 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Classroom Activity Detection from Audio with Neural Networks
Jul 29, 2021


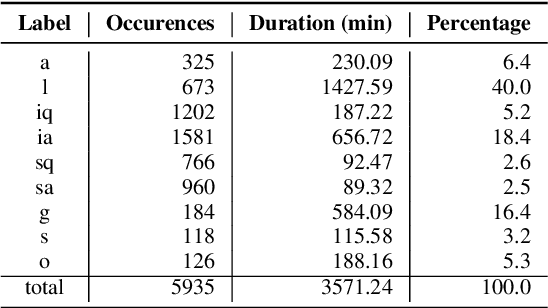
Instructors are increasingly incorporating student-centered learning techniques in their classrooms to improve learning outcomes. In addition to lecture, these class sessions involve forms of individual and group work, and greater rates of student-instructor interaction. Quantifying classroom activity is a key element of accelerating the evaluation and refinement of innovative teaching practices, but manual annotation does not scale. In this manuscript, we present advances to the young application area of automatic classroom activity detection from audio. Using a university classroom corpus with nine activity labels (e.g., "lecture," "group work," "student question"), we propose and evaluate deep fully connected, convolutional, and recurrent neural network architectures, comparing the performance of mel-filterbank, OpenSmile, and self-supervised acoustic features. We compare 9-way classification performance with 5-way and 4-way simplifications of the task and assess two types of generalization: (1) new class sessions from previously seen instructors, and (2) previously unseen instructors. We obtain strong results on the new fine-grained task and state-of-the-art on the 4-way task: our best model obtains frame-level error rates of 6.2%, 7.7% and 28.0% when generalizing to unseen instructors for the 4-way, 5-way, and 9-way classification tasks, respectively (relative reductions of 35.4%, 48.3% and 21.6% over a strong baseline). When estimating the aggregate time spent on classroom activities, our average root mean squared error is 1.64 minutes per class session, a 54.9% relative reduction over the baseline.
Proposal-based Few-shot Sound Event Detection for Speech and Environmental Sounds with Perceivers
Jul 28, 2021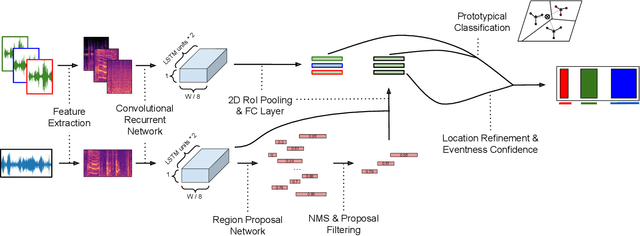
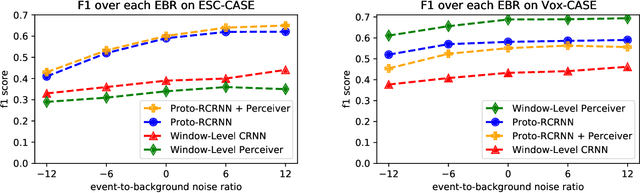
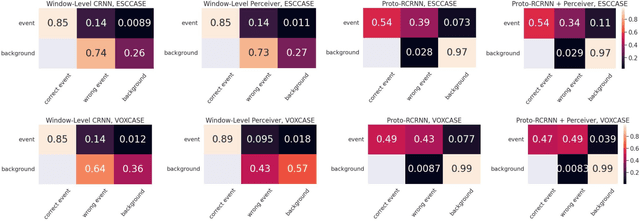
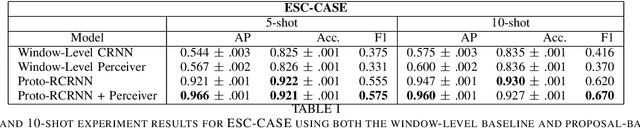
There are many important applications for detecting and localizing specific sound events within long, untrimmed documents including keyword spotting, medical observation, and bioacoustic monitoring for conservation. Deep learning techniques often set the state-of-the-art for these tasks. However, for some types of events, there is insufficient labeled data to train deep learning models. In this paper, we propose novel approaches to few-shot sound event detection utilizing region proposals and the Perceiver architecture, which is capable of accurately localizing sound events with very few examples of each class of interest. Motivated by a lack of suitable benchmark datasets for few-shot audio event detection, we generate and evaluate on two novel episodic rare sound event datasets: one using clips of celebrity speech as the sound event, and the other using environmental sounds. Our highest performing proposed few-shot approaches achieve 0.575 and 0.672 F1-score, respectively, with 5-shot 5-way tasks on these two datasets. These represent absolute improvements of 0.200 and 0.234 over strong proposal-free few-shot sound event detection baselines.