 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Learning with Metric-Agnostic Conditional Embeddings
Feb 12, 2018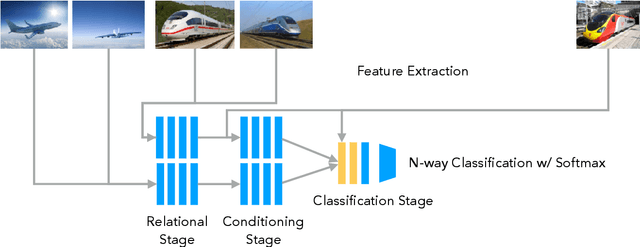
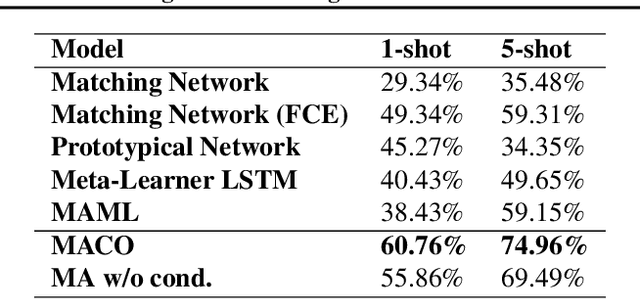
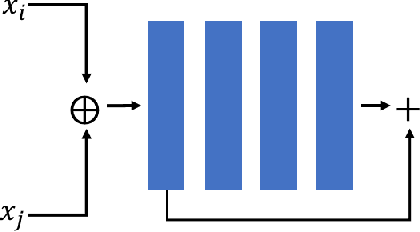
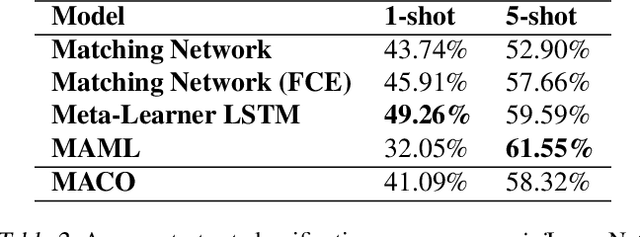
Learning high quality class representations from few examples is a key problem in metric-learning approaches to few-shot learning. To accomplish this, we introduce a novel architecture where class representations are conditioned for each few-shot trial based on a target image. We also deviate from traditional metric-learning approaches by training a network to perform comparisons between classes rather than relying on a static metric comparison. This allows the network to decide what aspects of each class are important for the comparison at hand. We find that this flexible architecture works well in practice, achieving state-of-the-art performance on the Caltech-UCSD birds fine-grained classification task.
Faster Fuzzing: Reinitialization with Deep Neural Models
Nov 08, 2017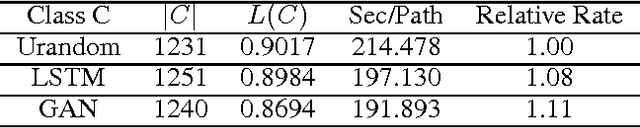


We improve the performance of the American Fuzzy Lop (AFL) fuzz testing framework by using Generative Adversarial Network (GAN) models to reinitialize the system with novel seed files. We assess performance based on the temporal rate at which we produce novel and unseen code paths. We compare this approach to seed file generation from a random draw of bytes observed in the training seed files. The code path lengths and variations were not sufficiently diverse to fully replace AFL input generation. However, augmenting native AFL with these additional code paths demonstrated improvements over AFL alone. Specifically, experiments showed the GAN was faster and more effective than the LSTM and out-performed a random augmentation strategy, as measured by the number of unique code paths discovered. GAN helps AFL discover 14.23% more code paths than the random strategy in the same amount of CPU time, finds 6.16% more unique code paths, and finds paths that are on average 13.84% longer. Using GAN shows promise as a reinitialization strategy for AFL to help the fuzzer exercise deep paths in software.
Dynamic Input Structure and Network Assembly for Few-Shot Learning
Aug 22, 2017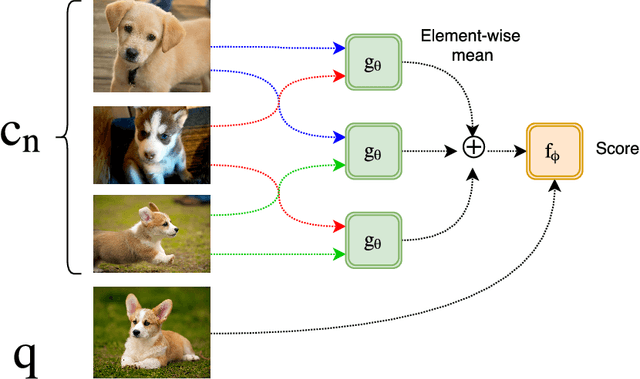
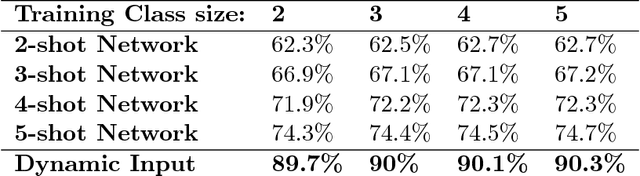
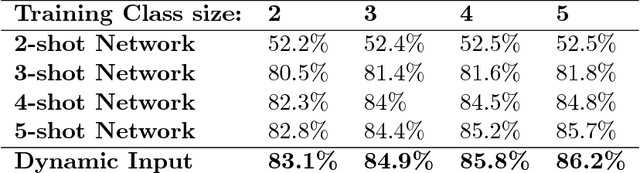
The ability to learn from a small number of examples has been a difficult problem in machine learning since its inception. While methods have succeeded with large amounts of training data, research has been underway in how to accomplish similar performance with fewer examples, known as one-shot or more generally few-shot learning. This technique has been shown to have promising performance, but in practice requires fixed-size inputs making it impractical for production systems where class sizes can vary. This impedes training and the final utility of few-shot learning systems. This paper describes an approach to constructing and training a network that can handle arbitrary example sizes dynamically as the system is used.