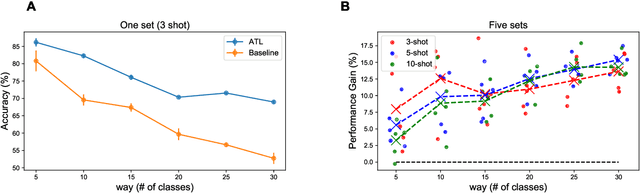
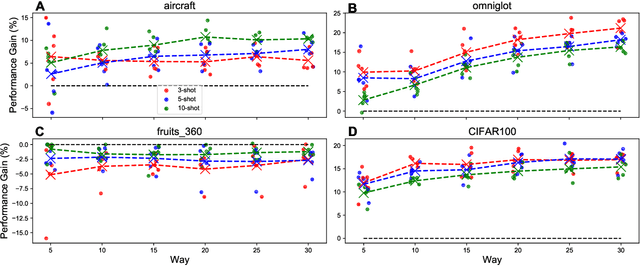
Transfer learning (TL) leverages previously obtained knowledge to learn new tasks efficiently and has been used to train deep learning (DL) models with limited amount of data. When TL is applied to DL, pretrained (teacher) models are fine-tuned to build domain specific (student) models. This fine-tuning relies on the fact that DL model can be decomposed to classifiers and feature extractors, and a line of studies showed that the same feature extractors can be used to train classifiers on multiple tasks. Furthermore, recent studies proposed multiple algorithms that can fine-tune teacher models' feature extractors to train student models more efficiently. We note that regardless of the fine-tuning of feature extractors, the classifiers of student models are trained with final outputs of feature extractors (i.e., the outputs of penultimate layers). However, a recent study suggested that feature maps in ResNets across layers could be functionally equivalent, raising the possibility that feature maps inside the feature extractors can also be used to train student models' classifiers. Inspired by this study, we tested if feature maps in the hidden layers of the teacher models can be used to improve the student models' accuracy (i.e., TL's efficiency). Specifically, we developed 'adaptive transfer learning (ATL)', which can choose an optimal set of feature maps for TL, and tested it in the few-shot learning setting. Our empirical evaluations suggest that ATL can help DL models learn more efficiently, especially when available examples are limited.
One Representation to Rule Them All: Identifying Out-of-Support Examples in Few-shot Learning with Generic Representations
Jun 02, 2021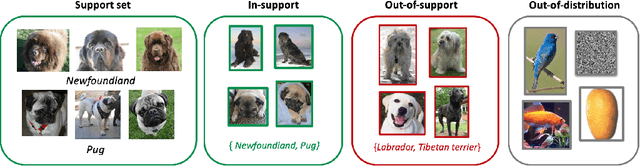
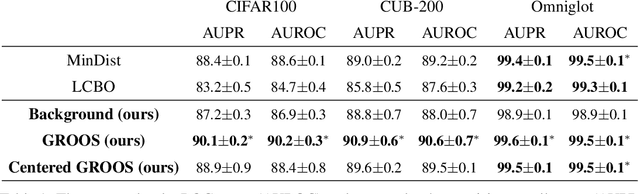
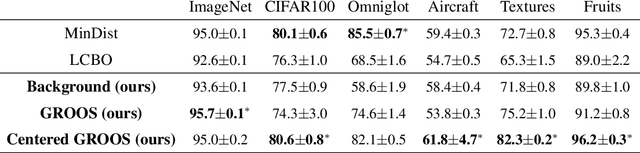
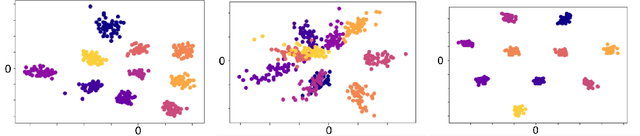
The field of few-shot learning has made remarkable strides in developing powerful models that can operate in the small data regime. Nearly all of these methods assume every unlabeled instance encountered will belong to a handful of known classes for which one has examples. This can be problematic for real-world use cases where one routinely finds 'none-of-the-above' examples. In this paper we describe this challenge of identifying what we term 'out-of-support' (OOS) examples. We describe how this problem is subtly different from out-of-distribution detection and describe a new method of identifying OOS examples within the Prototypical Networks framework using a fixed point which we call the generic representation. We show that our method outperforms other existing approaches in the literature as well as other approaches that we propose in this paper. Finally, we investigate how the use of such a generic point affects the geometry of a model's feature space.
