 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmulating the Global Change Analysis Model with Deep Learning
Dec 12, 2024



The Global Change Analysis Model (GCAM) simulates complex interactions between the coupled Earth and human systems, providing valuable insights into the co-evolution of land, water, and energy sectors under different future scenarios. Understanding the sensitivities and drivers of this multisectoral system can lead to more robust understanding of the different pathways to particular outcomes. The interactions and complexity of the coupled human-Earth systems make GCAM simulations costly to run at scale - a requirement for large ensemble experiments which explore uncertainty in model parameters and outputs. A differentiable emulator with similar predictive power, but greater efficiency, could provide novel scenario discovery and analysis of GCAM and its outputs, requiring fewer runs of GCAM. As a first use case, we train a neural network on an existing large ensemble that explores a range of GCAM inputs related to different relative contributions of energy production sources, with a focus on wind and solar. We complement this existing ensemble with interpolated input values and a wider selection of outputs, predicting 22,528 GCAM outputs across time, sectors, and regions. We report a median $R^2$ score of 0.998 for the emulator's predictions and an $R^2$ score of 0.812 for its input-output sensitivity.
DiffESM: Conditional Emulation of Temperature and Precipitation in Earth System Models with 3D Diffusion Models
Sep 17, 2024
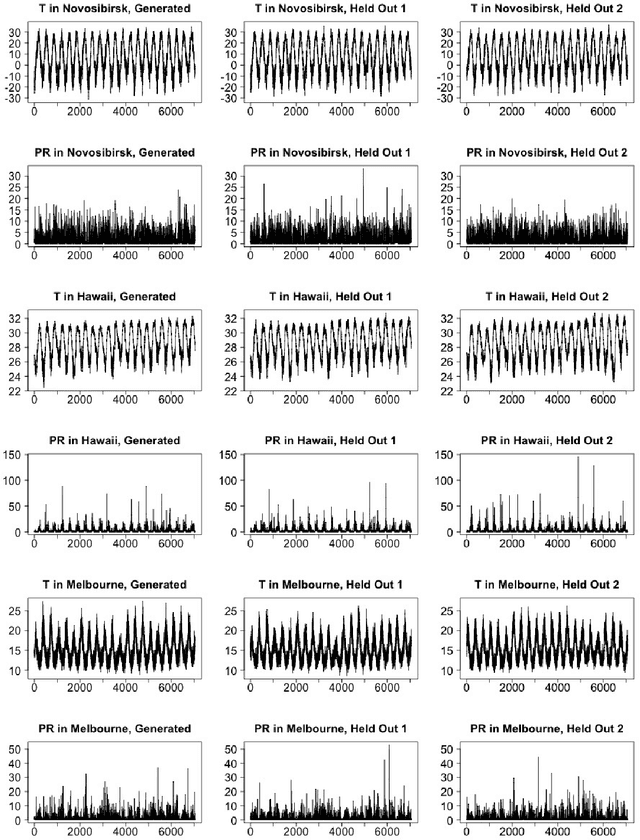
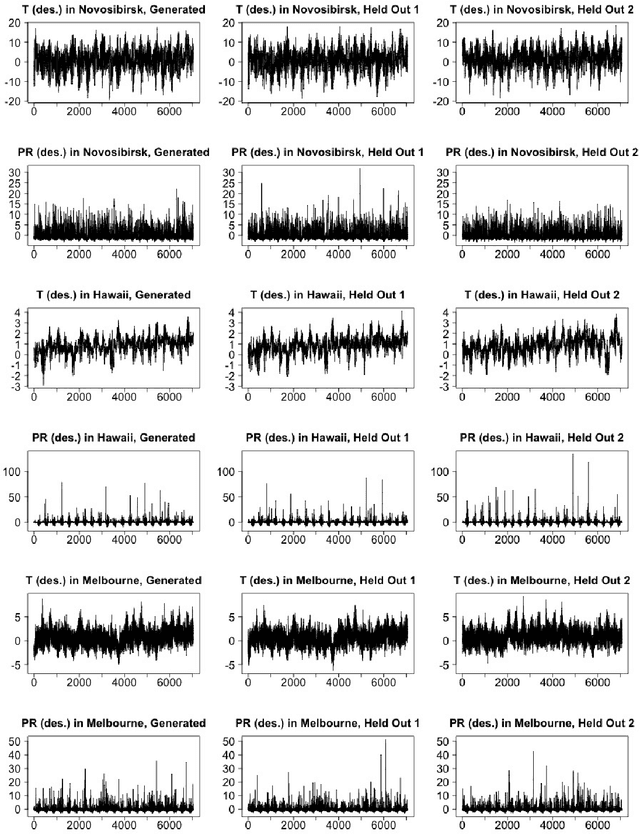
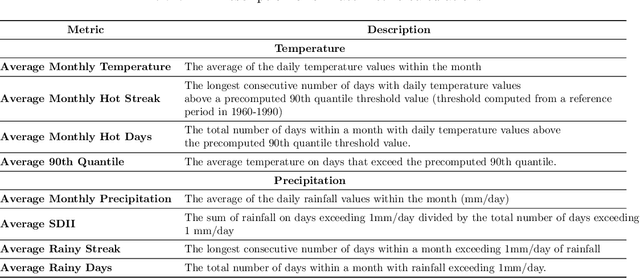
Earth System Models (ESMs) are essential for understanding the interaction between human activities and the Earth's climate. However, the computational demands of ESMs often limit the number of simulations that can be run, hindering the robust analysis of risks associated with extreme weather events. While low-cost climate emulators have emerged as an alternative to emulate ESMs and enable rapid analysis of future climate, many of these emulators only provide output on at most a monthly frequency. This temporal resolution is insufficient for analyzing events that require daily characterization, such as heat waves or heavy