 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMechPert: Mechanistic Consensus as an Inductive Bias for Unseen Perturbation Prediction
Feb 14, 2026Predicting transcriptional responses to unseen genetic perturbations is essential for understanding gene regulation and prioritizing large-scale perturbation experiments. Existing approaches either rely on static, potentially incomplete knowledge graphs, or prompt language models for functionally similar genes, retrieving associations shaped by symmetric co-occurrence in scientific text rather than directed regulatory logic. We introduce MechPert, a lightweight framework that encourages LLM agents to generate directed regulatory hypotheses rather than relying solely on functional similarity. Multiple agents independently propose candidate regulators with associated confidence scores; these are aggregated through a consensus mechanism that filters spurious associations, producing weighted neighborhoods for downstream prediction. We evaluate MechPert on Perturb-seq benchmarks across four human cell lines. For perturbation prediction in low-data regimes ($N=50$ observed perturbations), MechPert improves Pearson correlation by up to 10.5\% over similarity-based baselines. For experimental design, MechPert-selected anchor genes outperform standard network centrality heuristics by up to 46\% in well-characterized cell lines.
Automating Forecasting Question Generation and Resolution for AI Evaluation
Jan 30, 2026Forecasting future events is highly valuable in decision-making and is a robust measure of general intelligence. As forecasting is probabilistic, developing and evaluating AI forecasters requires generating large numbers of diverse and difficult questions, and accurately resolving them. Previous efforts to automate this laborious work relied on recurring data sources (e.g., weather, stocks), limiting diversity and utility. In this work, we present a system for generating and resolving high-quality forecasting questions automatically and at scale using LLM-powered web research agents. We use this system to generate 1499 diverse, real-world forecasting questions, and to resolve them several months later. We estimate that our system produces verifiable, unambiguous questions approximately 96% of the time, exceeding the rate of Metaculus, a leading human-curated forecasting platform. We also find that our system resolves questions at approximately 95% accuracy. We verify that forecasting agents powered by more intelligent LLMs perform better on these questions (Brier score of 0.134 for Gemini 3 Pro, 0.149 for GPT-5, and 0.179 for Gemini 2.5 Flash). Finally, we demonstrate how our system can be leveraged to directly improve forecasting, by evaluating a question decomposition strategy on a generated question set, yielding a significant improvement in Brier scores (0.132 vs. 0.141).
Intrinsic uncertainties and where to find them
Jul 06, 2021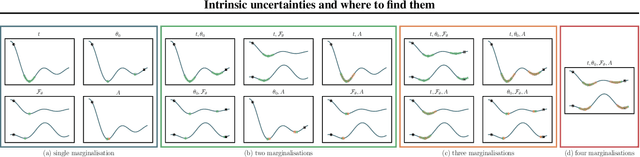

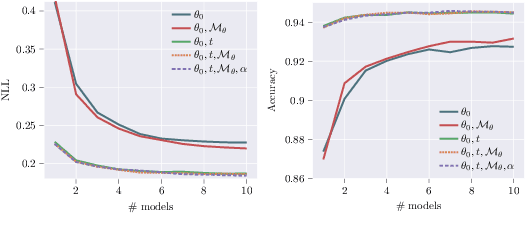
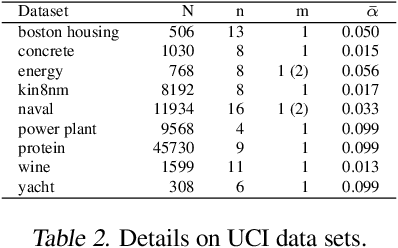
We introduce a framework for uncertainty estimation that both describes and extends many existing methods. We consider typical hyperparameters involved in classical training as random variables and marginalise them out to capture various sources of uncertainty in the parameter space. We investigate which forms and combinations of marginalisation are most useful from a practical point of view on standard benchmarking data sets. Moreover, we discuss how some marginalisations may produce reliable estimates of uncertainty without the need for extensive hyperparameter tuning and/or large-scale ensembling.
Explanatory Masks for Neural Network Interpretability
Nov 15, 2019


Neural network interpretability is a vital component for applications across a wide variety of domains. In such cases it is often useful to analyze a network which has already been trained for its specific purpose. In this work, we develop a method to produce explanation masks for pre-trained networks. The mask localizes the most important aspects of each input for prediction of the original network. Masks are created by a secondary network whose goal is to create as small an explanation as possible while still preserving the predictive accuracy of the original network. We demonstrate the applicability of our method for image classification with CNNs, sentiment analysis with RNNs, and chemical property prediction with mixed CNN/RNN architectures.
