 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmnilingual ASR: Open-Source Multilingual Speech Recognition for 1600+ Languages
Nov 12, 2025



Automatic speech recognition (ASR) has advanced in high-resource languages, but most of the world's 7,000+ languages remain unsupported, leaving thousands of long-tail languages behind. Expanding ASR coverage has been costly and limited by architectures that restrict language support, making extension inaccessible to most--all while entangled with ethical concerns when pursued without community collaboration. To transcend these limitations, we introduce Omnilingual ASR, the first large-scale ASR system designed for extensibility. Omnilingual ASR enables communities to introduce unserved languages with only a handful of data samples. It scales self-supervised pre-training to 7B parameters to learn robust speech representations and introduces an encoder-decoder architecture designed for zero-shot generalization, leveraging a LLM-inspired decoder. This capability is grounded in a massive and diverse training corpus; by combining breadth of coverage with linguistic variety, the model learns representations robust enough to adapt to unseen languages. Incorporating public resources with community-sourced recordings gathered through compensated local partnerships, Omnilingual ASR expands coverage to over 1,600 languages, the largest such effort to date--including over 500 never before served by ASR. Automatic evaluations show substantial gains over prior systems, especially in low-resource conditions, and strong generalization. We release Omnilingual ASR as a family of models, from 300M variants for low-power devices to 7B for maximum accuracy. We reflect on the ethical considerations shaping this design and conclude by discussing its societal impact. In particular, we highlight how open-sourcing models and tools can lower barriers for researchers and communities, inviting new forms of participation. Open-source artifacts are available at https://github.com/facebookresearch/omnilingual-asr.
Deep Learning for Spectral Filling in Radio Frequency Applications
Mar 31, 2022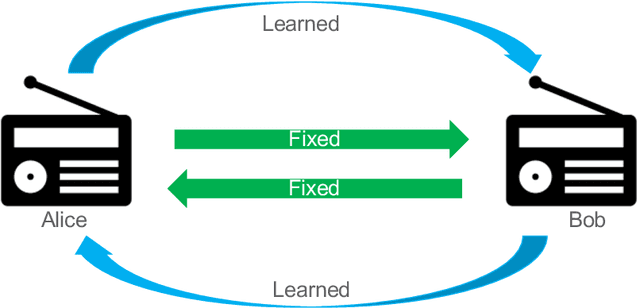
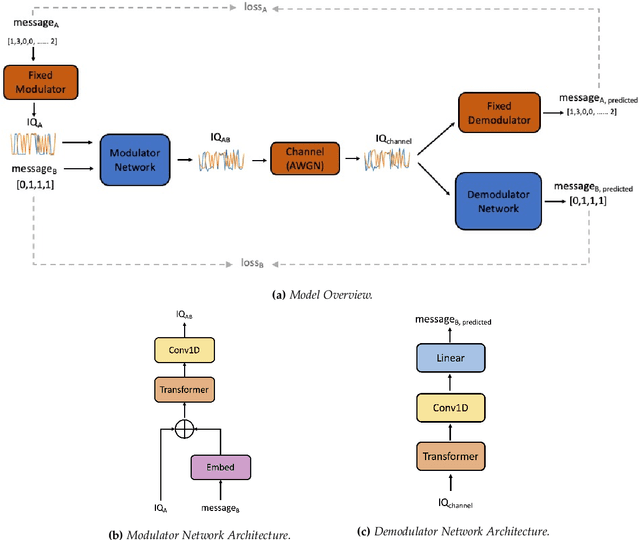
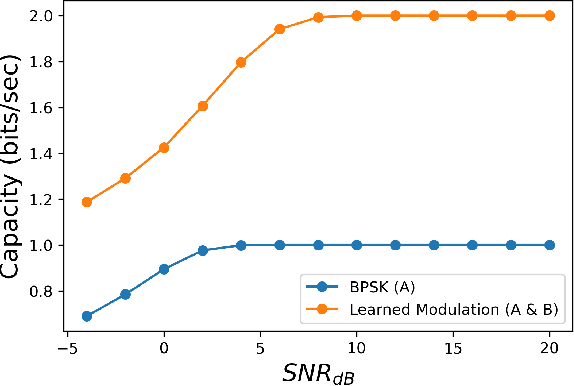
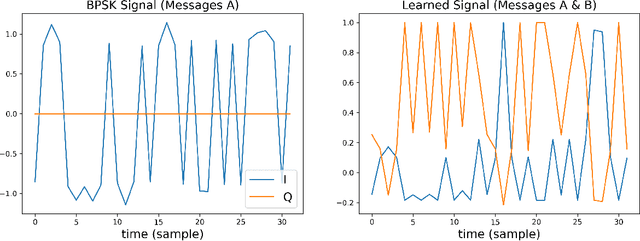
Due to the Internet of Things (IoT) proliferation, Radio Frequency (RF) channels are increasingly congested with new kinds of devices, which carry unique and diverse communication needs. This poses complex challenges in modern digital communications, and calls for the development of technological innovations that (i) optimize capacity (bitrate) in limited bandwidth environments, (ii) integrate cooperatively with already-deployed RF protocols, and (iii) are adaptive to the ever-changing demands in modern digital communications. In this paper we present methods for applying deep neural networks for spectral filling. Given an RF channel transmitting digital messages with a pre-established modulation scheme, we automatically learn novel modulation schemes for sending extra information, in the form of additional messages, "around" the fixed-modulation signals (i.e., without interfering with them). In so doing, we effectively increase channel capacity without increasing bandwidth. We further demonstrate the ability to generate signals that closely resemble the original modulations, such that the presence of extra messages is undetectable to third-party listeners. We present three computational experiments demonstrating the efficacy of our methods, and conclude by discussing the implications of our results for modern RF applications.
Recursive Decoding: A Situated Cognition Approach to Compositional Generation in Grounded Language Understanding
Jan 27, 2022



Compositional generalization is a troubling blind spot for neural language models. Recent efforts have presented techniques for improving a model's ability to encode novel combinations of known inputs, but less work has focused on generating novel combinations of known outputs. Here we focus on this latter "decode-side" form of generalization in the context of gSCAN, a synthetic benchmark for compositional generalization in grounded language understanding. We present Recursive Decoding (RD), a novel procedure for training and using seq2seq models, targeted towards decode-side generalization. Rather than generating an entire output sequence in one pass, models are trained to predict one token at a time. Inputs (i.e., the external gSCAN environment) are then incrementally updated based on predicted tokens, and re-encoded for the next decoder time step. RD thus decomposes a complex, out-of-distribution sequence generation task into a series of incremental predictions that each resemble what the model has already seen during training. RD yields dramatic improvement on two previously neglected generalization tasks in gSCAN. We provide analyses to elucidate these gains over failure of a baseline, and then discuss implications for generalization in naturalistic grounded language understanding, and seq2seq more generally.