precipitation. We propose using diffusion models, a class of generative deep learning models, to effectively downscale ESM output from a monthly to a daily frequency. Trained on a handful of ESM realizations, reflecting a wide range of radiative forcings, our DiffESM model takes monthly mean precipitation or temperature as input, and is capable of producing daily values with statistical characteristics close to ESM output. Combined with a low-cost emulator providing monthly means, this approach requires only a small fraction of the computational resources needed to run a large ensemble. We evaluate model behavior using a number of extreme metrics, showing that DiffESM closely matches the spatio-temporal behavior of the ESM output it emulates in terms of the frequency and spatial characteristics of phenomena such as heat waves, dry spells, or rainfall intensity.
Diffusion-Based Joint Temperature and Precipitation Emulation of Earth System Models
Apr 12, 2024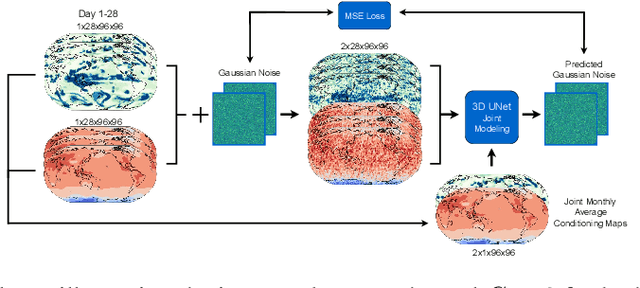

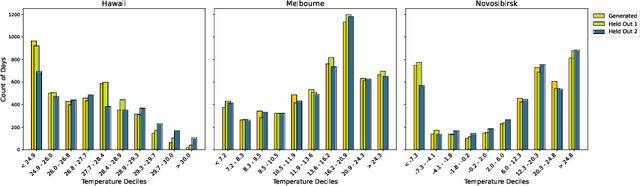
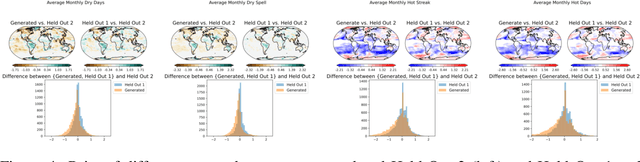
Earth system models (ESMs) are the principal tools used in climate science to generate future climate projections under various atmospheric emissions scenarios on a global or regional scale. Generative deep learning approaches are suitable for emulating these tools due to their computational efficiency and ability, once trained, to generate realizations in a fraction of the time required by ESMs. We extend previous work that used a generative probabilistic diffusion model to emulate ESMs by targeting the joint emulation of multiple variables, temperature and precipitation, by a single diffusion model. Joint generation of multiple variables is critical to generate realistic samples of phenomena resulting from the interplay of multiple variables. The diffusion model emulator takes in the monthly mean-maps of temperature and precipitation and produces the daily values of each of these variables that exhibit statistical properties similar to those generated by ESMs. Our results show the outputs from our extended model closely resemble those from ESMs on various climate metrics including dry spells and hot streaks, and that the joint distribution of temperature and precipitation in our sample closely matches those of ESMs.