Metric-Based Few-Shot Learning for Video Action Recognition
Sep 14, 2019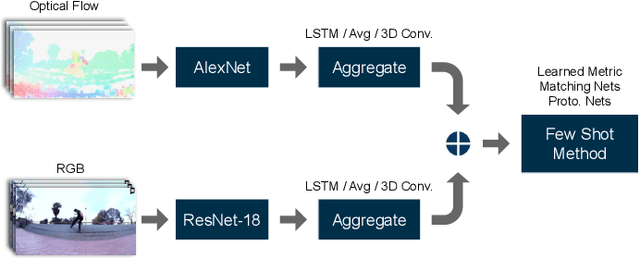
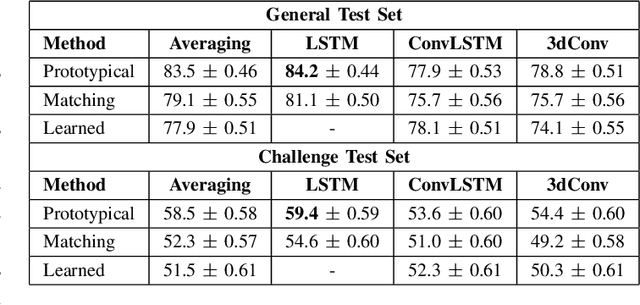
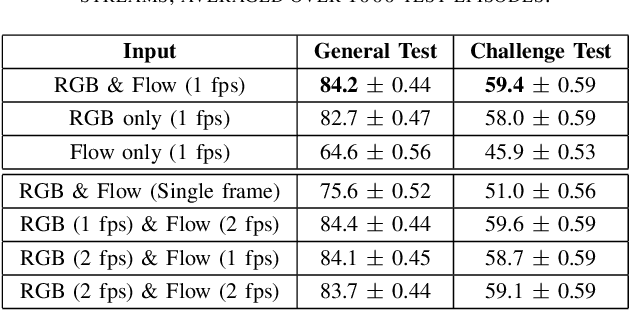
In the few-shot scenario, a learner must effectively generalize to unseen classes given a small support set of labeled examples. While a relatively large amount of research has gone into few-shot learning for image classification, little work has been done on few-shot video classification. In this work, we address the task of few-shot video action recognition with a set of two-stream models. We evaluate the performance of a set of convolutional and recurrent neural network video encoder architectures used in conjunction with three popular metric-based few-shot algorithms. We train and evaluate using a few-shot split of the Kinetics 600 dataset. Our experiments confirm the importance of the two-stream setup, and find prototypical networks and pooled long short-term memory network embeddings to give the best performance as few-shot method and video encoder, respectively. For a 5-shot 5-way task, this setup obtains 84.2% accuracy on the test set and 59.4% on a special "challenge" test set, composed of highly confusable classes.
