 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysically Controllable Relighting of Photographs
Aug 07, 2025



We present a self-supervised approach to in-the-wild image relighting that enables fully controllable, physically based illumination editing. We achieve this by combining the physical accuracy of traditional rendering with the photorealistic appearance made possible by neural rendering. Our pipeline works by inferring a colored mesh representation of a given scene using monocular estimates of geometry and intrinsic components. This representation allows users to define their desired illumination configuration in 3D. The scene under the new lighting can then be rendered using a path-tracing engine. We send this approximate rendering of the scene through a feed-forward neural renderer to predict the final photorealistic relighting result. We develop a differentiable rendering process to reconstruct in-the-wild scene illumination, enabling self-supervised training of our neural renderer on raw image collections. Our method represents a significant step in bringing the explicit physical control over lights available in typical 3D computer graphics tools, such as Blender, to in-the-wild relighting.
* Proc. SIGGRAPH 2025, 10 pages, 9 figures
Colorful Diffuse Intrinsic Image Decomposition in the Wild
Sep 20, 2024



Intrinsic image decomposition aims to separate the surface reflectance and the effects from the illumination given a single photograph. Due to the complexity of the problem, most prior works assume a single-color illumination and a Lambertian world, which limits their use in illumination-aware image editing applications. In this work, we separate an input image into its diffuse albedo, colorful diffuse shading, and specular residual components. We arrive at our result by gradually removing first the single-color illumination and then the Lambertian-world assumptions. We show that by dividing the problem into easier sub-problems, in-the-wild colorful diffuse shading estimation can be achieved despite the limited ground-truth datasets. Our extended intrinsic model enables illumination-aware analysis of photographs and can be used for image editing applications such as specularity removal and per-pixel white balancing.
Intrinsic Single-Image HDR Reconstruction
Sep 20, 2024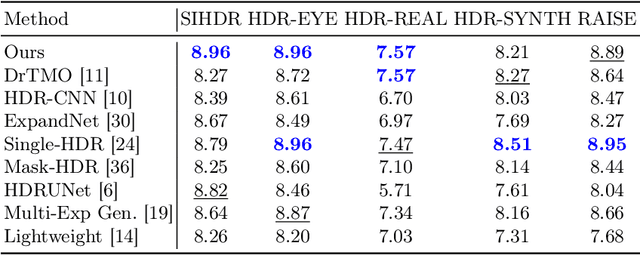



The low dynamic range (LDR) of common cameras fails to capture the rich contrast in natural scenes, resulting in loss of color and details in saturated pixels. Reconstructing the high dynamic range (HDR) of luminance present in the scene from single LDR photographs is an important task with many applications in computational photography and realistic display of images. The HDR reconstruction task aims to infer the lost details using the context present in the scene, requiring neural networks to understand high-level geometric and illumination cues. This makes it challenging for data-driven algorithms to generate accurate and high-resolution results. In this work, we introduce a physically-inspired remodeling of the HDR reconstruction problem in the intrinsic domain. The intrinsic model allows us to train separate networks to extend the dynamic range in the shading domain and to recover lost color details in the albedo domain. We show that dividing the problem into two simpler sub-tasks improves performance in a wide variety of photographs.
Intrinsic Harmonization for Illumination-Aware Compositing
Dec 07, 2023



Despite significant advancements in network-based image harmonization techniques, there still exists a domain disparity between typical training pairs and real-world composites encountered during inference. Most existing methods are trained to reverse global edits made on segmented image regions, which fail to accurately capture the lighting inconsistencies between the foreground and background found in composited images. In this work, we introduce a self-supervised illumination harmonization approach formulated in the intrinsic image domain. First, we estimate a simple global lighting model from mid-level vision representations to generate a rough shading for the foreground region. A network then refines this inferred shading to generate a harmonious re-shading that aligns with the background scene. In order to match the color appearance of the foreground and background, we utilize ideas from prior harmonization approaches to perform parameterized image edits in the albedo domain. To validate the effectiveness of our approach, we present results from challenging real-world composites and conduct a user study to objectively measure the enhanced realism achieved compared to state-of-the-art harmonization methods.
Intrinsic Image Decomposition via Ordinal Shading
Nov 21, 2023Intrinsic decomposition is a fundamental mid-level vision problem that plays a crucial role in various inverse rendering and computational photography pipelines. Generating highly accurate intrinsic decompositions is an inherently under-constrained task that requires precisely estimating continuous-valued shading and albedo. In this work, we achieve high-resolution intrinsic decomposition by breaking the problem into two parts. First, we present a dense ordinal shading formulation using a shift- and scale-invariant loss in order to estimate ordinal shading cues without restricting the predictions to obey the intrinsic model. We then combine low- and high-resolution ordinal estimations using a second network to generate a shading estimate with both global coherency and local details. We encourage the model to learn an accurate decomposition by computing losses on the estimated shading as well as the albedo implied by the intrinsic model. We develop a straightforward method for generating dense pseudo ground truth using our model's predictions and multi-illumination data, enabling generalization to in-the-wild imagery. We present an exhaustive qualitative and quantitative analysis of our predicted intrinsic components against state-of-the-art methods. Finally, we demonstrate the real-world applicability of our estimations by performing otherwise difficult editing tasks such as recoloring and relighting.
Computational Flash Photography through Intrinsics
Jun 09, 2023Flash is an essential tool as it often serves as the sole controllable light source in everyday photography. However, the use of flash is a binary decision at the time a photograph is captured with limited control over its characteristics such as strength or color. In this work, we study the computational control of the flash light in photographs taken with or without flash. We present a physically motivated intrinsic formulation for flash photograph formation and develop flash decomposition and generation methods for flash and no-flash photographs, respectively. We demonstrate that our intrinsic formulation outperforms alternatives in the literature and allows us to computationally control flash in in-the-wild images.
A Study of Few-Shot Audio Classification
Dec 02, 2020