Fuzzy Simplicial Networks: A Topology-Inspired Model to Improve Task Generalization in Few-shot Learning
Sep 23, 2020


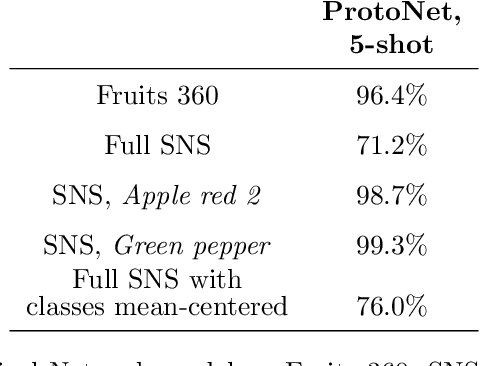
Deep learning has shown great success in settings with massive amounts of data but has struggled when data is limited. Few-shot learning algorithms, which seek to address this limitation, are designed to generalize well to new tasks with limited data. Typically, models are evaluated on unseen classes and datasets that are defined by the same fundamental task as they are trained for (e.g. category membership). One can also ask how well a model can generalize to fundamentally different tasks within a fixed dataset (for example: moving from category membership to tasks that involve detecting object orientation or quantity). To formalize this kind of shift we define a notion of "independence of tasks" and identify three new sets of labels for established computer vision datasets that test a model's ability to generalize to tasks which draw on orthogonal attributes in the data. We use these datasets to investigate the failure modes of metric-based few-shot models. Based on our findings, we introduce a new few-shot model called Fuzzy Simplicial Networks (FSN) which leverages a construction from topology to more flexibly represent each class from limited data. In particular, FSN models can not only form multiple representations for a given class but can also begin to capture the low-dimensional structure which characterizes class manifolds in the encoded space of deep networks. We show that FSN outperforms state-of-the-art models on the challenging tasks we introduce in this paper while remaining competitive on standard few-shot benchmarks.
The Outer Product Structure of Neural Network Derivatives
Oct 09, 2018In this paper, we show that feedforward and recurrent neural networks exhibit an outer product derivative structure but that convolutional neural networks do not. This structure makes it possible to use higher-order information without needing approximations or infeasibly large amounts of memory, and it may also provide insights into the geometry of neural network optima. The ability to easily access these derivatives also suggests a new, geometric approach to regularization. We then discuss how this structure could be used to improve training methods, increase network robustness and generalizability, and inform network compression methods.
Doing the impossible: Why neural networks can be trained at all
May 28, 2018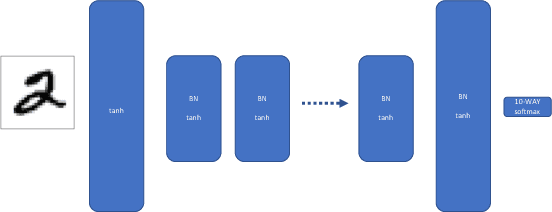
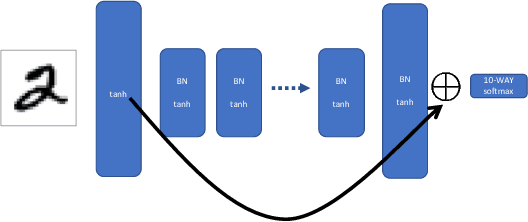
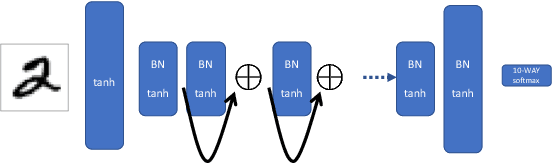
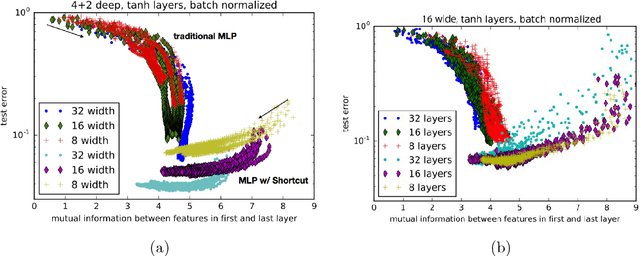
As deep neural networks grow in size, from thousands to millions to billions of weights, the performance of those networks becomes limited by our ability to accurately train them. A common naive question arises: if we have a system with billions of degrees of freedom, don't we also need billions of samples to train it? Of course, the success of deep learning indicates that reliable models can be learned with reasonable amounts of data. Similar questions arise in protein folding, spin glasses and biological neural networks. With effectively infinite potential folding/spin/wiring configurations, how does the system find the precise arrangement that leads to useful and robust results? Simple sampling of the possible configurations until an optimal one is reached is not a viable option even if one waited for the age of the universe. On the contrary, there appears to be a mechanism in the above phenomena that forces them to achieve configurations that live on a low-dimensional manifold, avoiding the curse of dimensionality. In the current work we use the concept of mutual information between successive layers of a deep neural network to elucidate this mechanism and suggest possible ways of exploiting it to accelerate training. We show that adding structure to the neural network that enforces higher mutual information between layers speeds training and leads to more accurate results. High mutual information between layers implies that the effective number of free parameters is exponentially smaller than the raw number of tunable weights.