RoseNet: Predicting Energy Metrics of Double InDel Mutants Using Deep Learning
Oct 20, 2023
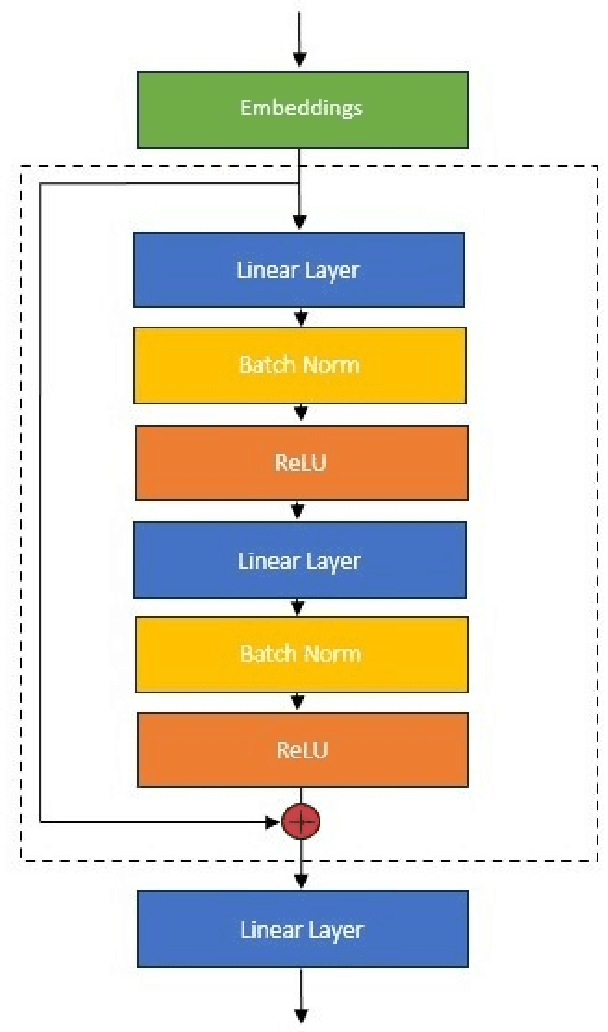
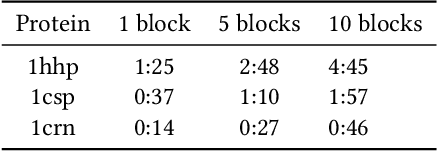
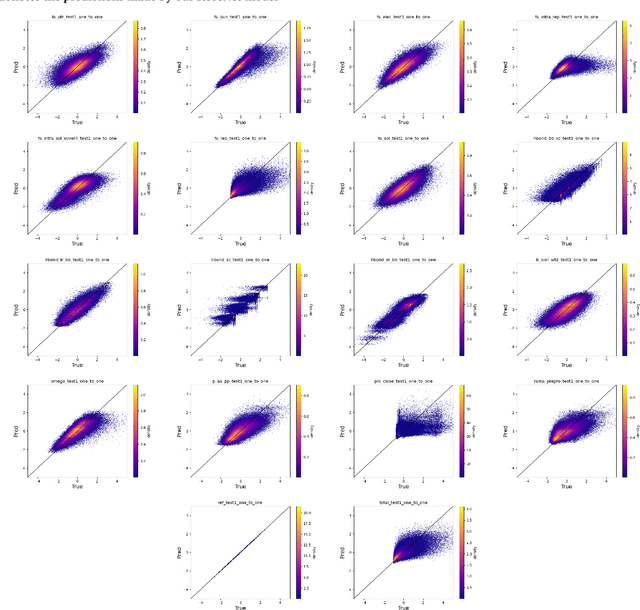
An amino acid insertion or deletion, or InDel, can have profound and varying functional impacts on a protein's structure. InDel mutations in the transmembrane conductor regulator protein for example give rise to cystic fibrosis. Unfortunately performing InDel mutations on physical proteins and studying their effects is a time prohibitive process. Consequently, modeling InDels computationally can supplement and inform wet lab experiments. In this work, we make use of our data sets of exhaustive double InDel mutations for three proteins which we computationally generated using a robotics inspired inverse kinematics approach available in Rosetta. We develop and train a neural network, RoseNet, on several structural and energetic metrics output by Rosetta during the mutant generation process. We explore and present how RoseNet is able to emulate the exhaustive data set using deep learning methods, and show to what extent it can predict Rosetta metrics for unseen mutant sequences with two InDels. RoseNet achieves a Pearson correlation coefficient median accuracy of 0.775 over all Rosetta scores for the largest protein. Furthermore, a sensitivity analysis is performed to determine the necessary quantity of data required to accurately emulate the structural scores for computationally generated mutants. We show that the model can be trained on minimal data (<50%) and still retain a high level of accuracy.