Sparse hierarchical representation learning on molecular graphs
Aug 06, 2019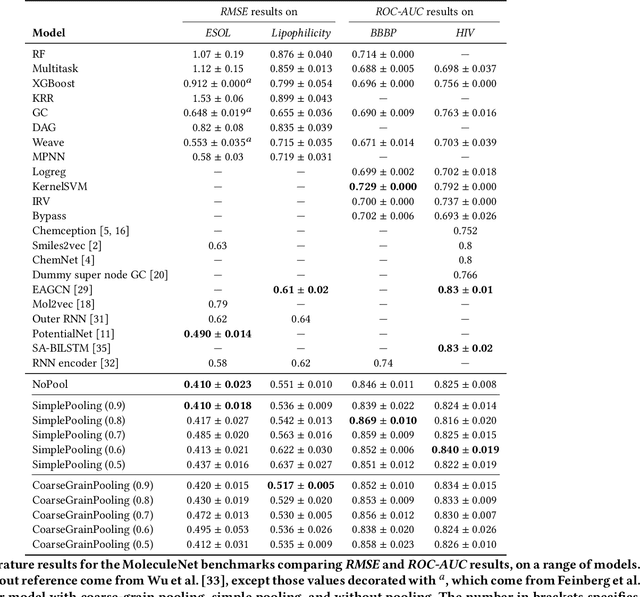
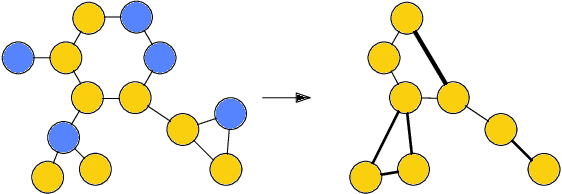

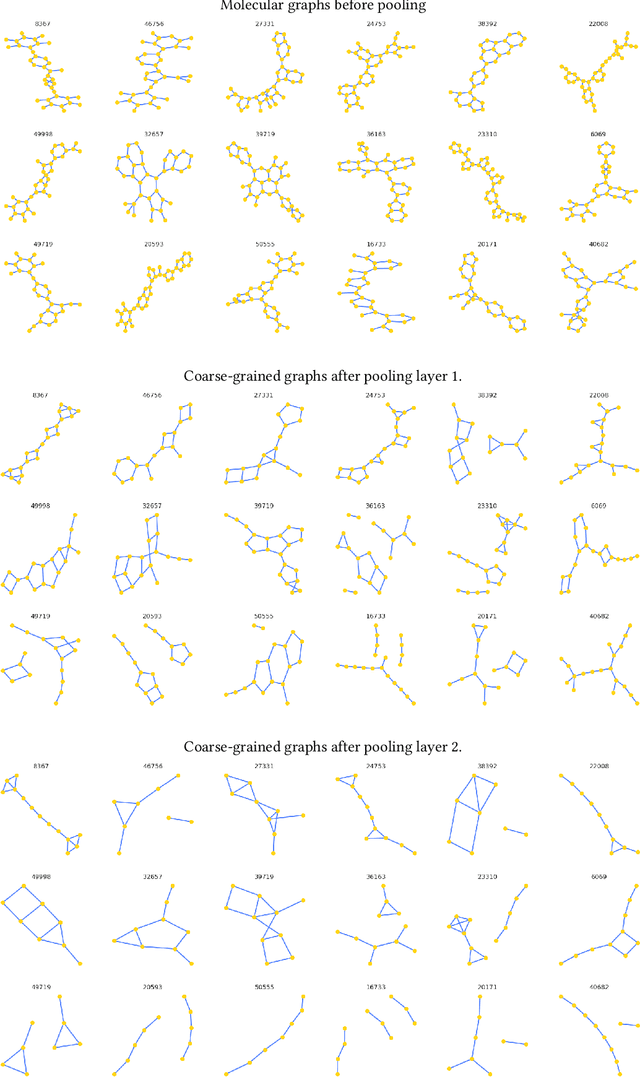
Architectures for sparse hierarchical representation learning have recently been proposed for graph-structured data, but so far assume the absence of edge features in the graph. We close this gap and propose a method to pool graphs with edge features, inspired by the hierarchical nature of chemistry. In particular, we introduce two types of pooling layers compatible with an edge-feature graph-convolutional architecture and investigate their performance for molecules relevant to drug discovery on a set of two classification and two regression benchmark datasets of MoleculeNet. We find that our models significantly outperform previous benchmarks on three of the datasets and reach state-of-the-art results on the fourth benchmark, with pooling improving performance for three out of four tasks, keeping performance stable on the fourth task, and generally speeding up the training process.
