 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBack to the Barn with LLAMAs: Evolving Pretrained LLM Backbones in Finetuning Vision Language Models
Apr 13, 2026Vision-Language Models (VLMs) have rapidly advanced by leveraging powerful pre-trained Large Language Models (LLMs) as core reasoning backbones. As new and more capable LLMs emerge with improved reasoning, instruction-following, and generalization, there is a pressing need to efficiently update existing VLMs to incorporate these advancements. However, the integration of new LLMs into VLMs, particularly how the evolving LLMs contribute to multimodal reasoning, alignment, and task-specific performance remains underexplored. Addressing this gap is important for VLM development, given the rapid evolution of pretrained LLM backbones. This study presents a controlled and systematic investigation of how changes in the pretrained LLM backbone affect downstream VLM task performance. By having the vision encoder, training data, and post-training algorithm remain same across LLAMA-1, LLAMA-2, and LLAMA-3 based VLMs, we find that newer LLM backbones do not always lead to better VLMs, but the performance depends on the downstream VLM task. For example, in visual question and answering tasks, newer LLM backbones tend to solve different questions rather than just more questions, and our analysis shows this is driven by differences in how the models process information, including better calibrated confidence and more stable internal representations. We also find that some VLM capabilities appear only in the newest LLM generation, while tasks that depend mainly on visual understanding see little benefit from a newer LLM backbone.
Recursive Decoding: A Situated Cognition Approach to Compositional Generation in Grounded Language Understanding
Jan 27, 2022



Compositional generalization is a troubling blind spot for neural language models. Recent efforts have presented techniques for improving a model's ability to encode novel combinations of known inputs, but less work has focused on generating novel combinations of known outputs. Here we focus on this latter "decode-side" form of generalization in the context of gSCAN, a synthetic benchmark for compositional generalization in grounded language understanding. We present Recursive Decoding (RD), a novel procedure for training and using seq2seq models, targeted towards decode-side generalization. Rather than generating an entire output sequence in one pass, models are trained to predict one token at a time. Inputs (i.e., the external gSCAN environment) are then incrementally updated based on predicted tokens, and re-encoded for the next decoder time step. RD thus decomposes a complex, out-of-distribution sequence generation task into a series of incremental predictions that each resemble what the model has already seen during training. RD yields dramatic improvement on two previously neglected generalization tasks in gSCAN. We provide analyses to elucidate these gains over failure of a baseline, and then discuss implications for generalization in naturalistic grounded language understanding, and seq2seq more generally.
Proposal-based Few-shot Sound Event Detection for Speech and Environmental Sounds with Perceivers
Jul 28, 2021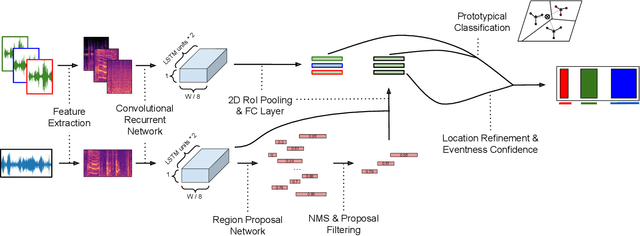
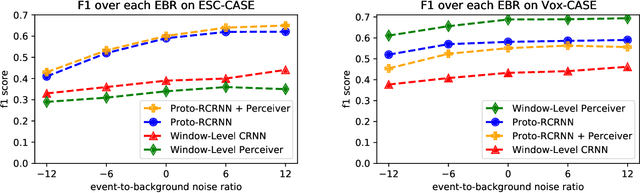
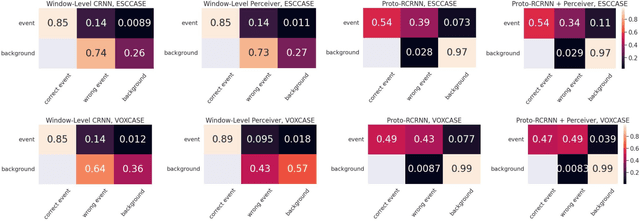
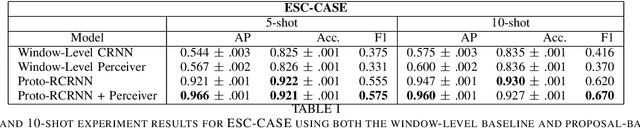
There are many important applications for detecting and localizing specific sound events within long, untrimmed documents including keyword spotting, medical observation, and bioacoustic monitoring for conservation. Deep learning techniques often set the state-of-the-art for these tasks. However, for some types of events, there is insufficient labeled data to train deep learning models. In this paper, we propose novel approaches to few-shot sound event detection utilizing region proposals and the Perceiver architecture, which is capable of accurately localizing sound events with very few examples of each class of interest. Motivated by a lack of suitable benchmark datasets for few-shot audio event detection, we generate and evaluate on two novel episodic rare sound event datasets: one using clips of celebrity speech as the sound event, and the other using environmental sounds. Our highest performing proposed few-shot approaches achieve 0.575 and 0.672 F1-score, respectively, with 5-shot 5-way tasks on these two datasets. These represent absolute improvements of 0.200 and 0.234 over strong proposal-free few-shot sound event detection baselines.
Prototypical Region Proposal Networks for Few-Shot Localization and Classification
Apr 08, 2021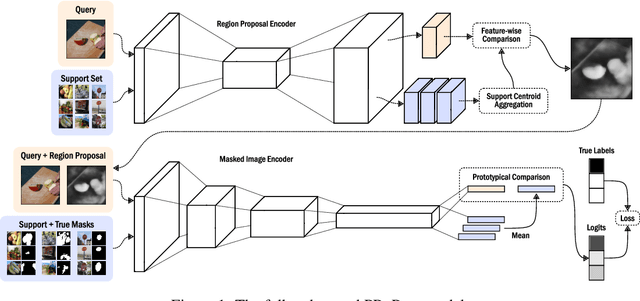
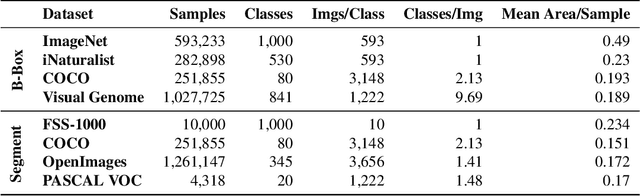
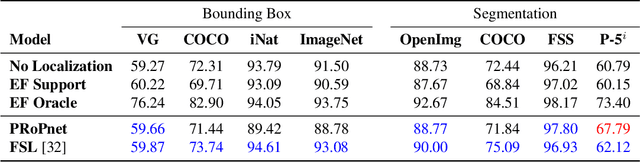
Recently proposed few-shot image classification methods have generally focused on use cases where the objects to be classified are the central subject of images. Despite success on benchmark vision datasets aligned with this use case, these methods typically fail on use cases involving densely-annotated, busy images: images common in the wild where objects of relevance are not the central subject, instead appearing potentially occluded, small, or among other incidental objects belonging to other classes of potential interest. To localize relevant objects, we employ a prototype-based few-shot segmentation model which compares the encoded features of unlabeled query images with support class centroids to produce region proposals indicating the presence and location of support set classes in a query image. These region proposals are then used as additional conditioning input to few-shot image classifiers. We develop a framework to unify the two stages (segmentation and classification) into an end-to-end classification model -- PRoPnet -- and empirically demonstrate that our methods improve accuracy on image datasets with natural scenes containing multiple object classes.
A Study of Few-Shot Audio Classification
Dec 02, 2020