* Presented at Computational Structural Bioinformatics Workshop 2023
DiffESM: Conditional Emulation of Earth System Models with Diffusion Models
Apr 23, 2023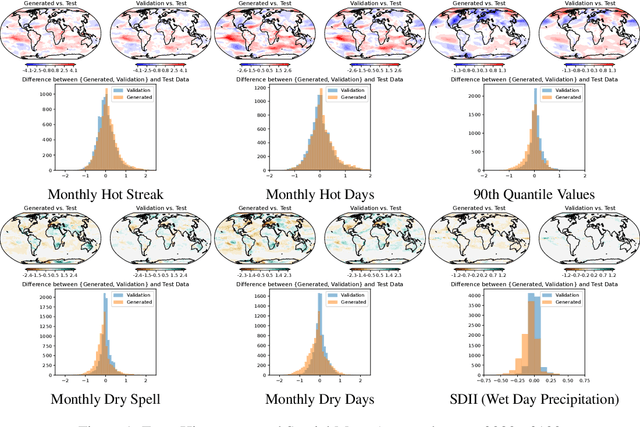
Earth System Models (ESMs) are essential tools for understanding the impact of human actions on Earth's climate. One key application of these models is studying extreme weather events, such as heat waves or dry spells, which have significant socioeconomic and environmental consequences. However, the computational demands of running a sufficient number of simulations to analyze the risks are often prohibitive. In this paper we demonstrate that diffusion models -- a class of generative deep learning models -- can effectively emulate the spatio-temporal trends of ESMs under previously unseen climate scenarios, while only requiring a small fraction of the computational resources. We present a diffusion model that is conditioned on monthly averages of temperature or precipitation on a $96 \times 96$ global grid, and produces daily values that are both realistic and consistent with those averages. Our results show that the output from our diffusion model closely matches the spatio-temporal behavior of the ESM it emulates in terms of the frequency of phenomena such as heat waves, dry spells, or rainfall intensity.