Few-Shot Learning with Metric-Agnostic Conditional Embeddings
Feb 12, 2018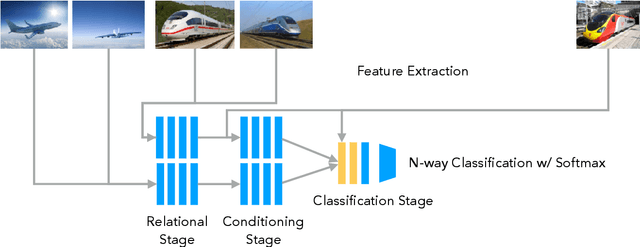
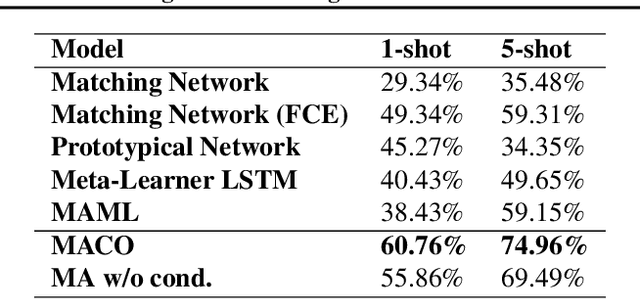
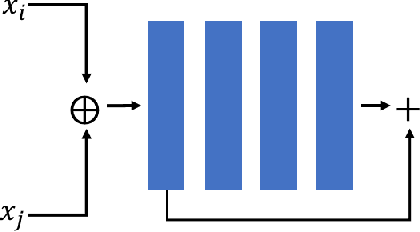
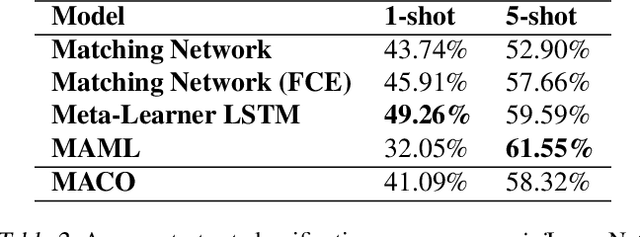
Learning high quality class representations from few examples is a key problem in metric-learning approaches to few-shot learning. To accomplish this, we introduce a novel architecture where class representations are conditioned for each few-shot trial based on a target image. We also deviate from traditional metric-learning approaches by training a network to perform comparisons between classes rather than relying on a static metric comparison. This allows the network to decide what aspects of each class are important for the comparison at hand. We find that this flexible architecture works well in practice, achieving state-of-the-art performance on the Caltech-UCSD birds fine-grained classification task.
Assessing the Linguistic Productivity of Unsupervised Deep Neural Networks
Jun 06, 2017
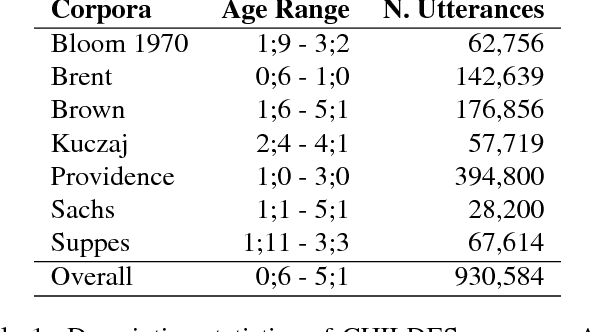
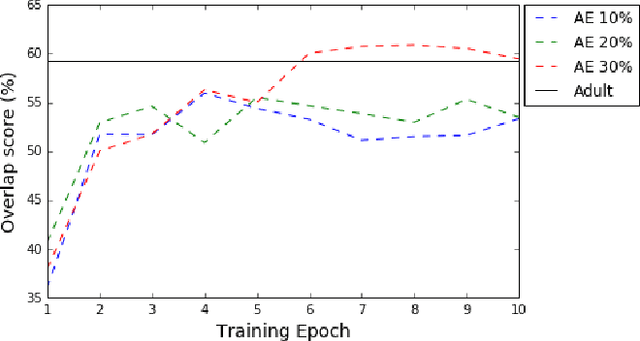
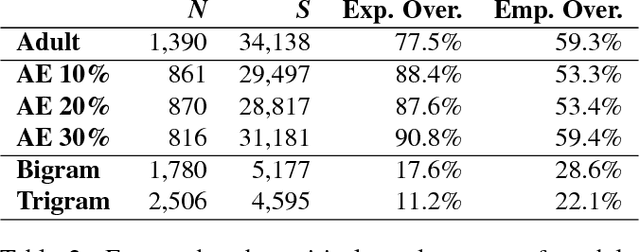
Increasingly, cognitive scientists have demonstrated interest in applying tools from deep learning. One use for deep learning is in language acquisition where it is useful to know if a linguistic phenomenon can be learned through domain-general means. To assess whether unsupervised deep learning is appropriate, we first pose a smaller question: Can unsupervised neural networks apply linguistic rules productively, using them in novel situations? We draw from the literature on determiner/noun productivity by training an unsupervised, autoencoder network measuring its ability to combine nouns with determiners. Our simple autoencoder creates combinations it has not previously encountered and produces a degree of overlap matching adults. While this preliminary work does not provide conclusive evidence for productivity, it warrants further investigation with more complex models. Further, this work helps lay the foundations for future collaboration between the deep learning and cognitive science communities.