How Much Chemistry Does a Deep Neural Network Need to Know to Make Accurate Predictions?
Mar 18, 2018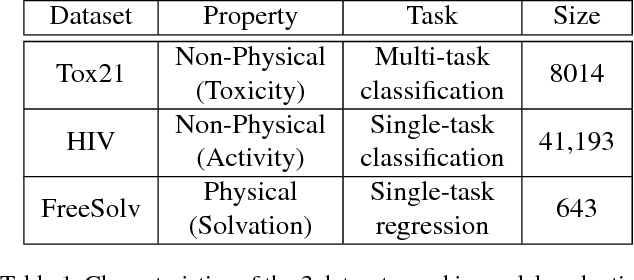
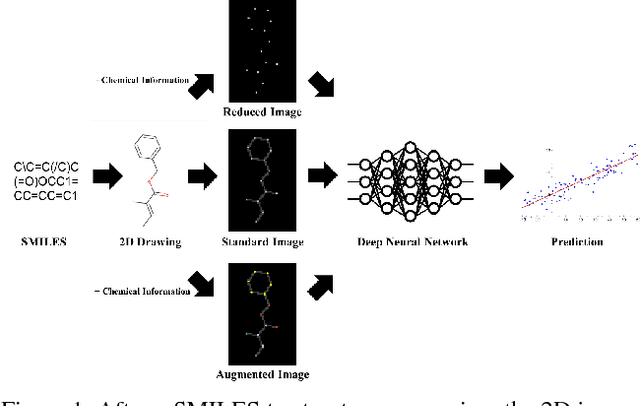
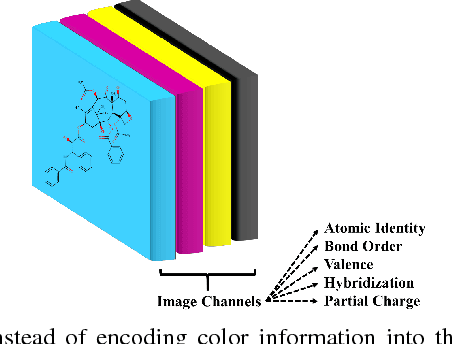
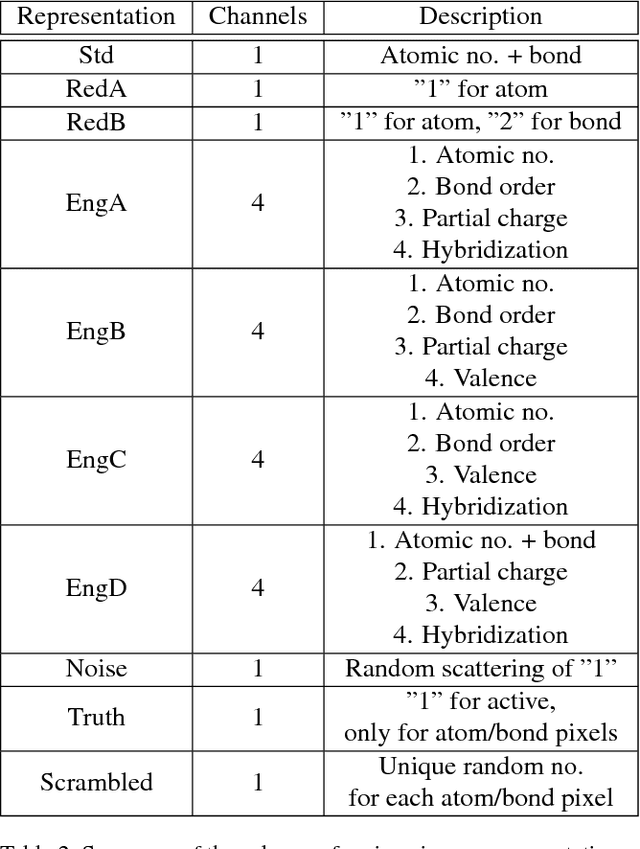
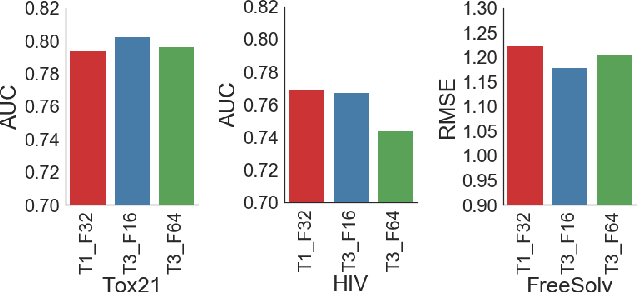
The meteoric rise of deep learning models in computer vision research, having achieved human-level accuracy in image recognition tasks is firm evidence of the impact of representation learning of deep neural networks. In the chemistry domain, recent advances have also led to the development of similar CNN models, such as Chemception, that is trained to predict chemical properties using images of molecular drawings. In this work, we investigate the effects of systematically removing and adding localized domain-specific information to the image channels of the training data. By augmenting images with only 3 additional basic information, and without introducing any architectural changes, we demonstrate that an augmented Chemception (AugChemception) outperforms the original model in the prediction of toxicity, activity, and solvation free energy. Then, by altering the information content in the images, and examining the resulting model's performance, we also identify two distinct learning patterns in predicting toxicity/activity as compared to solvation free energy. These patterns suggest that Chemception is learning about its tasks in the manner that is consistent with established knowledge. Thus, our work demonstrates that advanced chemical knowledge is not a pre-requisite for deep learning models to accurately predict complex chemical properties.