Fine-Grained Classroom Activity Detection from Audio with Neural Networks
Jul 29, 2021


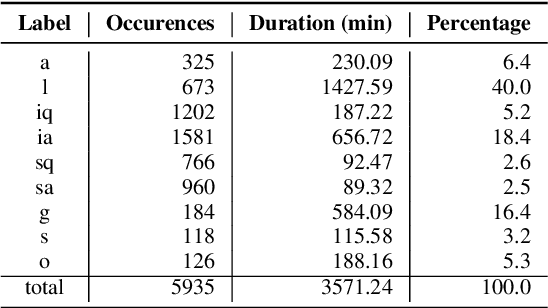
Instructors are increasingly incorporating student-centered learning techniques in their classrooms to improve learning outcomes. In addition to lecture, these class sessions involve forms of individual and group work, and greater rates of student-instructor interaction. Quantifying classroom activity is a key element of accelerating the evaluation and refinement of innovative teaching practices, but manual annotation does not scale. In this manuscript, we present advances to the young application area of automatic classroom activity detection from audio. Using a university classroom corpus with nine activity labels (e.g., "lecture," "group work," "student question"), we propose and evaluate deep fully connected, convolutional, and recurrent neural network architectures, comparing the performance of mel-filterbank, OpenSmile, and self-supervised acoustic features. We compare 9-way classification performance with 5-way and 4-way simplifications of the task and assess two types of generalization: (1) new class sessions from previously seen instructors, and (2) previously unseen instructors. We obtain strong results on the new fine-grained task and state-of-the-art on the 4-way task: our best model obtains frame-level error rates of 6.2%, 7.7% and 28.0% when generalizing to unseen instructors for the 4-way, 5-way, and 9-way classification tasks, respectively (relative reductions of 35.4%, 48.3% and 21.6% over a strong baseline). When estimating the aggregate time spent on classroom activities, our average root mean squared error is 1.64 minutes per class session, a 54.9% relative reduction over the baseline.
Proposal-based Few-shot Sound Event Detection for Speech and Environmental Sounds with Perceivers
Jul 28, 2021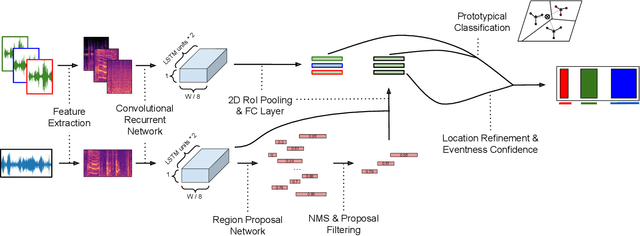
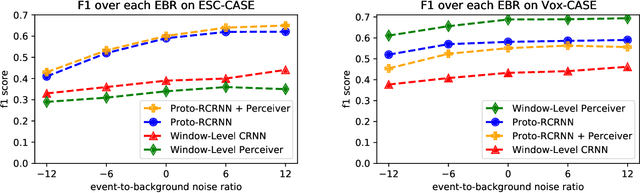
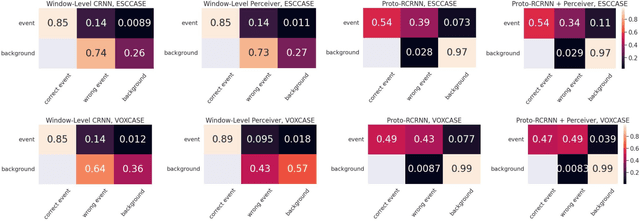
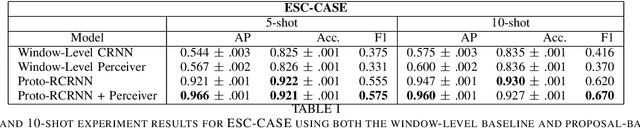
There are many important applications for detecting and localizing specific sound events within long, untrimmed documents including keyword spotting, medical observation, and bioacoustic monitoring for conservation. Deep learning techniques often set the state-of-the-art for these tasks. However, for some types of events, there is insufficient labeled data to train deep learning models. In this paper, we propose novel approaches to few-shot sound event detection utilizing region proposals and the Perceiver architecture, which is capable of accurately localizing sound events with very few examples of each class of interest. Motivated by a lack of suitable benchmark datasets for few-shot audio event detection, we generate and evaluate on two novel episodic rare sound event datasets: one using clips of celebrity speech as the sound event, and the other using environmental sounds. Our highest performing proposed few-shot approaches achieve 0.575 and 0.672 F1-score, respectively, with 5-shot 5-way tasks on these two datasets. These represent absolute improvements of 0.200 and 0.234 over strong proposal-free few-shot sound event detection baselines.