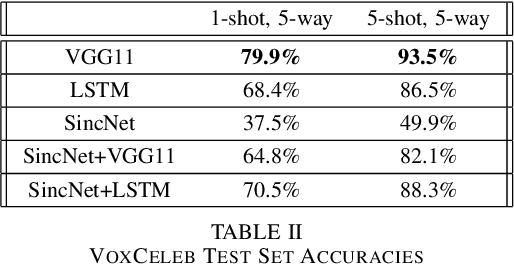

Advances in deep learning have resulted in state-of-the-art performance for many audio classification tasks but, unlike humans, these systems traditionally require large amounts of data to make accurate predictions. Not every person or organization has access to those resources, and the organizations that do, like our field at large, do not reflect the demographics of our country. Enabling people to use machine learning without significant resource hurdles is important, because machine learning is an increasingly useful tool for solving problems, and can solve a broader set of problems when put in the hands of a broader set of people. Few-shot learning is a type of machine learning designed to enable the model to generalize to new classes with very few examples. In this research, we address two audio classification tasks (speaker identification and activity classification) with the Prototypical Network few-shot learning algorithm, and assess performance of various encoder architectures. Our encoders include recurrent neural networks, as well as one- and two-dimensional convolutional neural networks. We evaluate our model for speaker identification on the VoxCeleb dataset and ICSI Meeting Corpus, obtaining 5-shot 5-way accuracies of 93.5% and 54.0%, respectively. We also evaluate for activity classification from audio using few-shot subsets of the Kinetics~600 dataset and AudioSet, both drawn from Youtube videos, obtaining 51.5% and 35.2% accuracy, respectively.