SMILES2Vec: An Interpretable General-Purpose Deep Neural Network for Predicting Chemical Properties
Mar 18, 2018
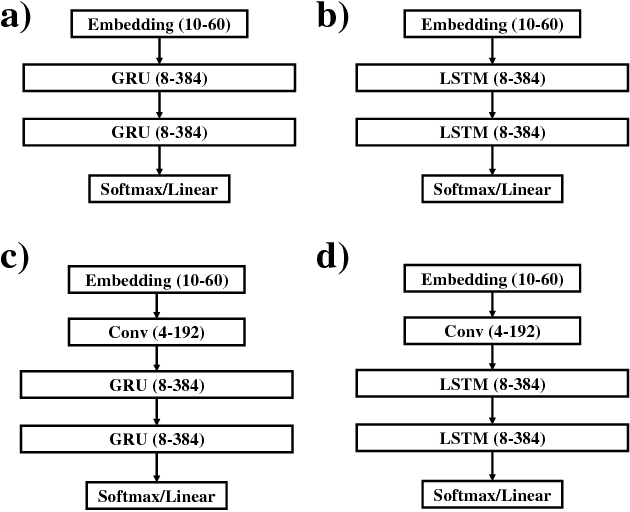
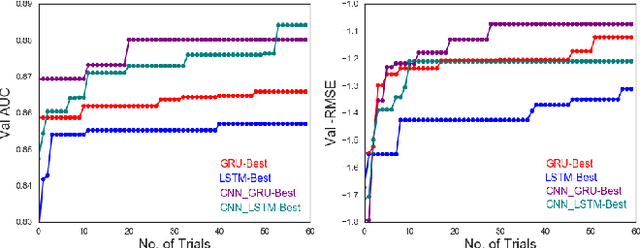
Chemical databases store information in text representations, and the SMILES format is a universal standard used in many cheminformatics software. Encoded in each SMILES string is structural information that can be used to predict complex chemical properties. In this work, we develop SMILES2vec, a deep RNN that automatically learns features from SMILES to predict chemical properties, without the need for additional explicit feature engineering. Using Bayesian optimization methods to tune the network architecture, we show that an optimized SMILES2vec model can serve as a general-purpose neural network for predicting distinct chemical properties including toxicity, activity, solubility and solvation energy, while also outperforming contemporary MLP neural networks that uses engineered features. Furthermore, we demonstrate proof-of-concept of interpretability by developing an explanation mask that localizes on the most important characters used in making a prediction. When tested on the solubility dataset, it identified specific parts of a chemical that is consistent with established first-principles knowledge with an accuracy of 88%. Our work demonstrates that neural networks can learn technically accurate chemical concept and provide state-of-the-art accuracy, making interpretable deep neural networks a useful tool of relevance to the chemical industry.