Loosely Conditioned Emulation of Global Climate Models With Generative Adversarial Networks
Apr 29, 2021
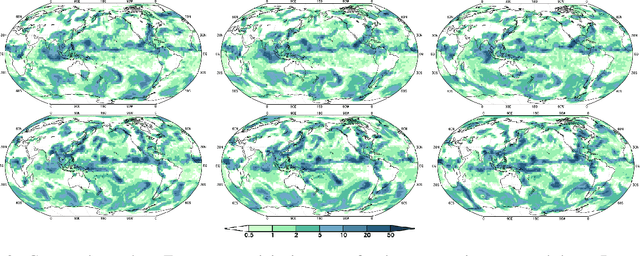
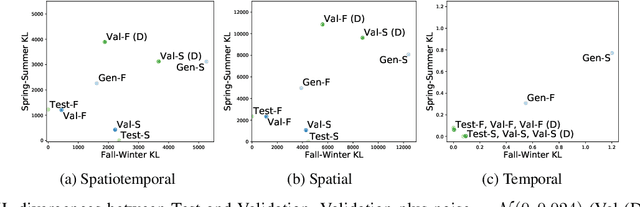
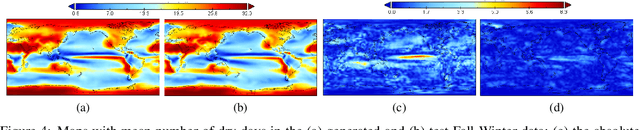
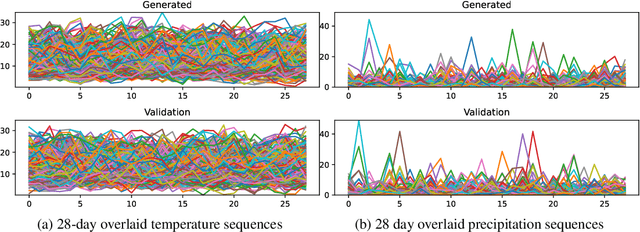
Climate models encapsulate our best understanding of the Earth system, allowing research to be conducted on its future under alternative assumptions of how human-driven climate forces are going to evolve. An important application of climate models is to provide metrics of mean and extreme climate changes, particularly under these alternative future scenarios, as these quantities drive the impacts of climate on society and natural systems. Because of the need to explore a wide range of alternative scenarios and other sources of uncertainties in a computationally efficient manner, climate models can only take us so far, as they require significant computational resources, especially when attempting to characterize extreme events, which are rare and thus demand long and numerous simulations in order to accurately represent their changing statistics. Here we use deep learning in a proof of concept that lays the foundation for emulating global climate model output for different scenarios. We train two "loosely conditioned" Generative Adversarial Networks (GANs) that emulate daily precipitation output from a fully coupled Earth system model: one GAN modeling Fall-Winter behavior and the other Spring-Summer. Our GANs are trained to produce spatiotemporal samples: 32 days of precipitation over a 64x128 regular grid discretizing the globe. We evaluate the generator with a set of related performance metrics based upon KL divergence, and find the generated samples to be nearly as well matched to the test data as the validation data is to test. We also find the generated samples to accurately estimate the mean number of dry days and mean longest dry spell in the 32 day samples. Our trained GANs can rapidly generate numerous realizations at a vastly reduced computational expense, compared to large ensembles of climate models, which greatly aids in estimating the statistics of extreme events.
