 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Foundations without Foundations -- Why semi-mechanistic models are essential for regulatory biology
Jan 31, 2025Despite substantial efforts, deep learning has not yet delivered a transformative impact on elucidating regulatory biology, particularly in the realm of predicting gene expression profiles. Here, we argue that genuine "foundation models" of regulatory biology will remain out of reach unless guided by frameworks that integrate mechanistic insight with principled experimental design. We present one such ground-up, semi-mechanistic framework that unifies perturbation-based experimental designs across both in vitro and in vivo CRISPR screens, accounting for differentiating and non-differentiating cellular systems. By revealing previously unrecognised assumptions in published machine learning methods, our approach clarifies links with popular techniques such as variational autoencoders and structural causal models. In practice, this framework suggests a modified loss function that we demonstrate can improve predictive performance, and further suggests an error analysis that informs batching strategies. Ultimately, since cellular regulation emerges from innumerable interactions amongst largely uncharted molecular components, we contend that systems-level understanding cannot be achieved through structural biology alone. Instead, we argue that real progress will require a first-principles perspective on how experiments capture biological phenomena, how data are generated, and how these processes can be reflected in more faithful modelling architectures.
Sparse hierarchical representation learning on molecular graphs
Aug 06, 2019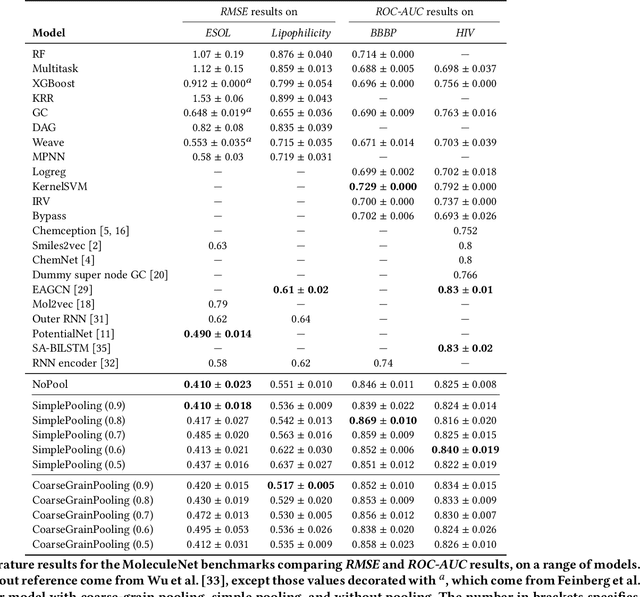
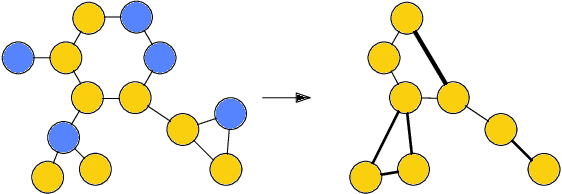

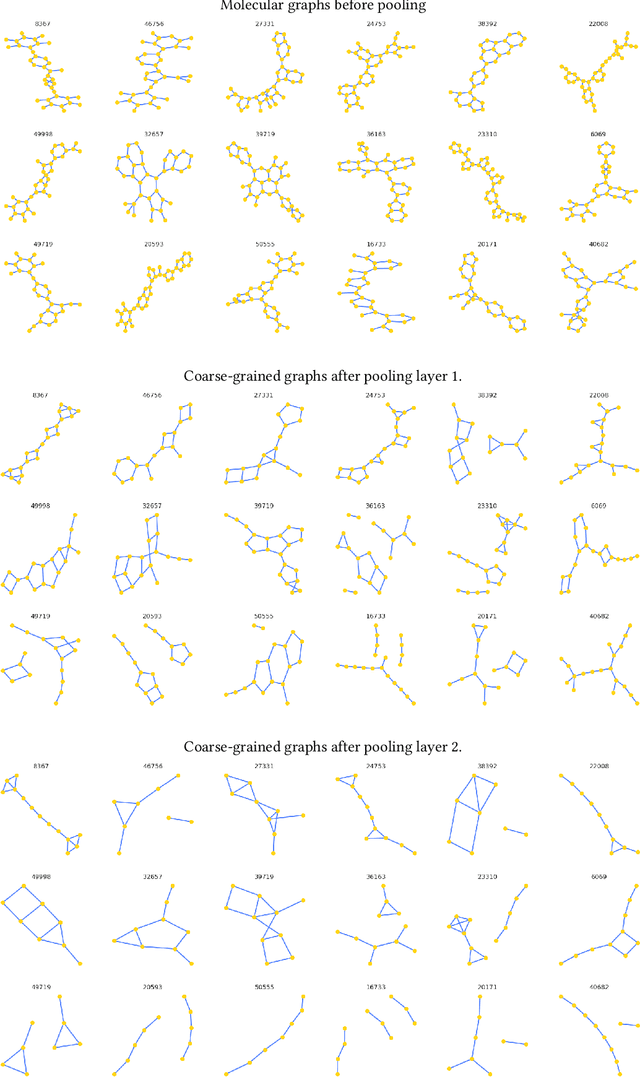
Architectures for sparse hierarchical representation learning have recently been proposed for graph-structured data, but so far assume the absence of edge features in the graph. We close this gap and propose a method to pool graphs with edge features, inspired by the hierarchical nature of chemistry. In particular, we introduce two types of pooling layers compatible with an edge-feature graph-convolutional architecture and investigate their performance for molecules relevant to drug discovery on a set of two classification and two regression benchmark datasets of MoleculeNet. We find that our models significantly outperform previous benchmarks on three of the datasets and reach state-of-the-art results on the fourth benchmark, with pooling improving performance for three out of four tasks, keeping performance stable on the fourth task, and generally speeding up the training process.