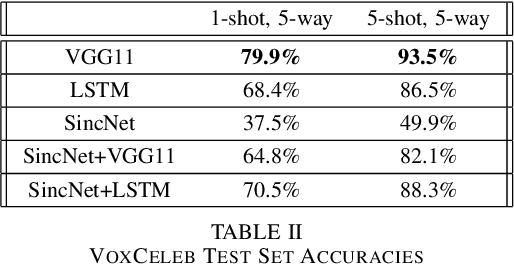

Advances in deep learning have resulted in state-of-the-art performance for many audio classification tasks but, unlike humans, these systems traditionally require large amounts of data to make accurate predictions. Not every person or organization has access to those resources, and the organizations that do, like our field at large, do not reflect the demographics of our country. Enabling people to use machine learning without significant resource hurdles is important, because machine learning is an increasingly useful tool for solving problems, and can solve a broader set of problems when put in the hands of a broader set of people. Few-shot learning is a type of machine learning designed to enable the model to generalize to new classes with very few examples. In this research, we address two audio classification tasks (speaker identification and activity classification) with the Prototypical Network few-shot learning algorithm, and assess performance of various encoder architectures. Our encoders include recurrent neural networks, as well as one- and two-dimensional convolutional neural networks. We evaluate our model for speaker identification on the VoxCeleb dataset and ICSI Meeting Corpus, obtaining 5-shot 5-way accuracies of 93.5% and 54.0%, respectively. We also evaluate for activity classification from audio using few-shot subsets of the Kinetics~600 dataset and AudioSet, both drawn from Youtube videos, obtaining 51.5% and 35.2% accuracy, respectively.
Metric-Based Few-Shot Learning for Video Action Recognition
Sep 14, 2019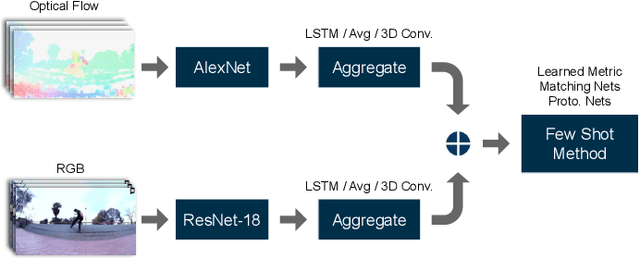
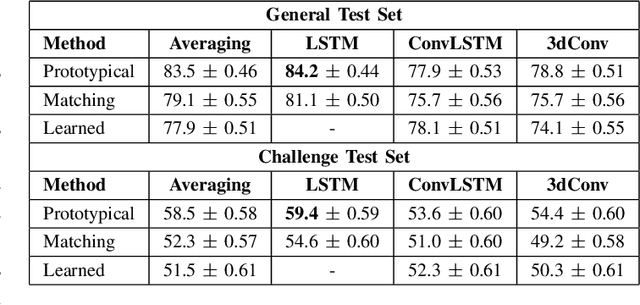
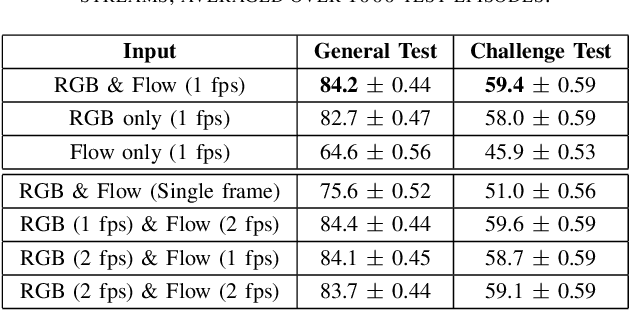
In the few-shot scenario, a learner must effectively generalize to unseen classes given a small support set of labeled examples. While a relatively large amount of research has gone into few-shot learning for image classification, little work has been done on few-shot video classification. In this work, we address the task of few-shot video action recognition with a set of two-stream models. We evaluate the performance of a set of convolutional and recurrent neural network video encoder architectures used in conjunction with three popular metric-based few-shot algorithms. We train and evaluate using a few-shot split of the Kinetics 600 dataset. Our experiments confirm the importance of the two-stream setup, and find prototypical networks and pooled long short-term memory network embeddings to give the best performance as few-shot method and video encoder, respectively. For a 5-shot 5-way task, this setup obtains 84.2% accuracy on the test set and 59.4% on a special "challenge" test set, composed of highly confusable classes.