A Study of Few-Shot Audio Classification
Dec 02, 2020

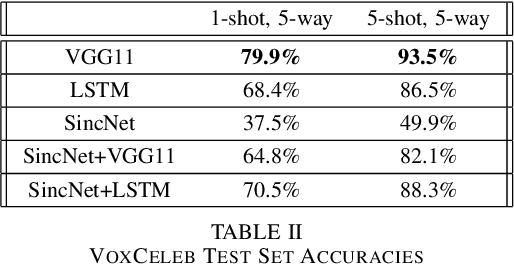

Advances in deep learning have resulted in state-of-the-art performance for many audio classification tasks but, unlike humans, these systems traditionally require large amounts of data to make accurate predictions. Not every person or organization has access to those resources, and the organizations that do, like our field at large, do not reflect the demographics of our country. Enabling people to use machine learning without significant resource hurdles is important, because machine learning is an increasingly useful tool for solving problems, and can solve a broader set of problems when put in the hands of a broader set of people. Few-shot learning is a type of machine learning designed to enable the model to generalize to new classes with very few examples. In this research, we address two audio classification tasks (speaker identification and activity classification) with the Prototypical Network few-shot learning algorithm, and assess performance of various encoder architectures. Our encoders include recurrent neural networks, as well as one- and two-dimensional convolutional neural networks. We evaluate our model for speaker identification on the VoxCeleb dataset and ICSI Meeting Corpus, obtaining 5-shot 5-way accuracies of 93.5% and 54.0%, respectively. We also evaluate for activity classification from audio using few-shot subsets of the Kinetics~600 dataset and AudioSet, both drawn from Youtube videos, obtaining 51.5% and 35.2% accuracy, respectively.
DeepClimGAN: A High-Resolution Climate Data Generator
Nov 23, 2020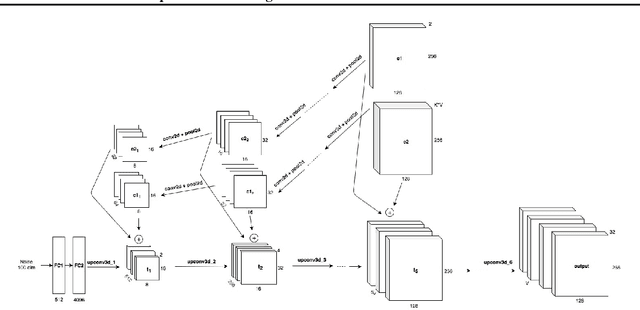

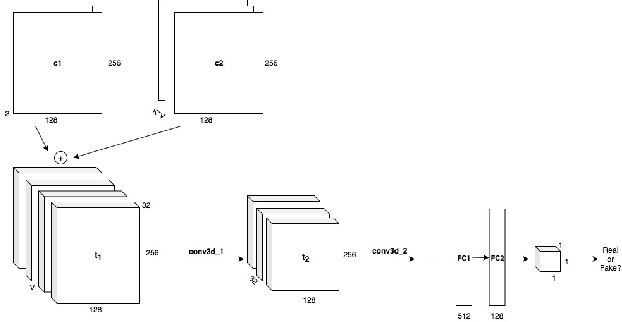
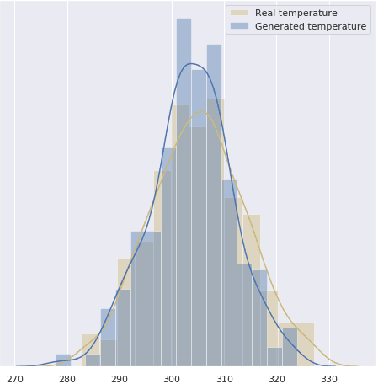
Earth system models (ESMs), which simulate the physics and chemistry of the global atmosphere, land, and ocean, are often used to generate future projections of climate change scenarios. These models are far too computationally intensive to run repeatedly, but limited sets of runs are insufficient for some important applications, like adequately sampling distribution tails to characterize extreme events. As a compromise, emulators are substantially less expensive but may not have all of the complexity of an ESM. Here we demonstrate the use of a conditional generative adversarial network (GAN) to act as an ESM emulator. In doing so, we gain the ability to produce daily weather data that is consistent with what ESM might output over any chosen scenario. In particular, the GAN is aimed at representing a joint probability distribution over space, time, and climate variables, enabling the study of correlated extreme events, such as floods, droughts, or heatwaves.