Using Rule-Based Labels for Weak Supervised Learning: A ChemNet for Transferable Chemical Property Prediction
Mar 18, 2018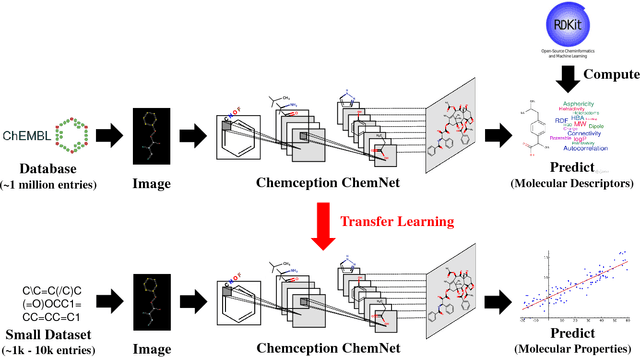
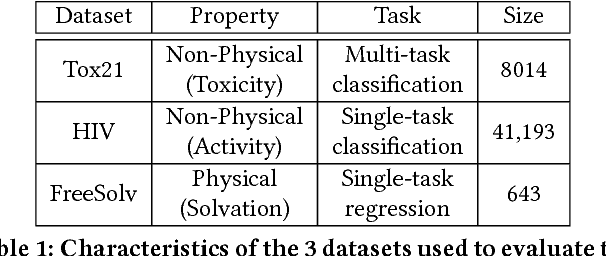
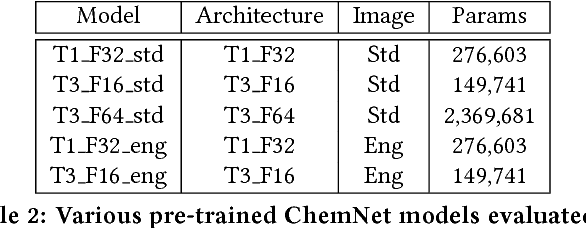
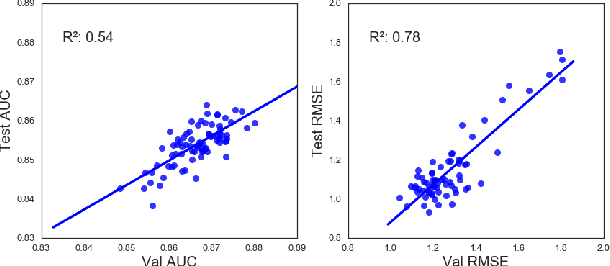
With access to large datasets, deep neural networks (DNN) have achieved human-level accuracy in image and speech recognition tasks. However, in chemistry, data is inherently small and fragmented. In this work, we develop an approach of using rule-based knowledge for training ChemNet, a transferable and generalizable deep neural network for chemical property prediction that learns in a weak-supervised manner from large unlabeled chemical databases. When coupled with transfer learning approaches to predict other smaller datasets for chemical properties that it was not originally trained on, we show that ChemNet's accuracy outperforms contemporary DNN models that were trained using conventional supervised learning. Furthermore, we demonstrate that the ChemNet pre-training approach is equally effective on both CNN (Chemception) and RNN (SMILES2vec) models, indicating that this approach is network architecture agnostic and is effective across multiple data modalities. Our results indicate a pre-trained ChemNet that incorporates chemistry domain knowledge, enables the development of generalizable neural networks for more accurate prediction of novel chemical properties.
Few-Shot Learning with Metric-Agnostic Conditional Embeddings
Feb 12, 2018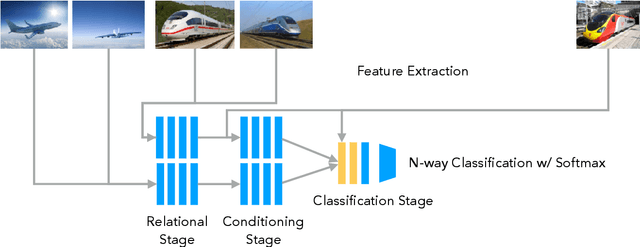
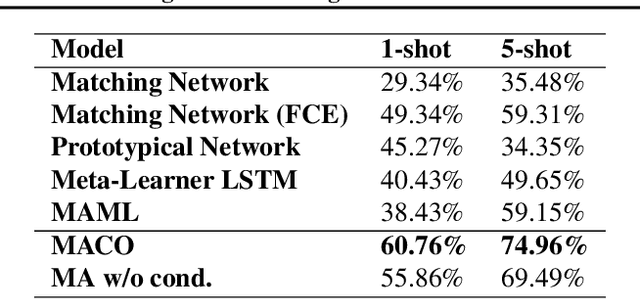
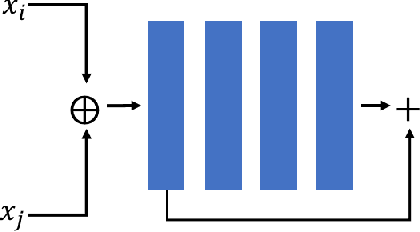
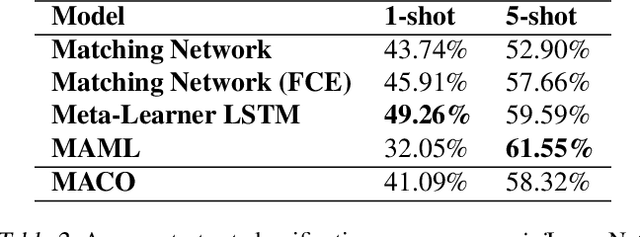
Learning high quality class representations from few examples is a key problem in metric-learning approaches to few-shot learning. To accomplish this, we introduce a novel architecture where class representations are conditioned for each few-shot trial based on a target image. We also deviate from traditional metric-learning approaches by training a network to perform comparisons between classes rather than relying on a static metric comparison. This allows the network to decide what aspects of each class are important for the comparison at hand. We find that this flexible architecture works well in practice, achieving state-of-the-art performance on the Caltech-UCSD birds fine-grained classification task.
Dynamic Input Structure and Network Assembly for Few-Shot Learning
Aug 22, 2017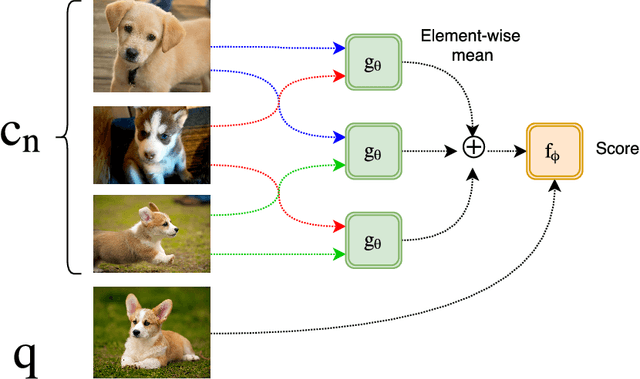
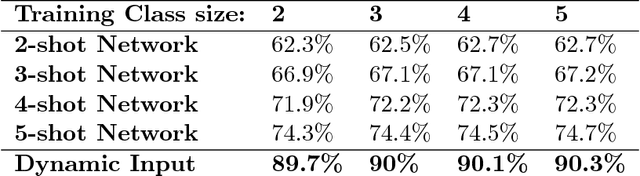
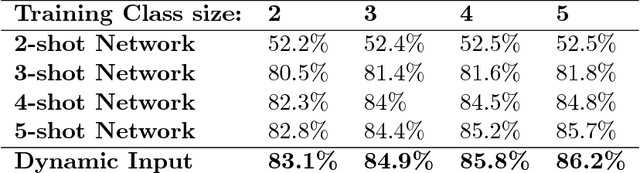
The ability to learn from a small number of examples has been a difficult problem in machine learning since its inception. While methods have succeeded with large amounts of training data, research has been underway in how to accomplish similar performance with fewer examples, known as one-shot or more generally few-shot learning. This technique has been shown to have promising performance, but in practice requires fixed-size inputs making it impractical for production systems where class sizes can vary. This impedes training and the final utility of few-shot learning systems. This paper describes an approach to constructing and training a network that can handle arbitrary example sizes dynamically as the system is used.